通常我們如果希望一筆資料是能夠具備唯一性的狀況下, 勢必在新增前會進行檢查, 但是在我們的應用程式中, 先查詢再寫入勢必會造成一些時間差, 導致於多人同時操作時, 可能發生重複資料的狀況。
假設我們的應用是不允許名稱重複, 那我們的資料可能如下:
[我們的業務邏輯為「當名稱存在時就更新、不存在就新增」,此時我們可能會分成兩個動作來操作:
{
"name": "john",
"phone": "0911111111"
},
{
"name": "mark",
"phone": "0922222222"
}
]
- 查詢 name = xxx。
- 存在: Update、不存在: Insert。
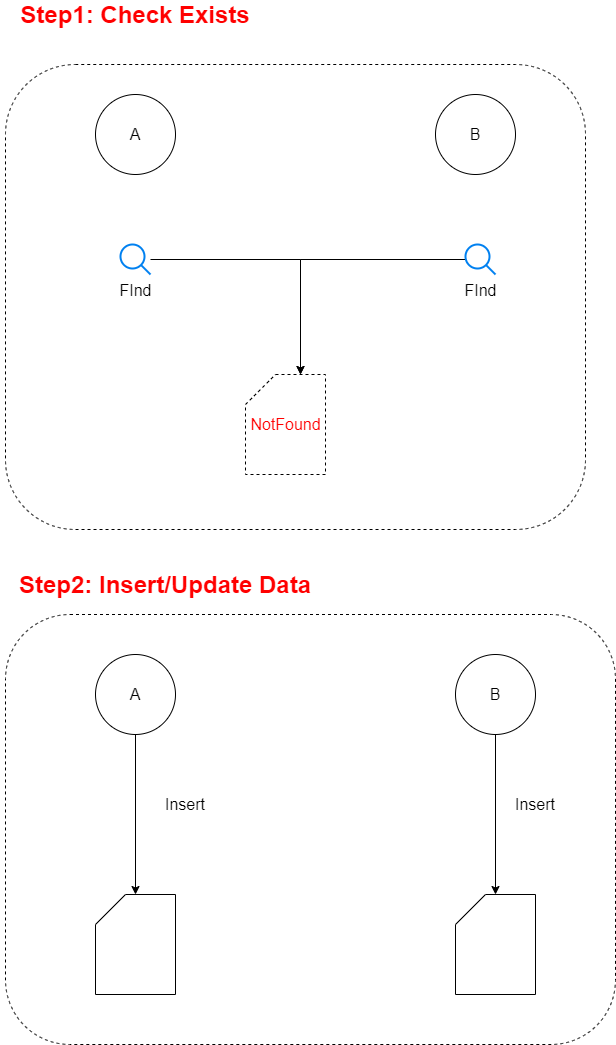
上述狀況在同一時間內只有一個操作都不會發生問題, 但假設同一個時間點有兩個人同時操作時, 就可能發生以下狀況:
而為了解決上述問題, 我們可以把「查詢/新增/更新」這個動作視為一個單元, 提交給DB去幫我們操作, 也就是透過Upsert的指令來幫我們完成。
但實測後發現在高併發的狀況下, 雖然重複資料的狀況減少了, 但仍然會發生, 若要完全避免這樣的況狀發生, 根據官方的描述:
「To avoid multiple upserts, ensure that the filter field(s) are uniquely indexed. 」(https://docs.mongodb.com/manual/reference/method/db.collection.updateOne/)
要解決這個問題, 我們可以透過「唯一索引」的方式來建立, 以上面的例子來說, 我們的name,就是這個文檔的唯一性關鍵, 因此我們可以對name進行建立Unique索引:
db.collection.createIndex( { "name": 1 }, { unique: true } )會解決以下兩個問題:
- 只要欲更新/新增的name會有重複的狀況發生時, 就會被DB Reject。
- 併發的狀況下, 假設同時有兩個一模一樣的upsert在同時間操作, 如下:
db.collection.update(
{
"name": "Ada"
},
{
"$set": {
"name": "Ada", "phone": "0933333333"
}
}
)db.collection.update(
{
"name": "Ada"
},
{
"$set": {
"name": "Ada", "phone": "0933333333"
}
}
)