ControlNet的OpenPose是一開始最主要引起大家關注的一項約束類型。透過提取出原圖中人物的動作姿勢骨架圖,讓我們可以更精準地做到對成像人物姿勢的掌控,即使是一些光靠文字描述也形容不出的動作姿勢,也能輕易實現。
OpenPose 預處理器 & 實例
OpenPose目前的預處理器有6個 : openpose、openpose_full、openpose_hand、openpose_face、openpose_face_only、dw_openpose_full。
下面我們直接看成像實例來比較各預處理器在不同動作姿勢,提取特徵時的靈敏度(準確度)與最後成像上的差異。
首先一開始,我們先拿最簡單辨識的正面人物擺拍圖來測試。(提示詞都是空白)
openpose : 只提取人物大致全身骨架位置
由於openpose只提取出人物全身骨架位置,缺少手部關節訊息,最後成像有可能如下圖人物的左手,腰側並沒有口袋,但整個手掌就不見了(沒畫到)。

openpose_hand : 提取人物大致全身骨架位置 + 手部關節

openpose_face : 提取人物大致全身骨架位置 + 臉部輪廓/五官位置
雖然也沒有提取出手部關節,但這次刷圖剛好SD左手腦補的很自然合理

openpose_face_only : 只提取臉部輪廓/五官位置

openpose_full : 提取人物大致全身骨架位置 + 手部關節 + 臉部輪廓/五官位置

dw_openpose_full : 提取人物大致全身骨架位置+ 手部關節 + 臉部輪廓/五官位置
和openpose_full一樣,骨架、臉與手部關節全提取,但這張圖dw_openpose_full把右手只露出手一小部分手背的地方也偵測出來了。目前大多數的人像全身圖測試下來,都是以dw_openpose_full的靈敏度(準確度)最好。

上例這張原始圖人物的動作姿勢還比較簡單好辨別,經過各預處理器產出的圖差別不太大(都能產出正常合理的圖)。但後面其它人物動作姿勢比較複雜時(要考慮深度或是肢體有重疊交錯)就可以明顯看出各預處理器間的差距。
接下來我們來測試一下難一點的動作姿勢,下面這張原圖人物左右腳前後交錯。(提示詞都是空白)
從下圖的預處理圖可以看出,openpose_full沒能提取到右手關節,而dw_openpose_full則全部動作姿勢特徵都順利提取到(身體骨架、兩手關節、臉部)。
但就像之前在depth深度約束那篇文章裡有提過,openpose的人物骨架圖訊息是平面的,對於左右腳前後交錯的空間位置,在最後的成像圖上並無法完全還原出原圖的效果(右腳雖交錯在後,但是稍微往外靠而不是整個縮在後方)。

可能上面這張原圖的人物動作姿勢深度的差別不明顯,那麼我們再來測試一張更明顯的例子,來看看openpose的預處理器會不會都翻車。
(這張圖需要給點提示詞 : a girl taking selfies with smart phone)
和上一個例子一樣,dw_openpose_full提取的效果比openpose_full好(雖然dw_openpose_full也沒把手關節完全提取正確,但至少兩手都有辨識到)。不過兩張最後的成像除了手的問題以外,人物的頭身比例和前後深度感仍然很詭異/不自然。

即然覺得深度透視感出了問題,那我們就來試試再添加一個depth深度約束來輔助成像。

加了depth深度約束後,畫面整體的感覺又更自然合理了些。或是其實以這張圖的人物動作來說,要還原圖中人物的動作姿勢,直接使用一個depth控制約束就行。openpose並不實用。
最後我們再來看看不同類型的人物圖透過openpose提取特徵的效果。
畫面中多人合照圖 : (提示詞 : man and women looking at a tablet cheerfully)。這張SD很自然地自動腦補骨架最高的畫成man,其他骨架畫成women。

雖然dw_openpose_full最後的成像有點小失誤(紅框中男女兩人手臂交疊處前後順序與原圖稍有不同),不過整體沒太大的問題。而openpose_full在多人同時出現在畫面中又彼此靠都得很近的情況下則丟失掉更多的動作姿勢訊息。
從上一個多人合照案例中,我們發現,畫面中人物肢體交疊處似乎特別容易辨別失誤,那麼我們再來試一張最後讓所有預處理器都翻車的照片 :

