
在掌握Stable Diffusion文生圖的使用技巧幫助我們利用文字描述的組合/變化去生成所需的圖片內容後,再更進一步,我們也許會想要針對一張已經百分之七、八十符合我們需求的圖去進行部分內容的修改或是整體畫風的轉換。這時就需要有個”圖生圖 img2img”的操作介面讓我們能和Stable Diffusion溝通,告訴它我想要在特定某張圖片的基礎上做什麼變化。
圖生圖的介面和文生圖大致上都很相似,大部分的參數功能設定也都和文生圖一樣,先簡化來看就只是在文生圖的基礎上多加了一個可以放進一張圖片的窗口,讓Stable Diffusion除了讀取你給的文字描述、參數值資訊外,另外多了參考圖片可做為出圖的生成依據。

Interrogate CLIP & Interrogate DeepBooru
- CLIP反推提示詞 : 對圖生圖窗口裡的圖像進行”完整句型”的描述。ex. a girl sitting on a chair
- DeepBooru反推提示詞 : 對圖生圖窗口裡的圖像進行”單詞型”的描述。ex. a girl, sitting, chair
- CLIP反推提示詞能比較清楚描述畫面中物件與物件間的關係,較實用。
- DeepBooru反推提示詞能產出的單詞量相對貧乏不夠仔細,如果想反推出單詞的話推薦改用”Tagger”這個外掛來取代會比較精準一些。
- 第一次使用CLIP和DeepBooru反推提示詞功能時,程式會需要先下載相關模型資料,通常要等待比較久的時間是正常的。這次下載完成,之後再使用時就不用等這麼久了。
(PS. 如果運行下載模型過程中不小心中斷/下載失敗,可以直接從網上下載後,放進下圖執行視窗所提示的路徑裡。


縮放模式(Resize mode)

- Just resize (拉伸)
512*768的原圖,圖生圖重繪生成768*768

- Crop and resize (裁剪)
512*768的原圖,圖生圖重繪生成512*512

- Resize and fill (填充) : 適合用在對圖像背景畫面延伸重繪生成,需搭配高一點重繪幅度(Denoising strength)值使用,如果重繪幅度為0或過低時只會對邊緣像素作拉伸。
512*768的原圖,圖生圖重繪生成768*768

- Just resize(Laten upscale) 直接縮放(放大潛變量) : 在0或低重繪幅度時和Just resize(拉伸)很像,只是生成的畫面會變模糊。 需要搭配高一點重繪幅度值來使用,它會對拉伸後的圖片內人物/背景所佔的區域,重新添加細節生成新圖。
如下圖所示,Denoising為0時僅畫面拉伸+變糊,接著往上提高Denoising,開始針對拉伸後的區域比例重新生成繪制人物和背景。Denoising到了約0.5時畫面變清晰,0.7以上畫面清晰以外,人物和背景的比例又開始恢復成原圖該有的樣子,最終和Resize and fill 在高重繪幅度時一樣,能擴展生成新的背景。
512*768的原圖,圖生圖重繪生成768*768

圖生圖全圖重繪(img2img)
這裡的參數值設定和文生圖裡幾乎一樣,就不再重複介紹,下面我們直接用實際狀況案例來看我們能利用這一區的功能做些什麼。
案例一、這張512*512女孩人像圖,我想在這張基礎上多變化出差不多主題內容/構圖比例的圖來參考/使用。

只設定一個Denoising來看不同變化。(還可再搭配參數裡其它設定/換不同的模型來交錯生成更多不同的新圖出來)

prompt裡的”a girl”,改成”a man”

(PS. 這裡生成圖像的尺寸如果按比例設定放大,就等於是之前我們在文生圖裡所使用的Hires.fix(高清修復)是一樣的作用。放大畫面尺寸,多增加更多的像素/噪點,讓SD有更大的空間作畫,也就能把原圖畫面中的每個細節畫得更細緻。)

