給讀者的話:
這是十分鐘簡讀版,付費訂閱之後,便可閱讀本文更詳進的內容。
回顧 2018
在 2018 年,筆者介紹了普華永道(PwC)關於人工智慧的十項預測。這十項預測可以歸納為四個大項,分別為:
- 解釋深度學習和人工智慧 (Deep learning theory & Explainable AI)
- 模型不確定性和遷移學習(Model uncertainly & Transfer learning)
- 深度強化學習(Deep reinforcement learning)
- 膠囊網路和機率程式架構(Capsule networks & Probabilistic programming)
現在我們就來回顧一下,過去一年中,人工智慧的發展是否與當時 PwC 的預測相符合。
過去的一年中,機械學習演算法逐漸成為人們日常生活的一部分,許多議題被予以討論,甚至立法約束。
議題包括了在物件偵測和語言模型上,出現不可避免的偏見,如對特定種族或性別的偏好。這些偏見反映真實社會的現象,卻讓人工智慧是否能對社會整體產生正面效益產生懷疑。
至於物聯網的部分,2018 年我們歡迎智慧助理進駐家庭中成為家中的一份子。
雖然這個智慧助理還尚未能判別冰箱中哪些日常所需已用罄,並直接下單訂購,透過排程和最短路徑計算後,讓機械人遞送至住所。但,至少他們可以為你報新聞,甚至幫你預約理髮和牙醫約診「註一」。
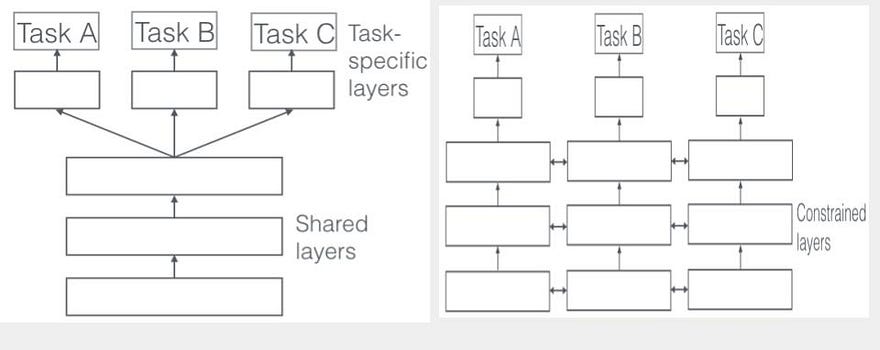
多領域訓練(Multi-modal training)和遷移學習(Transfer learning) 在過去一年,被廣泛應用,進而使以深度學習為主要推力的人工智慧,有了卓越的進步。
而這兩個技術的發展,則讓兩個長久在人工智慧領域各自獨立發展,自然語言與電腦視覺,開始結合,並導致更近似於人類理解能力,足以辨識語義的結合應用。
接下來,我們將要針對電腦視覺和自然語言這兩個領域的進展,做比較詳細的回顧。
電腦視覺
在過去電腦視覺的發展中,物體識別與偵測在研究領域中獲得相當卓越的進展,包括了高準確率和精準度,甚至在不大幅降低準確度的情況下,進行即時的物體偵測。
然而,電腦視覺在研究領域的進展似乎對實際的應用並無如虎添翼般的助益。相對地,我們在去年三月聽到第一起由 Uber 研發的自駕車的意外,在這起意外中,很不幸地造成了一名中年婦人的死亡。
而 Waymo 則在六月,因為人類駕駛未能警覺取得控制,而”貢獻”了另外一起自駕車意外,說明了目前的自駕軟體尚未能完全取代人類,成為完全值得信賴的駕車夥伴。
為了能更近一步探索類神經網路進行特徵工程的能力,便是借助於合成影像。
合成影像(Synthetic Data)
使用合成影像中,可以解決:
訓練資料的取樣誤差問題。誠如 PwC 2018 趨勢預測一文所述,類神經網路是對於訓練資料有強依賴性的演算法。透過合成影像,在物體偵測的任務中,可以建構擾動的環境燈光和低品質的訓練影像,進而縮小在真實世界中,因為環境和攝影器材的硬體限制,造成無法被模型解釋的隨機誤差。
除了上述問題外,合成影像亦可以達到像素層級的標注精準。像素層級的標注精準有助於目前發展的全景分割技術。
其次,則是配合 Merged Reality (MR) 應用發展出的 3D 合成影像。MR 是結合 Virtual Reality (VR)和擴增實境(Augmented Reality, AR) 兩種技術,而提出的新型應用,主要是希望藉由 AR 擴增使用者所處的真實環境,並讓使用者透過 VR 來經驗視覺探索。
除了仰賴合成資料,另外在 PwC 2018 趨勢預測一文中也指出,可以利用對抗生成網路(GAN)來產生和真實影像相近但帶有雜訊的影像。
對抗生成網路(GAN)
在過去一年中,GAN 不僅在架構上獲得改進,並結合其他技術來達成廣泛的應用。
最後,則是如 PwC 2018 趨勢預測一文指出,可以利用遷移學習來完成解決標注不足的問題。然而遷移學習的最大限制即是在於來源和目標領域(domain)的資料分布不可相差太遠,不然會產生 Domain Shift 的問題。
跨領域對映(Domain Adaptation)
關於 Domain Shift 問題,解決方案則是試著找到來源和目標領域的映射關係,稱為 Domain Adaptation 的研究。
接下來,我們要把注意力轉至自然語言領域中,雖然是全然不同的資料型態,但我們可以發現和電腦視覺相似的趨勢也可在自然語言領域中發覺。
自然語言
自然語言在過去的一年則獲得跳躍式的進展。如 OpenAI 的創辦人 Rachel Thomas 所指出,
2018 年對於自然語言,是進入電腦視覺中 ImageNet 的時代。
然而,如同電腦視覺目前面臨的挑戰,為了解決機械翻譯中部分語言所蒐集到的訓練資料不足的問題(該種語言多被稱為低資源語言),遷移學習廣泛地應用於自然語言中。相同的, Domain Adaptation 也企圖在序列型資料中找到一席之地。而目前的方法有利用半監督學習或非監督的方式來解決標注不足的問題。
無全監督學習(Not Supervised Learning)
在半監督學習(semi-supervised)的方法中,主要是利用已標注的訓練資料來學習未標注的訓練資料。另外一個趨勢則是利用應用於多任務(multi-tasking)學習中的 meta-learning 來解決。
表徵學習(Representation Learning)
