今天來分享在建置完K8S後的基本工作之一 : 監控。
只要是任何會”運作”的物件(Object),不管平台、服務、軟體、硬體,為了要提供最高的可用性,就會需要透過大大小小的監控元件來幫助我們了解所有的狀態,以便在問題發生時能做到最快速的反應。
如果做的更好,甚至可以在問題還沒發生之前提早預料到接下來可能會發生什麼事,在問題未發生前就提早解決問題。本文針對在K8S平台上的監控方案Loki與大家分享一些基本概念。
一如往常,以下是本文將說明的部分:
- Loki的基本概念
- PLG stack
- 部署模式
- 結論
- 結論
1.Loki 的基本概念

Grafana Loki
過往在Kubernetes架構之下,通常會建立以ElasticSearch為主的EFK stack架構,但這個架構雖然功能完整,但對於一些規模較小的K8S cluster環境,如果使用了EFK stack反而會提高資源與管理上的複雜度,此時就可以選擇以Grafana Loki為主的另一種K8S監控方案。
相對於EFK,Loki也是從Prometheus方案所沿伸出來,並且也具備高可用性、水平擴展的功能,更重要的是相對於ElasticSearch,它不會去索引整個日誌的內容,而是為每個日誌提供一組標籤,如此一來就變的更輕量化、所需求的資源也就比傳統EFK stack來的更少。
Loki相對於其他的監控方案的不同如下:
- 不會去索引整個日誌的內容,將已壓縮後的非結構化日誌進行儲存並只對metadata做索引,因此運行更輕量也更便宜
- 使用原本在Prometheus就在使用的index、label,實現無縫轉移
- 特別適合儲存K8S Pod log
- Grafana v6.0之後原生支援
2.PLG stack
所謂的PLG stack指的是以下三個專案的組合:
- P : Promtail
- L : Loki
- G : Grafana
簡單來說,這三個元件是用以下圖方式運行:
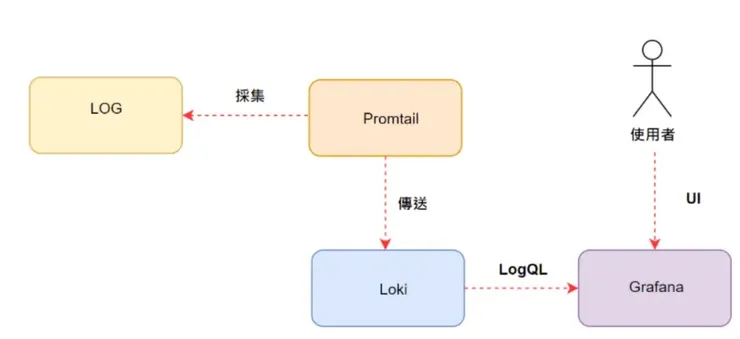
針對這三個元件的功能分述如下:
- Promtail : 等同於EFK的”Filebeat/Fluentd”,負責採集Log然後發送至Loki.
- Loki : 等同於ElasticSearch,用來儲存Logs與處理查詢
- Grafana : UI 介面
由Promtail將日誌採集之後, 傳送至主元件(Loki),Loki則可用LogQL將查詢直接轉換成Prometheus metrics,使其在Grafana UI上呈現給使用者進行查詢操作。
3. 部署模式
有以下幾種常見的部署模式:
(1) Monolithic(All-in-One) : 所有的元件都在一個容器內運行,通常是測試與小規模。在一個Process內運行所有的元件。所有元件只透過Localhost進行元件之間的溝通(grpc),一般可以用Helm來進行部署。(建議:每日不超過100GB適用)
(2) Simple scalable mode(Simple HA) : 部署在多個read/write的複本節點(建議:每日幾TB適用)
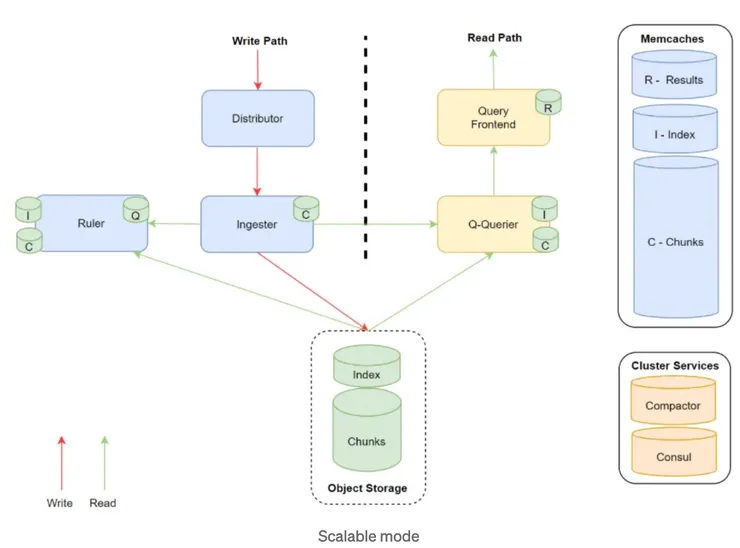
簡單說明:
- Read node : 如上圖”Read Path”,負責回應Log查詢
- Write node : 如上圖”Write Path”,負責儲存Log與後端的索引
- Gateway node : nginx-based的LB,在Loki之前負責將
push流量導至write node,其他流量導至read node(Round robin)
(3) Microservices : 每個元件都可以容器的方式獨立運行。(建議:適合非常大的規模),適合與Kubernetes部署一起使用,將元件全部拆開各自獨立運作。
目前如果要在正式環境下建置時,建議使用Simple scalable mode或是Microservices模式較佳。
4.結論
原本我在建置完K8S平台後,通常是採用EFK stack,一步步將整個監控部署在整個平台上,但常常就是到最後花了很多心力進行相關的部署與調整工作,更別提最後還要建置出合適的Dashboard(儀表板)才算告一段落,同時也因為傳統的EFK架構所需資源較高,在規劃時就必須要針對EFK保留更多的系統資源。
Loki為基礎的PLG Stack方案提供給我另一個更好的選擇,我可以在測試環境以Standalone模式建置出整套系統,並且在正式環境下還可以有更具擴展性的方式可供選擇,對於管理人員來說除了部署相對簡單之外,更有幫助的是還具備了輕量、彈性的好處。
針對監控部分個人希望可以有更加深入的了解,在學習的過程中也將盡可能的分享給大家,敬請期待後續的分享。
請大家給我鼓勵,你的鼓勵可以讓我更有動力分享。
References:






















