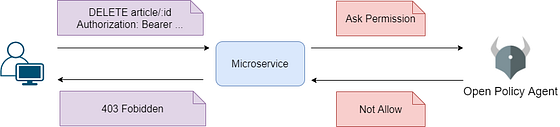
上一篇我們介紹了「【認證與授權】Open Policy Agent 授權策略」, 相信都已經初步了解了OPA(Open Policy Agent)主要在做什麼, OPA簡單來說就是一個授權的政策管理規範, 有點像我們的法律系統, 提供開發者在上面制定法條, 以約束授權對象可以進行什麼樣的操作, 讓各語言各自實作的授權政策有了統一的規範, 並獨立成一個模組區塊, 目的是讓越趨複雜的系統可以專注於功能, 而各類授權政策則獨立開發、測試, 讓職責分明, 問題追朔更加容易。

既然OPA是一種授權的政策管理規範, 就像法律一般也一定會有法條的組成, 而在OPA的世界裡, 組成法條的就是Rego這個語言, 專門用於描述和評估政策規則, 提供了靈活的工具,開發人員可以使用這些工具來編寫、測試和調試政策規則, 這次就來介紹一下Rego這套語言究竟與我們傳統的程式語言有什麼不同吧!
簡介
Rego這個語言的發展主要受到Datalog的啟發, Datalog是一種數據查詢語言, 這種語言有很強的知識推理能力,本質上都是為了解一個邏輯問題, Datalog已經具有數十年歷史的查詢語言, 但Rego並非完全遵循Datalog的語法, 而是以支持JSON格式的方式, 更貼近於現代化的撰寫方式。為什麼要使用Rego語法?
- 以宣告式寫法精簡程式碼,什麼是宣告式呢? 請參考「【程式設計基礎知識】宣告式 V.S 指令式」。
- 不需要太複雜的邏輯, 只需要制定授權的策略即可。
- Data的描述以JSON形式表達。
- OPA根據Rego的表達規則進行索引運算, 提升效能, 詳細的演算法內容請參考: https://blog.openpolicyagent.org/optimizing-opa-rule-indexing-59f03f17caf3。
- 對於制定的策略可以進行單元測試。
- 可以進行Benchmark,優化我們的策略判斷。
總而言之,Rego是OPA的政策語言,用於描述和評估政策規則,它提供了一種結構化和可讀性高的方式來定義政策,並與OPA引擎緊密集成,實現細粒度的存取控制和政策管理。
初步認識一下Rego
語法結構
- 相同的規則檢查名稱, 其中一組符合就通過檢查。
- 規則檢查區塊中的每一條表達式都是And的關係。
default 規則檢查名稱 = 預設值
規則檢查名稱 {
表達式
表達式
...
}
規則檢查名稱 {
...
}
預設規則的回傳值
以下會預設allow未滿足判斷條件時, allow會等於false。
default allow = false
allow {
x := 42
y := 41
x < y
}
// return false
但假設沒有預設值, 就會回傳undefined。
allow {
x := 42
y := 41
x < y
}
// return undefine
多條表達式之間都是And關係, 順序性影響不大
正常撰寫表達式如下:
t2 {
x := 42
y := 41
x > y
}
expression-1 AND expression-2 AND ... AND expression-N
替換順序, 結果仍然正確, 因此我們在寫決策時, 也可以先把期望的判斷寫好, 在補上需要的Data:
t2 {
x > y
x = 42
y = 41
}
否定語句使用 not 關鍵字
t {
greeting := "hello"
not greeting == "goodbye"
}
// reult true
Function結構
我們撰寫程式時, 常常需要把重複的功能獨立成Function, 而rego語法也提供了Function的功能結構如下:
<function_name>(<params>...) = <return_value_variable> {
<expression-N>...
}
trim_and_split(s) = x {
t := trim(s, " ")
x := split(t, ".")
}
Else關鍵字
authorize = "allow" {
input.user == "superuser" # allow 'superuser' to perform any operation.
} else = "deny" {
input.path[0] == "admin" # disallow 'admin' operations...
input.source_network == "external" # from external networks.
} # ... more rules
結語
不論我們今天是否使用Rego這個語言, 重要的是其中的設計精髓, 以宣告式設計來表述一件工作或者事物, 讓我們專注於設計最終結果, 以終為始, 逐步填充過程。
喜歡撰寫文章的你,不妨來了解一下:
Web3.0時代下為創作者、閱讀者打造的專屬共贏平台 — 為什麼要加入?
歡迎加入一起練習寫作,賺取知識!