AI繪圖-Stable Diffusion 016- Tiled Diffusion with Tiled VAE

由於現有顯卡性能限制,想要在圖生圖裡重繪放大一張圖到4k以上的尺寸就得要借用各種分格繪圖再重拼接成大圖的方式,無法一次生成。之前試過大家很推崇的Ultimate SD upscale,但對於我要重繪放大的”真人寫實照片”類型的圖來說,一直出現各種問題(即使有Controlnet輔助,仍然是一下畫面還是有鬼影、一下死平塗抺感很重、一下又是格狀的邊緣痕跡明顯…..沒完沒了)。今天就再來測試另一個也是利用分格繪圖再拼接的重繪放大外掛工具- Tiled Diffusion and VAE。
想要把一張小圖放大像素值的同時又能保留原本圖片裡的細節,不要各種死平的塗抺感,那就只能在放大像素的同時增添相應足夠的細節上去。所以一般只是單純利用放大演算功能把圖放大,或多或少不管哪個多厲害的演算法都一樣,那種塗抺感都避不掉(細節丟失),大多都是遠看還行拉大近看就破功(特別是在”真人寫實照片”類型的圖更明顯)。
因此,要小圖放大同時又有細節在,那就只能用重繪放大的方式。所以現在我的生圖作業流程都是所有文生圖裡產出的小圖,用重繪放大畫出一張顯卡一次能畫出最大的尺寸之後,再用放大演算把圖放大2倍(2倍以下是目前我比較接受不至於把圖拉近時明顯看得出塗抹感的值)。
可是目前我的顯卡(RTX 3080, 10G),一張512×768的原圖,重繪放大不爆顯存能畫的最大尺寸差不多只能到2048×3072左右,之後再用放大演算把圖放大2倍也就只能得到4096×6144左右,4K以上8K不到。
後來有了Ultimate SD upscale分格算圖再重拼接生成大圖的重繪放大外掛出現,我就想試看看能不能就此產出更大尺寸的圖但同時保留我能接受至少該有的細節質感。
可惜試過之後,個人覺得不是很理想。在最終圖像的成果和效率上都還是不如之前的作業方式。(測試比較結果,可參考之前文章 : 連結 )
這次不死心,再拿另一個也是大家常用的Tiled Diffusion and VAE測試看看,有沒有機會在不升級顯卡的情況下,得到我要的效果(得到更大尺寸的圖,但維持該有的真實細節~不是那種假假生硬的高清放大)。
Tiled Diffusion & Tiled VAE 功能與特色
Tiled Diffusion 與 Tiled VAE各別有不同的功能作用 : (→官網地址)
- Tiled Diffusion : 本質類似於高清修復,是對圖片進行重繪的方式放大圖片尺寸。和Ultimate SD upscale一樣,它也是利用分區塊的方式重繪算圖,可解除顯卡算圖尺寸的上限值。但其中特別的一點是,每個區塊拼接的方式”Tile Overlap”,讓每個區塊(tile)部分重疊融合,這樣可以減少格狀的邊緣痕跡。如下圖官網裡的說明 :
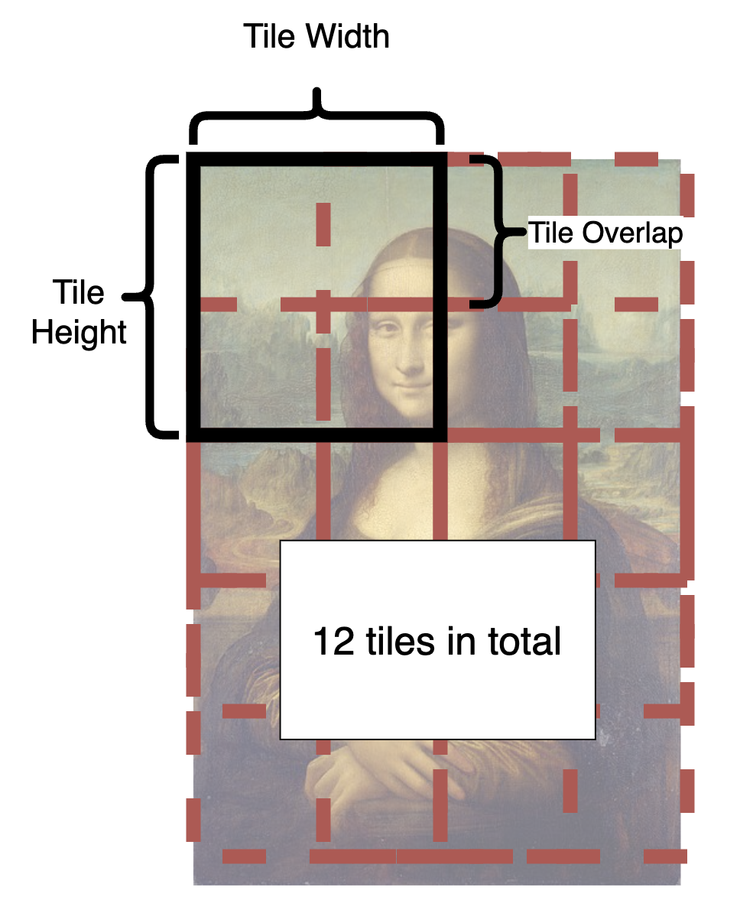
- Tiled VAE : 則是原作者獨創的演算法,能有效降低顯存的消耗。所以一般使用Tiled Diffusion生成重繪大圖時,都會建議一起搭配使用。但Tiled VAE也是可以單獨使用,用來提升顯卡原本的算力,例如在高清修復時,原本你只能放大1.5倍,但開啟Tiled VAE之後,就有可能可以提升至2倍。
Tiled Diffusion & Tiled VAE 介面參數

