本教學使用Automatic 1111介面
AI繪圖風行至今,網上已有不少中文教學,包括教導如何訓練LoRA、LoCon等模型的文章,而訓練上述模型時,通常會經過一道「Preprocess Images」工序,中文稱為「圖片預處理」。
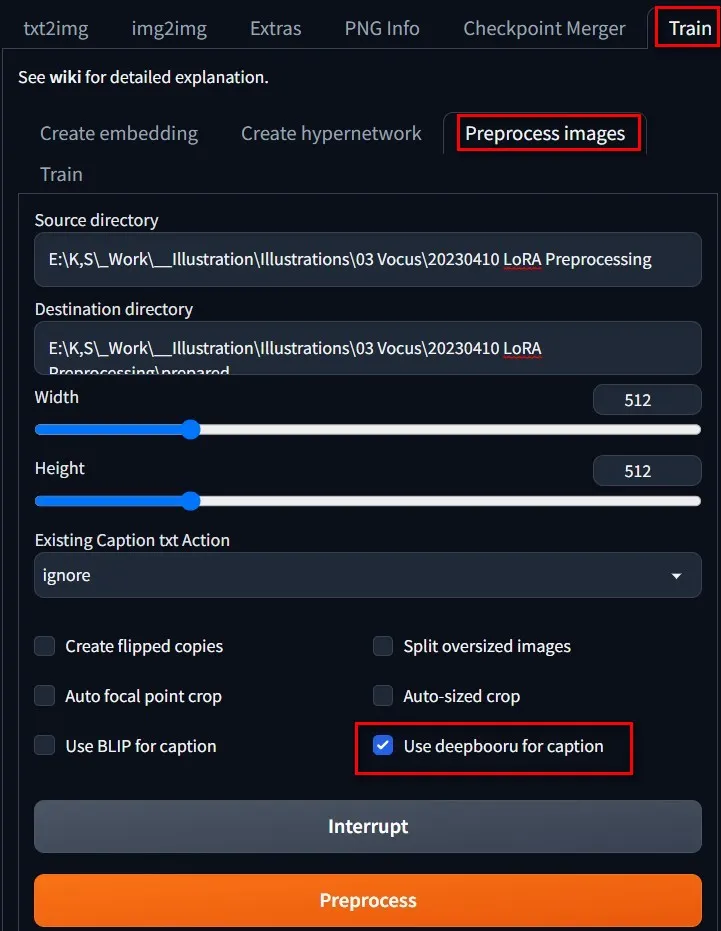
這樣其實很可惜,因為只要再多花點工夫,就可以顯著提升訓練成果的「準確度」,且只需要中等程度的英文能力和基本的關鍵字蒐圖技巧。
deepbooru - Danbooru
在勾選「Use deepbooru for caption」時,有沒有想過什麼是「deepbooru」?其實這和Stable Diffusion訓練來源的圖片有很大的關係,也就是下列網站:
https://danbooru.donmai.us/
*未成年者請勿點入*未成年者請勿點入*未成年者請勿點入
而進行圖片預處理後,有沒有想過為什麼會生成.txt文字檔案?
其實只要打開生成的.txt,就會發現是和+Prompts類似的內容。換言之,預處理就是AI以圖片反推關鍵字的工序,而deepbooru的反推結果會套用Danbooru的關鍵字格式。
以下是兩張範例:




注意到了嗎?AI預處理產生的關鍵字「不太理想」。舉例而言,範例1的.txt沒有「狐狸」和背景的「薰衣草」,而且紅框圈起的「purple_sky」(紫色天空)根本不存在。
範例2的.txt問題就更多了,例如雙胞胎的眼睛和頭髮的顏色各只提供一種、完全沒提到衣服的顏色,以及最糟糕的「own_hands_together」(自己握自己的手)!
試想一下,如果就這樣直接交給AI訓練LoRA、LoCon模型,AI當然會產生「困惑」、進而算出「無厘頭」的結果--不是因為AI笨,而是AI很忠實地遵照了荒謬的關鍵字!
參考Danbooru,修正文字檔的內容
這時就輪到https://danbooru.donmai.us/(*未成年者請勿點入)登場並充分運用英文知識的時候了。既然「deepbooru」生成了Danbooru格式的關鍵字,若要修正其內容,理所當然最好的方式就是去Danbooru尋找正確的關鍵字。
以範例1而言,我在該網站輸入「fox」搜尋結果,並點入了一張圖片:
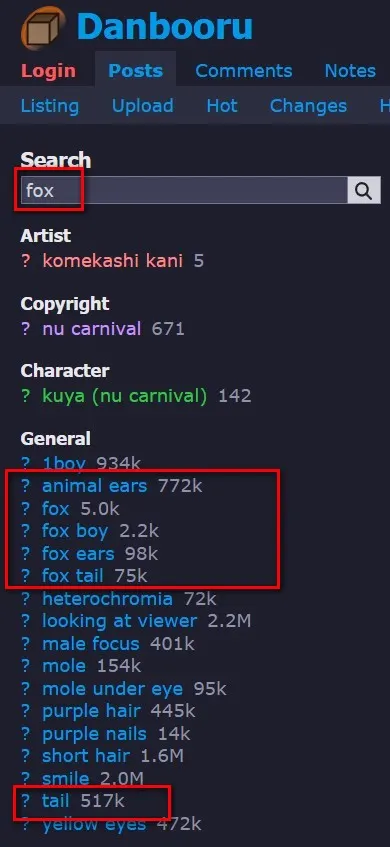
紅框的部分除了「fox boy」不能用以外,其他都可以加入到範例1的.txt檔案中。參考了幾張有狐狸的圖片後,我將範例1的.txt內容調整如下:

animal_focus = 圖片中有動物角色
fox = 狐狸
animal_feet = 動物腳
yellow_eyes = 黃色/金色眼睛
flaming_eye = 單眼冒出火焰的特效,雙眼請用 flaming_eyes
fluffy = 蓬鬆毛茸茸
lavender_(flower) = 薰衣草花,直接沿用了Danbooru網站的關鍵字格式
我也遵照AI生成的關鍵字格式,單個關鍵字的空白以「_」取代(例:flaming_eye),不過使用訓練出來的LoRA、LoCon模型來生圖時,Prompts中直接使用空白即可。
以下是調整後的範例2的.txt內容:

Lu_Ashkol/Eye_Ashkol = 角色名字
*如訓練特定角色模型,以Danbooru格式輸入該角色的英文名會非常有助益。
child = 小孩
female_child = 小女孩 -- 千萬不要使用「loli」,除非想生成「壞壞」的圖片。
flat_chest = 平胸
multicolored_eyes = 多色眼睛
two-tone_hair = 雙色髮色
multicolored_hair = 多色髮色
streaked_hair = 挑染髮色
off-shoulder_shirt = 平口露肩上衣
frilled_sleeves = 摺邊袖
bare_shoulder = 露肩
shoulder_strap = 肩帶
collarbone = 鎖骨
bangs = 瀏海
interlocked_fingers = 十指交扣
推薦使用Danbooru的關鍵字
原本我想使用「gold_eyes」代表金色眼睛,但實際在Danbooru搜尋後發現找不到結果:
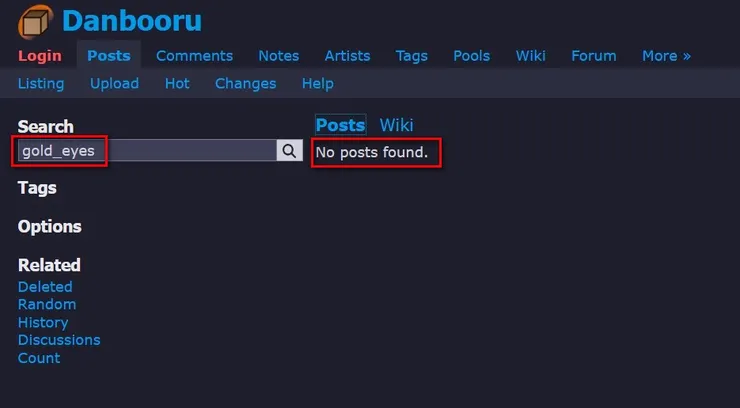
於是最後改用了yellow_eyes --其實使用Stable Diffusion生圖時,包括網路上一些Prompts範例,其中不乏一些亂七八糟、有輸入有保佑的關鍵字。雖然因為這樣做的人很多、且AI還是有一定程度的「彈性」,所以也不乏瞎貓碰到死耗子的例子,但還是建議找關鍵字時首先來Danbooru搜尋,畢竟用這裡的關鍵字生成想要結果的機率會比較高。
祝大家激發潛藏已久的英文能力,心想「繪」成!



























