前言
這一篇要來敘述Stable Diffusion的Automatic1111的圖生圖(img2img,簡稱i2i)功能。
在圖生圖的頁面上,大部分的功能跟文生圖的功能一樣,請直接查閱 Stable Diffusion基礎 -- 文生圖(txt2img) ,這邊就不復述了。這邊來討論不一樣的功能: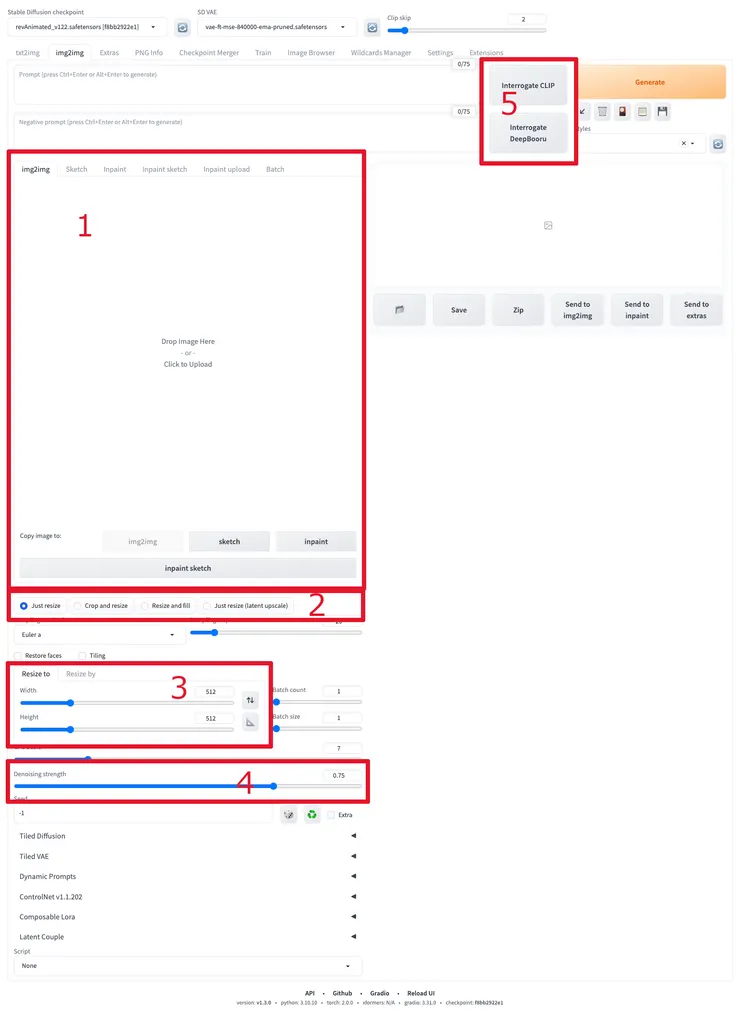
這邊最重要的功能是1(圖片放置區)跟4(Denoising strength)。我們之後會常常用到。
功能分區
- 圖片放置區:這個區域我們有三個重要的次要區域在這邊,
第一個是分頁標籤,裡面有圖生圖(img2img),塗鴉(sketch),局部修改(inpaint)等等,我們這邊主要聚焦於圖生圖這功能。
第二區是圖片放置區,在這裡我們可以用拖曳或者點擊打開檔案選擇器,把自己要修改的圖放入。
第三區是拷貝圖片到其他區域,在這邊我們可以把同一張圖自由切換到不同功能去,例如你用img2img載入圖片,突然發現其實你要的只是局部修改某個區域,就可以直接按Copy image to Inpaint把圖直接送進inpaint分頁來修改。 - 尺寸變動選項:當你的輸出尺寸設定與原先圖片尺寸不一致時,Automatic1111就會依照這邊選取的選項來調整畫面:
Just resize:無視比例,直接把圖片縮放成目標尺寸(原圖內容無損失,但比例可能扭曲)。
Crop and resize:依照目標尺寸的比例,先把多餘的內容都去除掉再縮放到目標尺寸(會損失原圖的內容)。
Resize and fill:依照目標尺寸的比例,在不足的地方填充雜訊,然後縮放到目標尺寸,接下來靠img2img來把雜訊轉換成有意義的內容(會增加原圖的內容)。
Just resize (latent upscale):與第一個功能Just resize相同,但是Just resize是直接縮放,而這個選項是使用AI放大演算法來縮放圖片,所以需時較久,但是在放大後可能產生比較多的細節(原圖內容無損失,但比例可能扭曲)。 - 輸出尺寸設定:我們可以在img2img的時候指定成品圖的新尺寸,有兩種方法:
Resize to:直接指定成品圖的長與寬。
Resize by:指定成品圖的放大或縮小倍率,預設是1,也就是不變動。 - 去躁力度(Denosing strength):輸出圖片的變動程度。在img2img的第一步,Stable Diffusion會將噪訊加進輸入圖片中,然後依照提示詞的內容來產生圖片。數值越大的話,第一步加入的噪訊就會越多,輸出圖片會差異越大。例如0.1到0.2時,只會在細微的圖樣,陰影產生變化。到了0.4以上,就會對畫面中的小物品產生明顯變化,到了0.6以上會對整張圖的組成產生很明顯的影響,例如人物姿勢與位置,甚至整個構圖都會不一樣。到了1就會產生一個跟輸入圖毫無關聯的圖,其實就等於純粹的文生圖。
除此之外,AI跑新圖的時間也與去噪力度有關,數值越大就會跑越久。當你設定要跑100步,但是去噪力度為0.1時,它實際上只跑了100*0.1=10步。 - 提示詞提取按鈕:讓使用者可以從輸入圖提取可能的提示詞。Automatic1111提供了兩種不同的演算法來提取提示詞。
Interrogate CLIP:使用OpenAI開發的CLIP演算法來提取提示詞。使用這個方法提取的提示詞使用的是自然英語的語法。由於大部分的網路圖片都是自然英文,而Stable Diffusion使用的是網路圖片以及其敘述來訓練基本模型,所以理論上使用這個方法得到的提示詞在生成真實世界照片時效果較佳。
Interrogate DeepBooru:針對2D動畫的模型,例如Waifu-Diffusion或NovalAI都是從DanBooru這個網站抓圖下來訓練,而這個網站使用的分類標籤系統,就成了DeepBooru這個演算法的基本資料。使用這個方法會提取出以標籤為主的提示詞,以逗號分隔。常用的提示詞如1girl,long hair都是這個提示詞演算法引入的。也因此只有在動漫畫相關的模型裡面,這樣的提示詞才有明顯作用。如果是純粹的Stable Diffusion基本模型,應該沒有自然英文語法來得好用。
下面是一個原版圖片,依照不同的提示詞與0.65的Denoising strength來重繪的比較圖:
