在安裝完外掛後,在文生圖與圖生圖的頁面下,會看到多了2個下拉選單

Tiled Diffusion
除了紅框以外的部分,Retouch 和 Renoise kernel size,我也不清楚這兩個到底是用來做什麼的,官網上也沒有針對這個有說明,就按預設狀態不要動它吧。而最下方的Region Prompt Control下拉選單,是用來對畫面分區域進行各別區域的提示詞設定。不像一般我們使用提示詞時,會針對整個畫面進影響,無法指定哪個區域要有什麼物品以及該物品的特徵描述。這個功能我是還沒去使用過,但網上已有其他很多利用這功能在文生圖裡進行提示詞分區對畫面描述控制的教學,有興趣的人可以再去找來看或是參考官網說明,這篇主要是要測試重繪放大功能的效果比較,就跳過這部分。

- Enable Tiled Diffusion : 開啟使用 Tiled Diffusion
- Keep input image size : 勾選會讓上方原本的長寬尺寸設定失效,會以圖生圖視窗內原圖的長寬尺寸為基準進行重繪放大。
- Method : 這裡有Multidiffusion 和 Mixture of Diffusers兩種可選擇。按官網說明,MultiDiffusion適合用在重繪(高清修復)、Mixture of Diffusers更適放大。我使用上覺得兩個好像效果都沒差別。我的目的是要重繪放大,所以通常都只選MultiDiffusion。
- Laten tile width & height : 這裡是決定每個區塊的大小,數值愈大,一張圖所需分的區塊就愈少,算圖速度愈快,但所佔用的顯存也愈大。預設值是96,官方作者建議使用128。
- Laten tile overlap : 是指區塊與區塊間重疊面積大小,數值愈大,接縫愈少,但算圖速度愈慢。原作者建議,使用MultiDiffusion時設定32或是48,使用Mixture of Diffusers時設定16或32。
- Laten tile batch size : 指一次算圖處理的區塊數量,數量愈多,算圖速度愈快,但也更佔顯存。
- Upscaler : 選擇放大要使用的演算法。
- Scale Factor : 放大的倍數。
- Noise Inversion : 按官網說明,開啟Noise Inversion會在生圖時進行噪聲反推,讓新生成的圖像與原圖保有更高度的一致性,以及如果覺得生成的圖像感覺有變比較模糊時,可試著提高Inversion steps、降低Renoise strength。
有使用ControlNet的Tile模型去拉高重繪幅度時,如果畫面因此細節過多變雜亂,就可以考慮打開Noise Inversion去調整兩邊的參數,找到一個所需畫面質感的平衡。
不過這個選項實際使用,會讓圖產生平滑磨皮少掉部分細節,很難找到一個剛好理想的平衡點,所以我一般選擇不太去使用它。
Tiled VAE
Tiled VAE有個很貼心的地方,它會根據每台電腦顯卡效能不同,在開啟下拉選單後,裡面最一開始的預設參數值大致就是最適合你顯卡能運行的狀態。
- Enable Tiled VAE : 開啟使用 Tiled VAE
- Encoder & Decoder Tile Size : 預設數值遇到爆顯存(Out of memory)時,再把數值向下調整即可(在不爆顯存的前提,數值是盡量愈高愈好)。
- Fast Encoder Color Fix : 當Fast Encoder勾選時才會出現的選項,勾選使用Fast Encoder算圖發現成像顏色變調時,可試開啟此選項。而Fast Encoder有沒有勾選算圖的速度實測一次也差沒多少時間,所以一般我也不會去勾選Fast Encoder,用了反而多一次顏色可能失真又要再修復(又有可能修復的不理想)的麻煩。