案例二、同樣是案例一的原圖,我想把這張三次元的真人女孩轉畫成二次元動畫風格的圖。這裡只把checkpoint換成專畫動畫風格的模型。再來看不同重繪幅度下的變化。

在Denoising0.8以上才比較達到我心目中要轉換的風格程度(2D 卡通的畫風),但是過高的Denoising數值,又會讓新圖整個失去了原圖人物的特徵/穿著不一樣。我如果想要保有原圖人物主要的輪廓特徵(不要這麼卡通圓臉)/衣服穿著不改變,就需要搭配外掛擴充來達到目的。ex. ControlNet的Canny,在SD成像過程中去限制輪廓線範圍…等,又或是找到有訓練這類轉換畫風的Lora輔助模型等….方式。
局部重繪(Inpaint)
前面img2img裡,會針對全圖進行重繪,想要新加入的元素效果顯現出來的話就要一定程度拉高重繪幅度,可一旦重繪幅度拉高,那麼難免整張圖除了想改變的元素以外,或多或少都會產生變化。
如下圖,如果我想讓照片中的女孩戴上太陽眼鏡,但其它地方保持原樣不變時,這時就可以改用Inpaint局部重繪的方式來進行。
將戴上太陽眼鏡的地方大約畫出一個範圍(塗黑),窗口右上方可設定筆刷大小。Prompt的地方只需針對塗黑區域(Mask)裡的內容物進行描寫即可。
(PS. 在圖生圖底下的提示詞欄位是要描寫你想要SD生成新圖的內容,而不是描寫原圖。但如果只是要進行重繪放大/高清修復,只用低重繪幅度去稍微增加畫面細節/精緻度,並不想有太大的內容元素/構圖改變時,Prompt欄放原圖的描寫或是全空白皆可。)

接著來看一下局部重繪裡一些前面沒有出現過的參數項目:

- Mask blur : 跟Photoshop裡”羽化邊緣”一樣的意思,數值愈大,Mask與原圖交界處羽化範圍愈大。當發現重繪內容與原圖間的過渡不自然時,試著拉大Mask blur數值,但數值過高時也會造成Mask裡可重繪圖的區堆範圍變小(可再把Mask的範圍往外塗抹擴大調整)。
- Mask mode : 是要重繪Mask區域還是Mask以外的區域。
- Masked content : 這裡是要告訴Stable Diffusion,這個塗黑的Mask區域,一開始要根據什麼來逐步去噪重繪生成圖像。是原圖、Mask區域裡像素的顏色混合、還是亂數噪點…?如下圖所示:
(PS. 大多時後都是用original或fill為主就行。)
(PS. 這裡當我們把Denoising拉到很低近0時,我們就可以很清楚的看到,最初一開始SD在Mask裡加了什麼東西上去,以及後續Denoising拉高過程中它是如何去噪演變畫出圖像來的。)

fill:

original:

laten noise:

laten nothing:

從上面的比較圖可看出,不管是選擇哪一種的Mask content,Denoising數值過低(還來不及去噪完成),或是過高(畫面崩壞走鐘)都不適合,實際哪一個數值最剛好,就依照所選的Mask content去決定。選擇一般最常用的original時,Denoising一開始先設0.4~0.6之間大致上相對保險能產出正常的結果來。
- Inpaint area : Whole picture(全圖),是指底下設置圖像長寬尺寸的像素按區域範圍比例分配給Mask區域。如果是Only masked,則是指所有像素集中給Mask區域(分到更密集/更多的噪點,相對可畫出更多細節/畫面更細緻)。但這裡也不是愈密集的噪點就愈好,還是要看整體畫面的協調/自然度,或是你對畫面重點主題的安排。又或者有時密度太過高時,反而會出現奇怪的幻覺/崎形圖,ex. 出現臉中臉….Mask區域不是單加上太陽眼鏡,而是把戴著太陽眼鏡的全臉都給塞進來了。

這裡大家再重複加強回憶一下之前文生圖裡提到的Hires. fix. ,當生成512*512的圖出現人臉崩壞時,勾選打開高清修復放大倍數(假設512*512→1024*1024)就能把崩壞的人臉修復成美美的臉,是因為放大解析度同時也按比例增加臉部區域裡的像素密度,SD就有更大的作畫空間去把臉仔細畫好。
不過文生圖裡高清修復放大倍數只能Whole picture 512*512→Whole picture 1024*1024去分配這裡的像素密集度,但局部重繪介面下則能有更多的選擇方式(Only masked)搭配操控指定區域的像素密度。
而比起Whole picture, 使用Only masked的另一個好處就是較不易爆顯存,即便最後只是生成一張512*512的圖,不需去放大整張的解析度,同樣也能增加要修復區域的像素密度達到修復的效果。所以平時在文生圖階段時我很少去用高清修復,文生圖處只需快速算出大量小圖符合構圖主題就行,部分區域崩壞的修正或增添細節精緻度的作業放到圖生圖/局部重繪再進行,能掌握得更精準有效率。
PS.
不同Inapint area的選擇對出圖尺寸大小的影響(當原圖是512*512):
Whole picture : 新生成圖的長寬會和設定值一樣。ex. 長寬設定512*256會壓縮變型,設定1024*1024會產出1024*1024的大圖。
Only masked : 新生成圖的長寬永遠與原圖尺寸一樣。ex. 長寬設定512*256不會縮小壓縮變型,設定1024*1024也不會產出1024*1024的大圖。
- Only masked padding, pixels : 這個參數的設定是用來搭配Inpaint area裡的”Only masked”,以進一步調整Mask區域裡的像素密度。數值越高,Masked區裡的像素密度就會變越低。直接看下圖對比就清楚它的作用了 :

