行程(Process)
概述
§ 一個簡單的CPU工作原理
設置好PC初值 → PC自動遞增 → 取指令執行。
左圖簡單描述了CPU取指令執行的過程,其中(PC)為程式計數器,它位於中央處理器中,是一個暫存器,用來儲存CPU正在執行的指令位址或者下一個要被執行的指令位址。只要設置好PC初值,讓CPU依序取指令執行就可以了,這看起來好像非常簡單,但是在現代的系統當中有這麼簡單嗎?答案當然是否定的!我們必須要考慮多個程式的運作,遇到IO要求時的處理、選擇哪個行程配置CPU給其使用、程式載入記憶體的分配管理以及提升記憶體使用率及不浪費記憶體空間的虛擬記憶體技術等等,在接下來的文章當中,我會一一介紹。
§ 當簡單的CPU工作時遇到IO要求
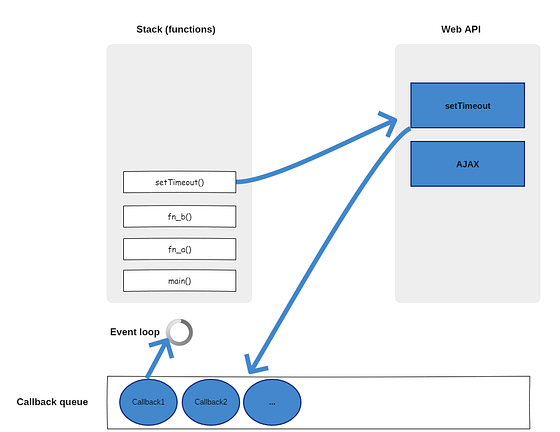
在這個情景下,CPU遇到IO要求時便會閒置,等待IO處理完成才繼續執行。我們可以往下看“讓我們來看一下IO的執行時間”這個主題,可以發現IO的處理非常耗時,如果說CPU必須等到IO處理完才能繼續執行的話,明顯地可以看出CPU的使用率非常的差。舉個例子來說:『如果現在記憶體當中有兩個被載入的程式,我們將其命名為A與B,當CPU執行A時遇到了IO要求,此時CPU便會閒置,等待著IO處理完成,才繼續執行A,又等A執行完我們才能執行B,這樣的情況下CPU使用率極其差。』,以上的例子說明了簡單的CPU工作遇到的情形。在這裡我們希望有個機制可以處理這情況的發生,例如:在執行A時遇到IO要求,此時讓A不再佔據CPU的使用,而是讓CPU去執行B,這時候我們可以發現CPU與IO平行的工作,大大提升運行效率,CPU的使用率上升同時也讓B不用繼續等待A處理完成才能執行,這就是接下來我們將要介紹的上下文切換(Context Switch)以及行程排班(Process scheduler)。

從左圖可以看到,CPU在執行任務A的時候,遇上了IO要求,於是CPU不再等待IO的處理完成,反而轉去執行任務B,這個就滿足了我們剛剛前面所說的處理機制行程排班,而這個切換為上下文切換,此處理機制大大地提升CPU的使用率,可以讓單個CPU在一個定量時間做更多的事情,這樣的交替執行任務,也延伸出了並行概念,同時有了並行概念我們也可以順便介紹平行概念,比較它們倆個之間的不同點是什麼。
讓我們來看一下IO的執行時間


§ 並行與平行(Concurrency and Parallelism)
CPU的執行速度非常的快,在1秒鐘之內來回執行了好幾個任務,就好像是我們在同一個時間內一次執行好幾個任務,但是事實上並非如此,並行是一個任務執行完接著換下一個任務執行,它是一個接著一個的,並不是同時執行這些任務,正因為如此地快速交替執行,讓我們產生了平行運行的錯覺。有了前面所說,那我們也能知道平行是怎麼一回事了,就是同時間執行多個任務。
平行需要依靠多核CPU才能實現,而並行僅需要單核就能實現。
讓我們用一張圖來描述上述所說的

§ CPU切換不同任務執行所需的資訊
前面有說到,CPU藉由PC存放要被執行的指令位址然後執行指令,那麼上述所說的“讓CPU可以在等待IO時執行其他的任務”該如何做到呢?是單純地變更PC裡面存放的位址就好還是有什麼其他方法呢?想一想當然不可能只更改PC而已,任務自己本身的資訊狀態我們也必須保存,才能讓CPU知道要執行哪個任務以及它現在執行到哪裡了,所以這裡我們會延伸出行程控制塊(PCB)這個概念,保存著任務的所有資訊,下圖為CPU切換不同任務執行時,作業系統為我們保存任務A的PCB及取回任務B的PCB,讓CPU可以順利地工作。