Tiled Diffusion & Tiled VAE 搭配ControlNet-Tile 實測重繪放大
512×768重繪放大8倍(4096×6144)
拿之前重繪放大一樣的圖來實測對比。512×768一次重繪放大8倍(4096×6144) :
denoising0.3,先不管我覺得女孩皮膚看起來氣色很差,長斑…的問題。低重繪值,一樣不夠8倍率放大所需增加的細節,髮絲開始塗成一片。然後感覺畫面糊糊矇矇,依官網建議加上Noise Inversion,但果然不出所料,就是塗抺/磨皮效果,代價換來更假假的平貼塗抺感。但以8倍重繪放大來說,是有比Ultimate SD upscale好一點,假假的塗抺感相對有下降一點點…。

denoising0.7。改用高一點重繪值,解決放大8倍細節不足夠的部分。髮絲有改善,但整張畫面中開始出現奇怪的小凹點,不只下圖所標示出來的地方,整個背景處也有。而拉高重繪幅度值後,如果想用Noise Inversion去去除一些高重繪幅度產生過度細節產生的雜亂,一樣的問題,Inversion steps、Renoise strength值不管怎樣調,要有效消除雜亂的地方和假假的磨皮感只能二選一。
但這裡放大8倍後,不像使用Ultimate SD upscale會有明顯的格狀痕跡(seams),Tiled Diffusion的”Tile Overlap”的確是有解決了seams的問題。

512×768重繪放大4倍(4096×6144)
8倍結果不理想,挑戰失敗。那先只用4倍,來看使用Tiled Diffusion with VAE的重繪放大4倍,和直接重繪放大4倍的區別。
以下面對比圖來看,這次我比較喜歡有使用Tiled Diffusion with VAE重繪(0.7)放大4倍的髮絲和皮膚紋理/膚色的處理,加上同樣0.7的重繪幅度,對人物臉部長相原樣維持統一度更好。唯一可惜的是人物衣服上和放大8倍時一樣出現奇怪凹點和面料質地也有點畫崩了。

512×768分多次低重繪幅度放大8倍(4096×6144)
最後和測試Ultimate SD upscale時一樣,也用Tiled Difussion去分次重繪放大 :
一次先放大2倍(denoising : 0.4)→丟回img2img再放大2倍(denoising : 0.4)→再丟回img2img再放大2倍(denoising : 0.1)
同樣最後達到原圖的8倍(4096×6144),最終結果要比一次放大8倍來得好很多(即使只要放大4倍,也是一次2倍、再2倍放大的效果比較好,畫面中比較不容易出現一些奇怪的小問題)。

三種重繪放大8倍(512×768 → 4096×6144 )過程的結果比較 :
各有各自的小問題(不滿意的地方)在,不過其中Ultimate SD upscale我覺得可以直接放棄不用了,Tiled Diffusion with VAE能達成一樣的分格算圖解除顯卡效能限制,且畫面中出現的小缺點也比較少,更重要的是背景放大來看不會有格狀的痕跡,唯一不如的地方大約就是Tiled Diffusion with VAE算圖相對比Ultimate SD upscale費時。
而第一張除了牛仔褲頭上的皮革貼標處沒畫好糊成一片,其它細節放大來看,都比另兩張好,少了許多”AI的筆觸/雜亂畫崩的痕跡(artifacts)”,整體細節過度得最自然(例如在下圖中注意側臉輪廓與頭髮瀏海間)。且第一張的作業流程也是最省時省事的。

Tiled Diffusion with VAE重繪放大16倍(512×768 → 9182×12288 )挑戰 :
最後再拿Tiled Diffusion with VAE去進一步把4096×6144的圖重繪放大2倍(8192×12288),看會不會崩圖~

雖然算圖費時很可觀,但絕對是可以生成超大圖片,且整體看來還算可以,沒有明顯崩圖或什麼奇怪幻覺。只是拉近放大來看,原本4096×6144大小時就有的小缺點更進一步變明顯,另外只要是淺色處的區塊,會有明顯粗糙崩壞的紋理出現。

這張原圖如果想要生成細節自然的超大圖,不怕麻煩的話,可以把前面三種重繪放大方式比較中的第一張(在8倍大小時,小缺點最少,細節放大也最細緻自然),和其它張稍微用PS合成修補一下,取長補短,之後再利用Tiled Diffusion with VAE來進一步重繪放大2倍,就可以生成更理想的超大圖(8192×12288)。
目前為止在使用分格重繪放大時,我們都固定會需要去選擇一個Upscaler(放大演算法)來使用,我這邊用的是常見的4x_Ultrasharp,但網上還有另一個外掛(StableSR),號稱Tiled Diffusion with VAE搭配這個外掛的放大演算法使用,效果會比原本使用4x_Ultrasharp好。看網上有人說細節有比較好,也有人說覺得還好差不多,這部分我還沒去實測過,之後有空再來試看看,感興趣想了解的人,可以先到外掛的官網去看說明 :
→ https://github.com/pkuliyi2015/sd-webui-stablesr

你可能也想看





