塗鴉(Sketch)
這區的功能就是幫助不會畫圖的手殘黨重新找回自信心的地方(這裡的所有參數項目和img2img完全一樣,就不重複說明了)。直接來看下圖範例 :



有空可以把家裡小孩的塗鴉畫丟進來玩玩,見證化腐朽為神奇的過程。
局部重繪塗鴉(Inpaint Sketch)
單看名稱就知道,這裡就是”局部重繪”+”塗鴉”的綜合功能。所參數值的項目和局部重繪都一樣,只是多增加了一個”Mask transparency”,用來控制Mask的透明度,數值愈高Mask愈透明。但注意這個數值不能拉到100,拉到100就代表這個局部重繪的Mask是全透明,SD會顯示錯誤(SD看不到塗抹Mask的地方,它會不知道你要重畫哪裡?)
如下圖,我想在小女孩的衣服上左右各別添加紅色及紫色的蝴蝶結。如果是在局部重繪區,只塗上黑色Mask,其它蝴蝶結顏色以及分別哪個要在右、哪個要在左的設定,單靠Prmopt裡進行文字描述,生成的結果通常不會這麼精準理想,可能一下出現顏色混合(同一個蝴蝶結上有紫色也有紅色)、一下又是各顏色所在位置不是你想要的。
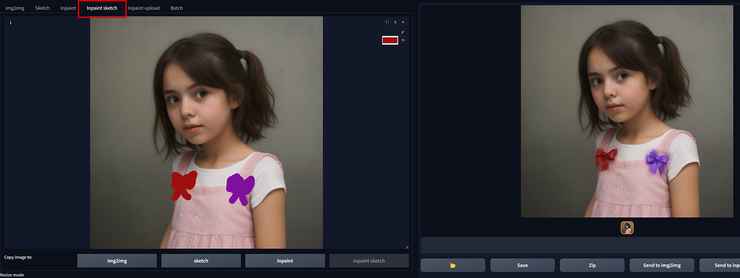
不同Mask transparency數值,最終所產生出的局部重繪效果。拉到90時(Mask快接近全透明),SD差不多就是直接忽略這裡的Mask區域,同樣的Denoising重繪幅度下,也不會對畫面產生重繪效果。

局部重繪蒙版上傳(Inpaint Upload)
當在使用Inpaint裡的筆刷+滑鼠來塗畫Mask區的時後通常不是這麼好用/好畫,很常會畫歪或是塗抹的Mask區不夠精確。這時就會想到,如果是用Photoshop的快速選取等工具來製作Mask的話就更有效率&精準多了。於是SD介面裡就又有了這個Inpaint Upload。讓你可以將在外部使用其它軟體製作好的Mask蒙版上傳到SD裡。
這裡唯一要注意的地方就是,在Inpaint裡,要Mask的地方是塗成黑色,但在Inpaint Upload裡則是反過來,黑色是not Mask,白色才是Mask。

Inpaint Masked,同一位女孩換穿不同衣服 : red dress → blue dress

Inpaint not masked,同樣red dress換不同模特來穿 : a girl in red dress → (a man:1.4) in red dress

批量作業(Batch)
當你有n多張圖需要進行img2img的時後,就可透過批量作業來完成。ex. 假設我有100張女孩穿紅色洋裝的圖片,想要全部統一換成藍色洋裝時,就可透過Batch來做批量處理,不用自己一張張在電腦前操作等算圖。
(PS. 批量作業要進行局部重繪的參數設定,要直接到Inpaint upload處設定好所有參數,之後再回到Batch頁面,按下Generate開始批量生成圖片。Batch頁面底下並沒有Inpaint裡Mask相關的參數可設定)

圖生圖相關的介紹就到這裡結束,這裡介面看起來雖然比文生圖多了更多的功能選單、參數欄位,但其實只要搞清楚每一項功能存在的目的,底下所有相對應的參數設置起來就不會毫無頭緖。
不管是文生圖還是圖生圖,都先把所有基礎的功能、運作邏輯關係理清楚,當後面再加入更多、更雜的外掛進來時也就不會茫然不知從何下手去搭配原本的功能來達成你要的目的。





