在過去一年,令人側目的則是 contextualized-based word embedding 的發展,包括了 ELMo, ULMFiT 和 google 的 BERT。
歸納偏見(Inductive bias)
Inductive bias 是藉由先驗知識或普通常識來對模型做額外的假設,增加對未曾見過的測試例子的準確度,並能使用更少的實例來做訓練。常見的引入 inductive bias 是藉由多任務訓練,來迫使演算法偏好找尋能同時解釋多個任務的模型參數。
最後,為了改善 Attention 機制,也可引入 Inductive bias。
展望 2019
2019,PwC 認為是 AIaaS (Artificial Intelligence as a Service) 技術成熟並進入商業運轉的一年。PwC 在今年的趨勢預測文章中,為已挹注資金研發 AIaaS 的公司,提出了六條優先自我檢查的項目。
這六個項目,分別簡述如下:
組織重構以確保明確的人工智慧商業策略(Structure: Organize for ROI and momentum):在此項中,PwC 建議擁有單一的資訊平台以整合不同 AI 團隊的努力,並專注於打造可跨不同組織,並可重複利用的 AI 解決方案。
建立一個同時能讓人工智慧專家和非專家共同合作的團隊(Workforce: Teach AI citizens and specialists to work together):此項中,則延續去年的人工智慧平民化(democratizing AI),鑑於許多自動化人工智慧模型訓練的演算法興起,如 AutoML。
一個混合型的團隊,包括關注人工智慧產品介面使用者(citizen users),具有商業背景能解析 AI 結果的開發者(citizen developers)和真正的人工智慧專家,如資料科學家(specialists)等。藉由適當分工,緊密合作,驅動 AIaaS 順利運轉。
專注於人工智慧模型透明化(Trust: Make AI responsible in all its dimensions):在此項中,延續了 2018 關於 Explainable AI 的預測,但增加了人工智慧應用的道德限制,包括了:如何移除資料中的偏差,如何確保人工智慧模型的安全性等等。
如何正確且合法的取得個人資料做模型訓練(Data: Locate and label to teach the machines):如何取得與欲解決的商業問題相關的訓練資料,或運用遷移學習(transfer learning)等現有已訓練模型,迴避手動標注大量資料的問題。
而在 2018 年分別在歐美二地通過的 GDPR 和 CCPA,將會對資料的取得方法做更嚴格的規範。
專注於個人化與高品質的人工智慧產品(Reinvention: Monetize AI through personalization and higher quality):此項中包括使用人工智慧模型作為決策系統,以及藉由發展個人客製化的商業模式找到市場。
合併人工智慧於不同的技術中(Convergence: Combine AI with analytics, the IoT, and more):許多傳統產業將需要人工智慧來為第四次工業革命做轉型準備。包括了 IoT(物聯網),以及透過物聯網產生的新型資料的分析。最後藉由 DevOps 對 AIaaS 提供不間斷最佳的服務品質。
有了 PwC 六項建議,接下來我們針對快速發展的 Automate Data Science & AutoML 領域,來勾勒 2019 年的簡要藍圖。
Automate Data Science & AutoML
“Python Machine Learning” 一書作者,Sebastian Raschka 曾說
電腦程式是關於如何自動化,而機械學習則是關於如何自動自動化。(“computer programming is about automation, and machine learning is "all about automating automation.”)
然而,因為調整模型的過程繁複瑣碎,而使自動化機械學習,亦簡稱為 AutoML,成為一門學習自動化的學問 ("the automation of automating automation."),而該學問的最終成果便是發展一個能夠自行最佳化學習過程的演算法。
最後,以一張圖來總結目前 AutoML 領域中所面臨的困難。這些困難包括了將 AutoML 應用到 online-training 的模型和資料型態的多變異性。

註釋:
[1] 見 Google CEO Sundar Pichai 在 Google I/O 2018 keynote 演講
延伸閱讀:
- KDNuggets “The Data Science Process, Rediscovered” (英): 2016 年的文章主要定義不同的資料科學流程。
- KDNuggets ”Building AI to Build AI: The Project That Won the NeurIPS AutoML Challenge“ (英): 由 2018 年 NeurIPs AutoML 競賽中獲獎的隊伍,Flytxt ,提到目前 AutoML 所面臨的挑戰和困難。