到了這張圖很意外地,前面一直表現勝過openpose_full的dw_openpose_full反而翻車得更嚴重,這兩張預處理圖都無法直接使用。
不過難道我們就只能受限於現有預處理器效果的限制,無法不論是在任何動作姿勢的狀況下,也能生成一張完全符合我們需求的人物骨架圖嗎?
當然不是~ 當Openpose裡所有的預處理器都無法達到我們需求時,我們還可以透過各式調整骨架圖的外掛擴充來修正預處理器判斷/提取失敗的部分,又或者自行生成骨架圖給OpenPose的Model讀取生成圖像。
OpenPose 骨架圖修改/調整外掛工具
從extensions頁面下搜尋”openpose”,可以看到目前有4個相關的外掛擴充可用。關於如何安裝外掛擴充,請參考之前的文章 :
→ AI繪圖-Stable Diffusion 007- 外掛擴充 Extensions 的安裝、更新、移除與備份
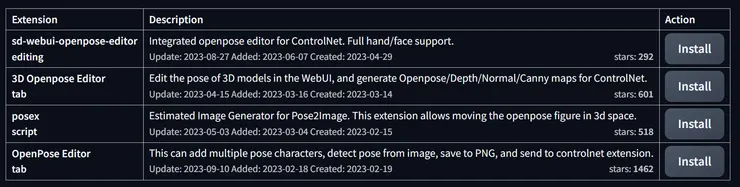
這邊我們先安裝第一個”sd-webui-openpose-editor-editing”來測試。安裝完成重啟SD後,在Openpose的預處理圖視窗右下角處點擊”Edit”就會進到針對預處理圖修改/調整的面頁 :
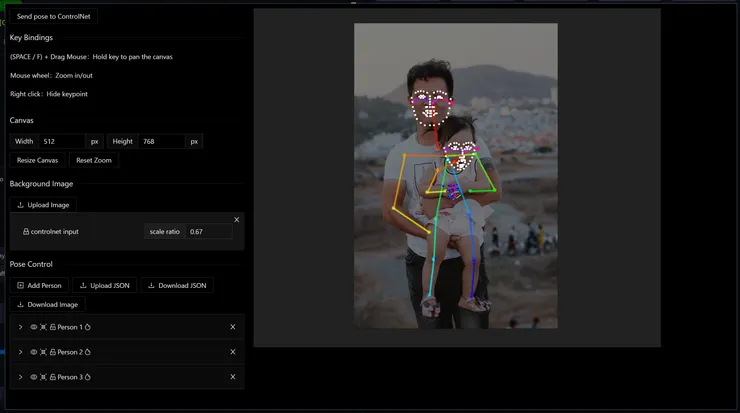
這個編輯畫面使用上就挺直覺的,右邊畫布區滑動滑鼠滾輪放大縮小、空白鍵+滑鼠左鍵移動畫布。左下方可以自行增減人物群組,這邊就和Photoshop的圖層操作使用上一樣。
唯一注意的就是要針對整個部位群組(如下圖的右手)做放大縮小旋轉移動時,在下拉選單沒展開的狀態下,直接點選手部位置就會出現變形操作的外框。但如果是在下拉選單展開的狀態下的話,就要用拖曳框選出手部所有的關節才行。
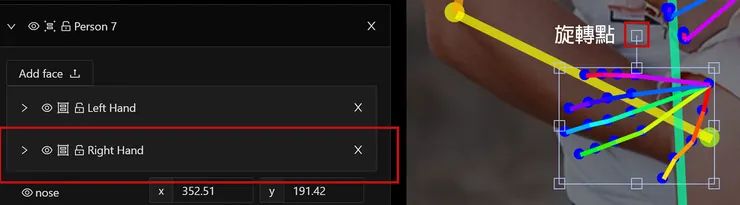
如果是要對群組內的個別節點做調整修改時(如下圖調整右手關節位置),就要先將群組選單展開,之後再點選各個節點操作。
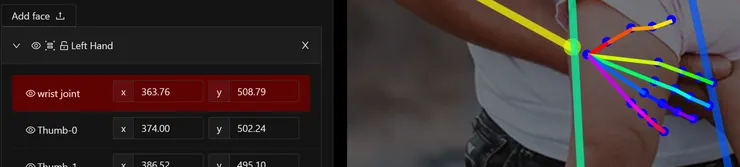
費了些時間,總算把父女倆人的骨架與手部關節大致完成。接著將骨架圖傳送回ControlNet。
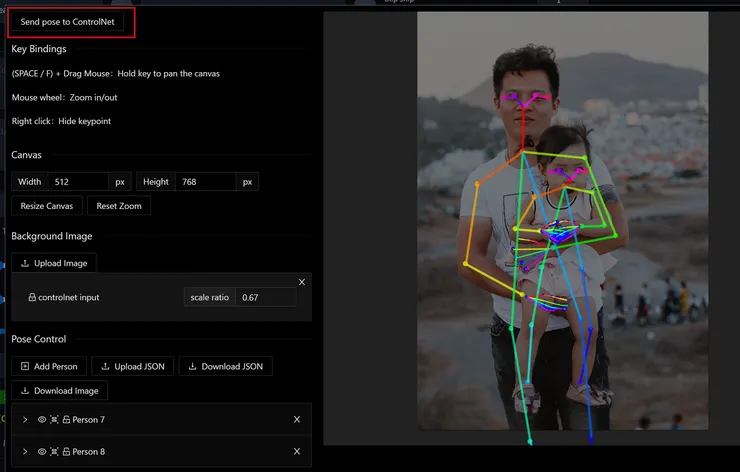
首先,只單用一張OpenPose來約束成像。(提示詞 : father holding little girl,畫布改成原圖長寬一樣以外。其它所有參數設定都直接用預設)
骨架圖還原了”平面”的動作姿勢,但人物肢體交錯前後位置則無法掌控。~ 小女孩左手要蓋住右手,男人的右手要在小女孩右腳後方拖住屁股 ~

