這是 ComfyUI 教學第二階段關於中階使用的第三部,也是最後一部了。今天我們來看 upscale 跟 SDXL 的基本架構,XL 和我們之前講的基礎 workflow 雖然說差不算很多,但還是有差異嘛,今天會來看一下。
Ultimate SD Upscale
在 comfy,同一個目的基本都有很多不同的手段可以達成,簡單好用的,通常操作控制的幅度就不大;要效果好的,勢必在操作上就會稍微麻煩一點,但你也可以掌握到更多的控制權。
而且說麻煩吧……其實用習慣了也還行。🤔
接下來我們要講的 upscale 也是這樣的,雖然 comfy 有自帶簡單的 upscale 方塊,但因為幾乎沒有甚麼控制項,所以單用的時候也算不上有甚麼修復效果,就是能夠放大而已,唯一的優點是用起來簡單。

如果你是只需要把上傳的圖放大,而且圖片本身已經沒有甚麼瑕疵的,可以考慮用這幾個快速 upscale 一下,或是你的模型跟 prompt 已經調適到出圖穩定的狀態,也可以用這種簡單的。
而我們這次主要要看的是,webui(a1111) 使用者們熟悉的 ultimate SD upscale。首先這是需要安裝的,所以老樣子打開你的 manager 搜尋一下 upscale,找到 UltimateSDUpscale,裝完後記得把 comfy 完整地重開一遍。

接下來,按一下旁邊的 clear,先把畫面清空,在搜尋框打 ultimate,或是空白處右鍵 add node > image > upscaling 在最下面可以看到。
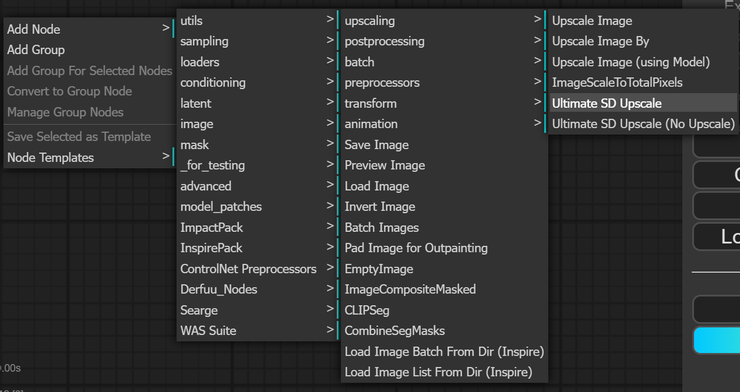
第一個就是一般的,有包含放大的 upscale,雖然聽起來好像廢話XD,但會這麼說是因為第二個呢,是不包含放大的 upscaler,也就是說它會用 upscale model 去做細化、重繪,但不改變尺寸,依你的需求來選擇你要叫出的方塊吧。
控制項
先不要害怕!雖然看起來很長一串,但冷靜下來看,大部分的東西,其實你都認得的,跟基礎 workflow 使用的 Ksampler 大差不差。從 seed 開始到 denoise 都是熟悉的設置,這些應該都沒問題吧?對新手來說可以忽略不計的是從 mask blur 到 force uniform tiles 這一串,都不用改,你就讓它保持預設狀態就好了。
所以,說到底這一串你只需要新學 upscale by 跟 mode type 到 tile 長寬這幾個是甚麼意思就行了。

現在我們從頭看哈。
upscale by 是指你要放大的倍數,通常我們會設 1.5-2 倍。
seed 沒意外放它 randomize 就可以了,要固定就選 fixed。
步數 steps 20-50 都可以跑,越高越慢,請各位斟酌自己的硬體設備極限。
cfg 可以不改。
sampler&scheduler 因為 upscale 是我在已有圖的情況下進行的升級嘛,所以這時候基本上可以選擇 euler normal,不用特別更改,當然你也可以試試用不同的採樣調度,只是運算時間也會相對更長。
後面就是在這一串裡面相對重要的部分,這個 denoise 推薦設在 0.35 以下,它控制的是重繪修復畫面的強度,如果你不想讓畫面變動太大,甚至可以調到 0.15-0.2,但千萬別放它在預設 1 的狀態,你前後兩張圖會差很多。
mode type 是選擇它處理重繪的方式,linear 是線性,chess 是棋盤,其實這兩種處理方式差距不大,你可以不去管它,等到處理的結果不好時再考慮換另一個就行,原則上我們不選擇 none。
最後是 tile 長寬的設置,這個設置決定你的原圖會被 AI 以甚麼大小來切塊處理,設置 64 的倍數都可以,但一般我們會維持 512x512 的預設,你也可以嘗試 512x768,比較不建議再往上擴大。
接線
然後就是接線啦,首先這幾個顏色的點應該大家都很熟悉是甚麼了吧,我們就快速把熟悉的接完。