什麼是行程呢?
行程對於作業系統來說,就是程式運作的實例。程式是儲存於硬碟當中的靜態文件,透過編譯生成二進制可執行文件,當我們執行這個二進制可執行文件,作業系統可以為這個二進制可執行檔案創建一系列資料結構並且將這個二進制可執行檔案載入記憶體,我們稱該一系列資料結構為行程控制塊(PCB),它儲存著作業系統對控制一個行程所需要的全部訊息,行程控制塊它被存放在作業系統的記憶體空間裡,使作業系統可以明確地對該行程控制塊的行程進行操作。這裡簡單來說行程就是一個運行中的程式。
從使用者角度看行程

- 本文區(text section):行程有時也稱為本文區,包括了目前運作的程式計數器(PC)數值和處理器的暫存器內容。
- 堆積(heap):在行程執行時,可以動態地分配記憶體以進行處理。
- 共用程式庫:用來存放像C標準庫和數學庫這樣的共享程式庫資料和文本的區域。
- 堆疊(stack):存放暫用資料,例如函數的參數、返回位址,以及區域性變數。
- 資料(data):包含全局的變數。
- 核心虛擬記憶體:不允許應用程式讀寫這個區域,相反,一些操作必須調用該核心。
行程控制結構
上面我們有說過作業系統會為運行中的程式創建一系列資料結構,我們稱它為行程控制塊(Process Control Block,PCB),它是幹什麼用的呢?在這裡我們提出一個問題“作業系統是如何感知一個運行中的程式呢?”,答案就是透過行程控制塊(PCB),因為PCB保存了行程相關資訊,這就是讓作業系統可以知道我們現在有哪些行程,然後這些行程現在是處於什麼狀態,方便作業系統對其進行控制。
§ 行程控制塊介紹

- 指標:行程被切換到另一狀態時,需要保存當前行程位置。
- 行程狀態:儲存當前行程的狀態,可以是new, ready, running, waiting或者halted等等......
- 行程號碼:行程標識符,是每個行程唯一的ID,稱為行程ID或PID。
- 程式計數器:儲存該行程下一個要執行的指令位址。
- 暫存器:這些是CPU暫存器,包含累加器、基址、暫存器及通用暫存器。
- 記憶體限制:此欄位包含了記憶體管理系統的資訊,如分頁表及段表等。
- 已開啟檔案列表:該行程打開文件列表的資訊。
- 會計資訊:記錄了有關CPU使用量、時間限制、帳號、工作或行程號碼等資訊。
- 輸入/輸出狀態資訊:包含了配置給行程的輸入/輸出裝置及開啟檔案的串列等等。
§ 行程控制塊(PCB)的組織
現在我們已經知道PCB是什麼了,那它是如何組織讓作業系統可以對它進行存取呢?通常是透過鏈結這個資料結構方式進行組織的,把具有相同狀態的行程連接在一起,以下為單核CPU系統的運行佇列(單核CPU一次只能運行一個行程,所以只有一個運行指標):

在作業系統管理下的行程狀態
每個行程在特定時刻都有其特定的狀態,這些狀態都是被保存在PCB當中的,都是由作業系統來記錄,它有時位於執行狀態,又可能遇到IO要求,然後變成等待狀態,等到IO處理完成又變成了就緒狀態,又或者此行程正在從系統離開,而處於結束狀態,又或者此行程正在進入系統,而處於創建狀態,下圖為一個完整行程狀態的流程。

用文字說明上述行程狀態:
- 點擊執行檔 → 創建狀態:一個新行程創建時的第一個狀態。
- 創建狀態 → 就緒狀態:行程創建完後一切準備就緒,就會進入就緒佇列等待被執行。
- 就緒狀態 → 執行狀態:被行程排班程式選中後,分配給CPU執行該行程。
- 執行狀態 → 就緒狀態:行程執行時間片用完,把CPU使用權歸還,讓下一個行程可以被執行。
- 執行狀態 → 等待狀態 → 就緒狀態:行程遇上IO請求,轉而去處理IO,把CPU的使用權歸還,並且進入到等待狀態,等待IO處理完成才能再次回歸就緒狀態。
- 執行狀態 → 結束狀態:當該行程執行完畢或者出錯,作業系統會結束該行程。
§ 父行程產生出來的殭屍(zombie)狀態
一個行程使用fork()函數創建子行程,如果子行程退出,而父行程沒有調用wait()函數獲取子行程的狀態訊息,那麼子行程的行程控制塊仍然保留在記憶體中,這種行程稱為殭屍行程。

寫一個程式來查看未呼叫wait()函數的父行程所產生的殭屍行程
執行結果:


作業系統下的行程排班程式
行程排班在作業系統當中扮演重要的角色,它決定了當前要讓哪個行程被CPU使用,又或者將行程從記憶體當中移開(讓該行程不參與CPU的競爭),並且暫時將其放入硬碟中,等到要用該行程的時候,再將其放回記憶體中,我們稱其為置換(Swapping),又或者負責創建一個行程和終止一個行程。行程排班程式分為三種,在上面我們有稍微提過,但沒有指出它們是屬於哪個排班程式,以下來對其一一介紹。
§ 長程排班程式(long-term scheduler)
也被稱為工作排班程式(job scheduler)。從行程池中選出行程,並且將其載入記憶體中的就緒佇列等待執行。長程排班程式必須仔細地選擇I/O和CPU傾向的行程,這一點非常重要,如果說I/O傾向的行程較多,那麼就緒佇列常常是空的,又或者是CPU傾向的行程較多,那麼等待佇列就會常常是空的,會造成系統不平衡,為了使系統有最佳性能,選擇適當的I/O傾向及CPU傾向的混合行程是必要的。長程排班程式在有些系統中沒有被使用。
I/O傾向行程(I/O-bound process):CPU執行時間短,I/O執行時間長。(優先權重較CPU傾向行程高)
CPU傾向行程(CPU-bound process):CPU執行時間長,I/O執行時間短。
§ 短程排班程式(short-term scheduler)
也被稱為CPU排班程式(CPU scheduler)。主要負責將就緒佇列當中的行程選出,並且將CPU分配給該選出的行程。CPU排班程式有幾種算法,但在這裡我們先不討論,這裡僅簡單介紹它是做什麼用的而已。
用一張圖說明短程排班時機

用文字說明上述短程排班時機:
- 遇到I/O要求時,短程排班程式會將CPU分配給其他行程使用。
- 時段終止時,會從就緒佇列中選出行程,並將CPU分配給該行程。
- 父行程產生子行程時,讓出CPU使用權。
- 發生中斷時,當前執行中的行程被迫讓出CPU,轉而去執行該產生中斷的行程。
§ 中程排班程式(medium-term scheduler)
主要是透過記憶體管理以及虛擬記憶體管理技術來實現的,將暫時不會用到的行程分頁移除記憶體,放入磁碟空間當中,等到有需求的時候才會把該行程分頁載入到記憶體當中。它總是不會把整個行程載入記憶體,而是僅載入所需的行程分頁,其餘不常使用的就會留在磁碟空間中,這樣做的好處是妥善地利用記憶體空間,不會造成浪費,也大大降低了置換時間。

執行緒(Thread)
什麼是執行緒呢?
執行緒是作業系統進行CPU排班的最小單位,它被包含在行程內,是行程當中實際的運作單位。每個執行緒都有一套獨立的暫存器、堆疊空間、執行緒ID及程式計數器,可以確保執行緒的控制流程是相對獨立的。一個行程可以含有多個執行緒也可以只有單一個執行緒,並且這些執行緒彼此共用所屬行程的程式碼區塊、資料區塊和作業系統資源(開啟的檔案列表和信號),下圖讓我們來看看單執行緒行程與多執行緒行程的差別。

有行程了為何還要有執行緒呢?
CPU一次只能執行一個任務,如果說作業系統進行CPU排班的最小單位是行程,那麼現在我們在只有一個CPU運行的情況下,並且執行一個單一應用程式文書處理器,讓這個CPU執行這個文書處理器的行程,如果說這個文書處理器有很多功能,例如:顯示圖形、回應使用者的按鍵、拼字和文法校正,也就是說CPU在執行一個功能時,其他功能不能同時被執行,為什麼會這樣呢?因為這些功能是包含在這個行程內的,無法被作業系統排班分配CPU,於是不能同時執行多個功能(這裡指的是並行,CPU執行快所以有同時執行的錯覺)。接著講下去,現在我們想要讓使用者使用起來可以很舒適,於是我們使用fork()函數去創建一個子行程,讓這些子行程分別代表不同功能,於是這些功能就可以被作業系統排班分配CPU使用了,並且可以同時執行多個功能了,但這又有一個問題,行程的創建及上下文切換是相當耗資源及時間的,於是就發展出執行緒,並且作業系統進行排班的最小單位也是執行緒。

§ 多執行緒的好處
在上面其實我們已經有提到執行緒的好處了,這些好處是相比於行程下的,比如說執行緒的創建總是會比行程的創建還要來的快,還有上下文切換也絕對比行程的上下文切換來的快。基於以上的提及,以下我們更加詳細地說明使用多執行緒的好處。
應答:如我們前面所說的文書處理器,不會因為某個功能正在執行,而讓其他功能不能使用。我們增加對使用者的應答,比如說我在輸入文字的同時,也會對這些文字進行驗證,又或者正在影印文本內容,發現有地方可以修改,那我可以暫停影印去修改內文,這些都是讓文書處理器這應用程式可以隨時保持對使用者的回應。
資源分享:我們知道行程是透過共用記憶體(shared memory)空間及訊息傳遞(message passing),需要透過一些額外的技巧來實現,然而執行緒它們是包含在行程內的,彼此共用著行程的記憶體及資源。
經濟:行程對比執行緒其創建開銷大,行程需要資源配置,而執行緒是去共用所屬行程的資源,不論是執行緒的創建還是上下文切換都比行程更加經濟。
可擴展性:先前有提及過並行與平行,在一個多處理器的架構下,多執行緒可以發揮出最大利益,也就是說在某個行程下的多執行緒可以平行地在不同核心當中執行,同時每個核心又能並行地執行執行緒。
§ 行程與執行緒的比較

