有時候需要抓一些網路上的資料
而靜態網頁的呈現方式就是 html
這篇記錄一下怎麼用 Python3 抓靜態網頁上的文字
(以下部分為網路資料擷取)
開始
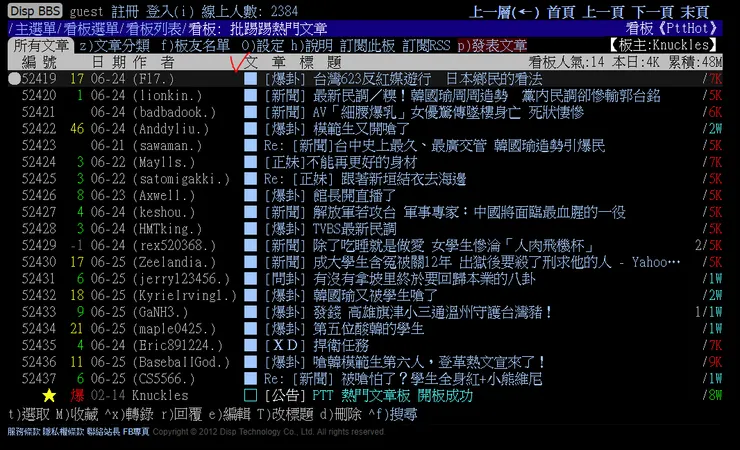
這裡以抓 ptt 網頁版為範例
要爬靜態 html 之前
必須先了解"你要抓的文字"是在哪裡
開啟網頁後, 按下 F12 可以看到每個元素對應到的 html 位置
左鍵按一下左下角的箭頭框框 (或按 ctrl+shift+C)
再把滑鼠指到你要抓的文字
然後再按一下左鍵
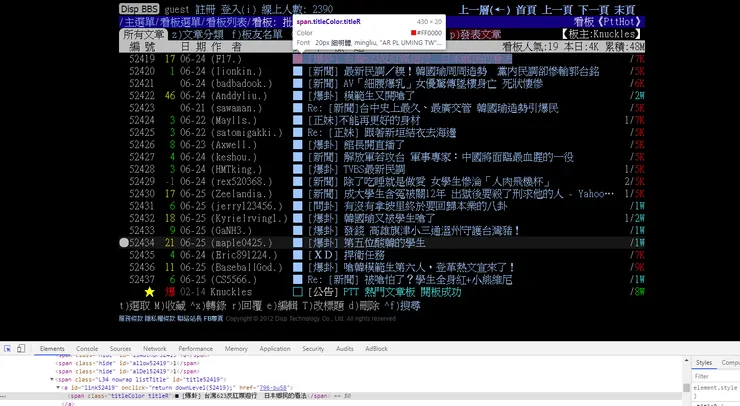
可以看到這行文字出現在 html 的哪個位置
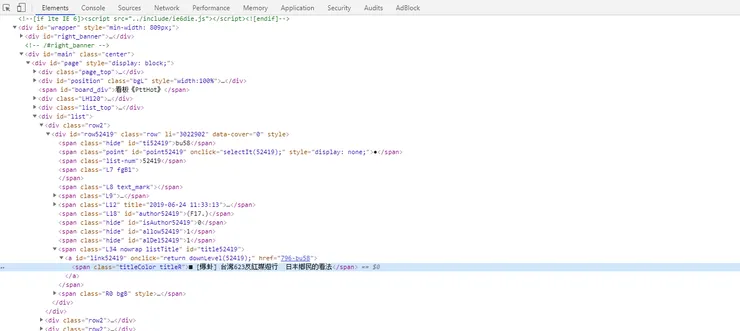
靜態爬蟲需要這樣的資訊
程式碼
首先我們必須先有辦法存取這個網頁
這個部分 python3 已經有urllib.request包好了
如下
import urllib.request
url = "https://disp.cc/b/PttHot" # The website url you want to access
response = urllib.request.urlopen(url)
data = response.read()
text = data.decode('utf-8-sig')
print(text)
執行
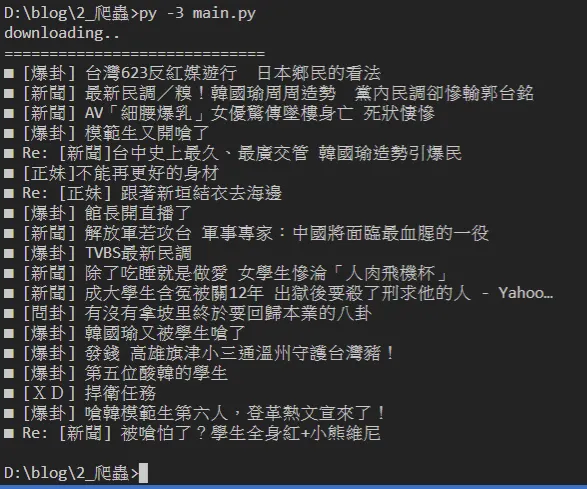
py -3 main.py
可以看到這個網頁目前的 html 已經都抓下來了
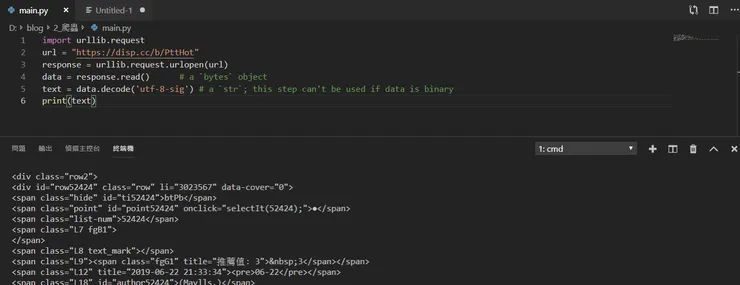
現在的目標就是抓取"你要抓的文字"
這個部分 python3 已經有BeautifulSoup包好了
from bs4 import BeautifulSoup
soup = BeautifulSoup(text, "lxml") # parse
回到剛剛上面利用 F12 所看到的 html 發現它的標題內容都是放在
span class = 'L34 nowrap listTitle', id = 'titleXXXXX'
其中 id 的部分 可以看到是第幾篇的意思, title52419, 第 52419 篇
也很剛好的, 在 list-num 就有顯示是第幾篇
span class = 'list-num'
因此這裡用 BeautifulSoup 裡面 find_all() 的方法 這裡帶有 span 裡面的 attribute 例如要找 list-num
soup = BeautifulSoup(text, "lxml") # parse
listIdxs = soup.body.find_all('span', attrs={'class':'list-num'}) # get all list
例如要找標題內容
targets = soup.body.find_all('span', attrs={'class':'L34 nowrap listTitle', 'id':'title52419'})
import urllib.request
from bs4 import BeautifulSoup
def downLoad():
url = "https://disp.cc/b/PttHot"
response = urllib.request.urlopen(url)
data = response.read() # a `bytes` object
text = data.decode('utf-8-sig') # a `str`; this step can't be used if data is binary
return text
print("downloading.. ")
print("=============================")
text = downLoad()
soup = BeautifulSoup(text, "lxml") # parse
listIdxs = soup.body.find_all('span', attrs={'class':'list-num'}) # get all list
for listIdx in listIdxs:
targets = soup.body.find_all('span', attrs={'class':'L34 nowrap listTitle', 'id':'title'+listIdx.text})
for ta in targets:
print(ta.text)
執行結果
參考
https://www.ptt.cc/bbs/Python/M.1412756706.A.390.html
https://www.crummy.com/software/BeautifulSoup/bs4/doc/#searching-by-css-class