因為這個最主要是讓你用 i2i 的方式來做 upscale 的,所以你可以選擇在這裡接上一個 load image 方塊,然後直接上傳一張你要 upscale 的圖片。
如果你想用 t2i 的方式來做,往上接一小段基本 workflow 的尾巴就可以,叫出 Ksampler 和 VAE decoder,前面的模型啊提示詞啊都可以共用,最後把 image 接到 upscale 方塊就好了。
如果你想要比對 upscale 前後的差異,也可以從這裡多加一個 preview。
最後,我們要給 upscale 方塊接入一個 upscale 的模型。如果你想找更多不同的 upscale 模型,可以去 openmodelDB 逛一逛。
我自己手上目前是只有這些。

SDXL
再來就是這個階段要講的最後一個東西,應該也是大家會比較感興趣的,SDXL 在 comfy 到底要怎麼使用。
首先需要知道的是,XL 它本身是分成兩個模型的,一個是 Base 一個是 Refiner,你可以單獨使用 base,但根據官方的數據,兩個加起來一起用可以達到更細緻的結果。

在 comfy 裡面,就是你要再多開一個 checkpoint loader 來放。如果你還沒有下載過這兩個模型,我把網只附在這。civitai 上面現在也已經有很多基於 XL 訓練的模型,各位可以去挑看選看。
準備好模型後,我們先從最簡單的 base workflow 開始,單只用 base 的話,基本的 workflow 就可以用了,要使用 refiner 的話,可以複製一套基本 workflow,把 base 的 output latent 接到剛剛複製的這一套 workflow 的 Ksampler 裡面,然後原本這邊的 decode 和 save image 就可以先砍了。
接下來把模型選好,畫布尺寸設好,再把 prompt 寫好,這裡一般是 base 寫一點基本的,類似像是打草稿那樣,然後在 refiner 的 prompt 寫詳細一點。當然你懶的話,可以就複製完全一模一樣的就好。
最後最重要的,調整兩個 Ksampler 的參數,調度跟採樣兩邊要選一樣的,除非你能確定結果是你要的,再考慮兩邊用不同的採樣調度。
作為草圖的 base 可以把步數維持在 20 步,把 refiner 設高一點就好。作為細化的 refiner 最要注意的是下面的 denoise,這個的概念跟 i2i 和 upscale 重繪的幅度差不多,所以這個一定要調整,建議設定在 0.25-0.6 之間,剛開始安全一點我會推薦設在 0.25-0.35 之間。


測試用prompt:lind 1painting (Melted wax-crayon style) moon and sun a alien by Henry Fuseli soft-colors (Smudged merge) goldtrim-lining masterpiece reflection-mint wildflower cradle cosmatic deep-forest Richard Anderson Valkyrie bestquality perfect composition Agostino Arrivabene green (Melted wax-crayon art)
這樣就完成了一個基本的 workflow,可以開始跑圖了。
根據你的需要,可以開始擴建 lora 或 embeddings,要注意 lora 和 controlnet 這些的模型需要選擇跟 SDXL 適配的版本,直接使用 SD1.5 的模型是跑不了的。
SeargeSDXL
那接下來,來講幾個稍微進階一點點的用法,需要先載兩個 custom nodes,打開安裝畫面搜尋 SDXL,把 SeargeSDXL 和 SDXL Prompt Styler 都安裝起來,另外還可以安裝這個 ComfyUI-SDXL-EmptyLatentImage,它是一個幫你設定好了 SDXL 最佳尺寸組合的 node,不安裝的話你可能就是稍微寫個筆記或用腦袋記一下。安裝完後,記得要完整重開。
For SDXL, it is recommended to use trained values listed below:
- 1024 x 1024
- 1152 x 896
- 896 x 1152
- 1216 x 832
- 832 x 1216
- 1344 x 768
- 768 x 1344
- 1536 x 640
- 640 x 1536
現在我們把畫面清空,準備開始拉 workflow。


在搜尋框打上 SDXLsampler,會看到三個版本的 XL sampler,我習慣用的是 v3,你也可以嘗試看看另外兩個版本。接下來我們根據上面的小點來添加其他的方塊。