§ 執行緒共享資源可能面臨的問題(初步提出概念不細談)
寫一個程式來查看共享資源所面臨的問題
執行結果:

為什麼會有這種不正確的狀態發生呢?讓我們思考一下
這裡我們先了解sum++及sum--的組合語言的執行順序,如下圖:

假設現在執行緒“first”從記憶體當中取得sum的值(假設為100),將其放入到暫存器當中,然後對暫存器的值+1(101),此時卻因為時段終止,將當前正在運行的執行緒把其狀態及資訊保存到TCB中,而最後一個指令將暫存器的值放回記憶體中的sum變數沒有執行,現在切換到執行緒“second”它從記憶體當中取得sum變數值(100)將其放入暫存器,然後對暫存器的值進行-1(99),接著將暫存器中的值存放回記憶體中的sum變數,此時sum變數值為(99),現在又再一次切換,此時執行緒“first”將暫存器的值(101)放回記憶體中的sum變數,可以發現正確的值應該要為(100)可是現在卻是(101),什麼導致了這情況發生?簡單來說就是執行結果取決於它們之間的存取順序,因此大大地影響了資料一致性,我們稱這種情況為競爭情況(race condition),以下以圖來說明這整個流程:

執行緒模式
在討論執行緒模式之前,我們先介紹執行緒的支援,如下:
使用者執行緒(user thread):在使用者空間實現的執行緒,不是由核心來管理的,而是透過使用者態的執行緒程式庫,提供程式設計者一個API來產生和管理執行緒。
核心執行緒(kernek thread):在核心當中實現的執行緒,是藉由核心來管理的執行緒。
輕量級行程(lightweight process,LWP):位於使用者執行緒及核心執行緒之間的資料結構,負責它們兩個之間的通訊。為核心支持的使用者執行緒,每一個LWP連到一個核心執行緒,也就是說LWP皆是由一個核心執行緒支持的。
§ 多對一模式
使用者層次下的多個執行緒對應一個核心層次下的核心執行緒。在此模式下,使用者執行緒的創建、終止、同步和排班都是透過使用者層次的執行緒程式庫來實現的,作業系統不會直接參與其中。

作業系統不直接參與其中會發生什麼事呢?
- 該行程的執行緒控制塊(TCB)位於使用者空間,執行緒切換是由執行緒函數庫來完成的。
- 由於這些執行緒皆為使用者層次的,也就是說這些執行緒是不會藉由作業系統來進行CPU排班,如果說該行程中的一個執行緒發起了IO請求而進入等待,那該行程所包含的執行緒都不能執行了。

- 時間片段是分給核心執行緒的,所以這模式下的使用者執行緒得到的時間片段就會較少,執行起來會變慢,因為每個執行緒都執行一點點,無法分配到一個完整的時間片段。
- CPU一次只能運行一個任務,所以如果在多核CPU中,此模式無法充分利用CPU的。
§ 一對一模式
在這個模式下,使用者層次的執行緒會對應一個核心層次的執行緒,當其中一個使用者執行緒遇上了IO要求,其他的使用者執行緒不會被阻塞,因為作業系統的CPU排班是針對核心層次執行緒,相比於多對一模式僅有一個核心層次執行緒,一對一模式有更大的彈性空間。但同時有個問題,在這種模式下的執行緒必須要限制數量,因為使用者與核心執行緒是一對一的,並且核心執行緒是存放在核心記憶體空間當中,過多會造成應用程式性能影響。“Linux”及“Windows”作業系統家族都實現了該模式。

§ 多對多模式
此模式是一對一及多對一模式的混合版本,有效解決使用者執行緒遇IO要求,其他使用者執行緒被阻塞的問題,還有執行緒數量會被限制的問題,也就是說當有使用者執行緒進行系統呼叫,其他的使用者執行緒不會被阻塞,並且使用者執行緒的數量也不會因為核心執行緒的數量而被限制了。此模式大部分的上下文切換都發生在使用者空間,且多個核心執行緒又能充分地利用多核的CPU資源。

參考來源
- B站,操作系統(哈工大李治軍老師)
- YT,作業系統(周志遠教授)
- Abraham Silberschatz, Peter B. Galvin, Greg Gagne。《作業系統概念》。駱詩軒譯。台北。台灣東華書局。