也許單靠平面骨架圖就有機率剛好可以刷出和原圖一樣的前後位置(不過我刷了幾十張才出現過1、2張@@),但如果凡是只靠運氣刷圖,就不是我們多花時間學SD的目的。
因此,我們再來實驗搭配其它約束類型來試看看。
多增加一個depth深度約束,單從depth預處理圖來看,至少小女孩的右腳應該要是在男人右手的前面,但不管如何試(即便把depth約束的權重拉高+depth的Control Mode 用ControlNet更重要),都還是一樣,刷不出原圖該有的前後位置。

即然depth深度約束行不通,那麼再來試看看搭配normal,直覺上normal預處理圖的效果對這種前後貼很近的位置關係應該會比depth更精準表現。但最後出圖的結果只把小女孩左手蓋住右手這部分修正了,但男人的右手還是固執地畫在小女孩右腳的前面。
這裡實在讓人難以理解,明明預處理圖都這麼明確指示小女孩的右腳更凸出是整個蓋過男人的右手(即便把normal約束的權重拉高+normal的Control Mode 用ControlNet更重要),為何你SD一直要把右手往前畫~這種抱法不符合人體工學好嗎,右手應該要拖在小女孩的屁股上才抱得穩呀~~~

depth不行,normal也不行,最後我再試一個,特別針對右手要放在小女孩後面這部分加上線條約束(Lineart)。
搭配Lineart(Lineart約束的權重預設的1 + Control Mode 用 Balanced),終於差不多有一半的機率會正確畫出男人右手在小女孩右腳後面,同時小女孩的左手也蓋在右手上了。
並且,由於這裡的Lineart預處理圖我是另外有修改把非動作姿勢以外的線條給清除掉(為了不讓人物長相太過與原圖相像),這時盡量Lineart約束的權重別設太高或是Lineart的Control Mode也不要設ControlNet更重要,因為這樣有很大的機率會莫明奇妙畫出第三、第四顆人頭畸形的畫面~ 因為你讓SD過度偏重Lineart預處理圖,但畫面中又太多地方沒有給出線條的指示,SD只好發揮它天馬行空的專長,畫些奇奇怪怪的畸形圖給你了。

最後的最後,我想要出圖有正確動作姿勢的機率再拉高一點,一次開3個ControlNet類型來約束成像看看。


三個ControlNet一起使用的情況下,每次刷出來的圖的動作姿勢幾乎就是我要的了,不過不知為何,成像的圖怎麼愈來愈走復古舊照片的調調了?看來這裡又是要再後續處理的問題了……
為了這動作,刷了一下午的圖,內心感慨,給我一台相機吧,有時在那刷圖猜測久了也是挺累人的@@~ 不如走出去拍拍真實的照片吧 ~ 拍下想要的照片之餘也順便調劑身心放鬆心情 ~
(PS. 用SD刷圖,特別是在一直有使用ContrlNet的情況下,用久了有時覺得刷出來的圖怪怪的(如下圖像是某個參數異常調得太高或太低),可是明明不是參數沒調對,反而比較像是SD透逗時,就把SD關閉重啟吧~ 很多時後原本一直困擾的問題就通通不見了~)

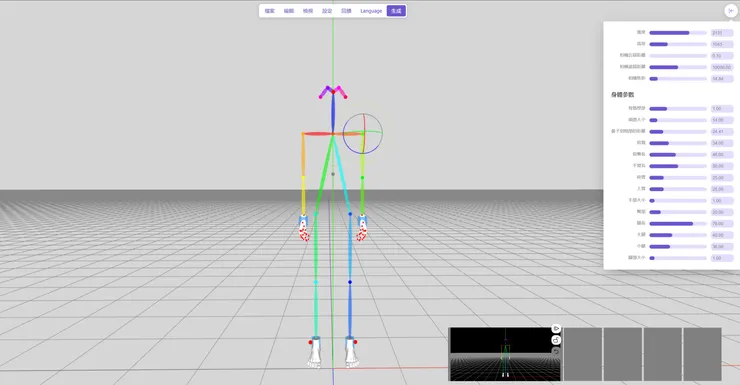
至於另外3個修改調整骨架圖的外掛擴充,我也只使用過3D Openpose Editor tab。另2個大家有覺得比較好上手使用也可試看看,我是前2個(“sd-webui-openpose-editor-editing” 和 3D Openpose Editor tab)就覺夠用了(也比較方便操作)。
而3D Openpose Editor tab在操作介面上對沒使用過3D軟體的人可能會覺得不太好操作掌控,不過因為它有更多的參數可調整,可以更精細調整動作姿勢。有興趣的人可以先到它的線上網頁版試操作看看,覺得有必要(好用),再安裝到SD上。
→ https://zhuyu1997.github.io/open-pose-editor/