基本上應該都認識對吧?稍有不同的只有最後三項,latent 可以連原本的慣用的 empty latent img 或是使用剛剛安裝的 sdxl empty latent image,這個需要你自己打開,拉線拉不出來。再來點著採樣調度其中一個點,往外拉選擇 SeargeSamplerInput,在這裡選擇你要使用的調度採樣器。
base ratio 是決定 base model 在整個成圖的過程中佔比多少,這個你可以多嘗試幾次覺得你喜歡的比例。
Prompt Styler
最後,來介紹我們前面安裝的 SDXL prompt styler 要怎麼用,這是 XL 推出之後一個蠻著名的功能,在 webui 也有這個插件,可以直接透過點選來指定畫面風格,節省提示詞的空間,而且相對穩定。不過這個接起來就稍微要再更麻煩一點點。

先把 base 的兩個輸入框砍掉,然後從搜尋框找到 CLIPTextEncodeSDXL 並且多複製一個,再來把 prompt styler 也叫出來。
我們需要讓輸入的文字,經過這個 styler 再送到 encoder 裡面,所以第一步,在兩個 XL text encode 上面按右鍵,把 text_g 跟 text_l 都轉成外部輸入的小點,把 styler 右邊的正向跟反向分別拉進來這兩個 encoder,各連兩個點就可以了。

其實呢 prompt styler 它也可以用我們剛剛砍掉的,那兩個原本的 text encode 來做。如果你是目前還並不確定 clip_g 跟 clip_l 它們這樣的區分,有什麼不一樣效果的人,也可以選擇用原本的 text encode 來做連接就好了。
但是如果你是知道這個東西的人,我會推薦你在使用 XL 系列模型的時候,選擇使用這樣的提示詞輸入框,它會讓你得到更好的控制效果。
關於這兩個東西有什麼區別,我們今天先跳過這個部分。或者是你也可以稍微在 github 跟 reddit 上搜尋一下,其實是有人特別針對這個做過說明的。
進階閱讀:SDXL Mini Study: CLIP G vs CLIP L Best Prompting Conventions
都接好之後把 clip 和 conditioning 按照平常的接法接好就可以了。
到這邊基本的 SDXL 流程就排完了。
在使用 XL 系列模型時,不論是 lora 還是 controlnet 都需要選擇 XL 版本的對應模型,跟 1.5 系列是不同的,如果跑圖的時候報錯了,可以優先從模型版本開始檢查。
實用小技巧
這次的最後我們來介紹一個 workflow,在 Reddit 上有大神分享了他排的 XL 快速大圖流程,我試用了一下速度和成品都很不錯,流程本身挺簡單的,雖然是去年年中製作的流程,但現在用起來也還是非常地好用。我會推薦新手可以根據這個架構,搭配前面我們聊過的其他功能去做流程擴展,替換不同的方塊,或是參考之前我們上次聊過的去年底的更新內容,把流程重新整理一遍。

點開上面的連結後從黃框標示的連結再點進去,找到 download 下載檔案,手動把儲存的副檔名改為 .json 就可以了。
回到 comfy 點選單裡的 load 載入,去找到你剛剛存好的 json 檔,就可以直接叫出來。在這邊要注意的是,因為作者分享這個流程是去年七月的事情,所以他裡面紀錄模型的是 XL 0.9,記得要手動換成 1.0 或其他的 XL 模型。
如果你希望生成的速度更快一點,可以把 base 這邊的 decode 和預覽都刪除或 bypass(繞過),可以再多節省一點資源。
再~多補上一個小技巧,細心的朋友可能會發現到我這次畫面上的方塊右上角都多了點東西,這是一個幫你辨別你叫出來的方塊是來自於哪套 custom node,隨著你越載越多,有時候確實是會挺混亂的嘛,這時候這個就很好用啦。

點一下你的 manager 在左邊找到下拉選單 badge,選擇 nickname,就會顯示出這個小小的標籤了。
啊狐狸頭就是官方自帶的意思。
我們中階的使用教學就到這邊結束了,下次各位會比較想看怎麼用 comfy 生成動態影片,還是建構即時塗鴉生成的 workflow?或者是有甚麼其他想看的 comfy 建構,可以在下方留言告訴我。
雖然我也可能想到甚麼就做甚麼。🤪
希望這篇教學對你有幫助,喜歡的話可以訂閱追蹤一下這個專題和Youtube頻道,更新就可以收到通知喔,有任何問題或者我有疏漏的地方都歡迎留言一起討論,也可以跟我分享你的 comfy 使用心得!
感謝各位收看。





















