
這一篇來談談AI(這邊指的AI是神經網路) 到底怎麼學習畫圖的,在接觸這個之前,我也跟大家一樣覺得AI繪圖真的是太神秘了,究竟只會簡簡單單運算數字的電腦,只有簡單邏輯運算子的IC晶片到底是怎麼做到的? 本篇當然不會讓大家看長篇大論的神經網路的原理,而是用我理解這件事情的方法,分享給大家看。
談AI怎麼學習畫圖之前,我們先來了解一下AI怎麼”辨認東西"。舉例來說好了,我們今天想要教會AI辨認一隻狗,讓他以後都能認得狗,跟教小Baby學習這件事情一樣,我們就應該先給他看很多狗狗的照片,跟他說這是狗
然後看過數千張不同狗的照片以後,AI終於知道了,對這就是狗! 所以以後我們即使拿他沒有看過的狗的照片給AI看,也因為AI知道了這些特徵的集合就代表了一隻狗,所以可以輸出這是一隻狗的結果。

這就是AI學會辨識物體的方法,但是AI有分很多種Model,這些不同的AI Model各自會不同的絕技,上面說的AI model可以學會辨認很多種物體,可是他沒有辦法做到無中生有,那麼可以學習無中生有的model是什麼呢? 我們這邊介紹一種目前比較主流的generative model 叫做diffusion model. 這個Diffusion model 就是目前各種主要的生成式AI背後的原理 (但是不只diffusion model可以做到就是了)
Diffusion model之所以可以學會怎麼畫圖,當然也是要經過千千萬萬的圖片訓練的,只是他訓練的方式完全不同,假設我們拿底下這張照片來做訓練

除了給這張照片以外,我們還需要給這張照片很清晰的說明,不然還是嬰兒狀態的AI根本不知道這張照片代表的意義是什麼。接下來的訓練步驟非常的有趣,如下圖

首先我們把這張照片加上一點點Noise, 得到了稍微有點雜訊的圖片,然後又可以再加上一點雜訊,持續這樣的過程直到整張圖片都變成雜訊了。接下來我們先取其中的兩張圖片,假設是第一隻原始照片跟第二張好了
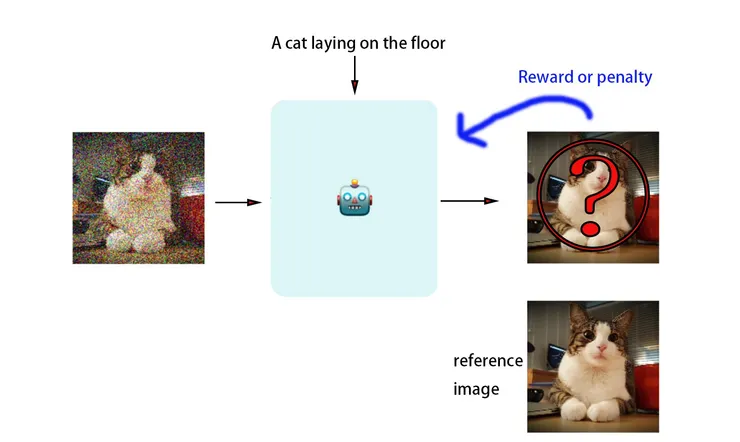
然後我們先拿第二張加了一點雜訊的圖片來,加上這句話”A cat laying on the floor” 請AI嘗試產出沒有加上雜訊的圖片。因為現在AI還沒有被訓練也不知道怎麼畫一隻Cat,所以應該產出的圖片會完全不像,如果AI產出很不像的照片,那麼AI目前的作答(權重)就會被處罰(penalty),如果AI產出的圖片比較接近原來的reference image(我們想要他產出的圖片),那麼我們就獎勵這個AI的作答。經過千千萬萬次的訓練(猜測)以及獎勵逞罰機制以後,AI就學到了該怎麼把充滿雜訊的圖片還原成原本的圖片,我們上面有一整個系列的照片從完全沒有雜訊到整張圖片都是雜訊,這些都會餵給AI去做訓練。然後當然AI也不會只訓練這一張圖片,而是我們會給它好多好多的照片圖片,搭配我們做好的說明去訓練AI,所以最後千錘百鍊的AI就練成了這樣的功夫….
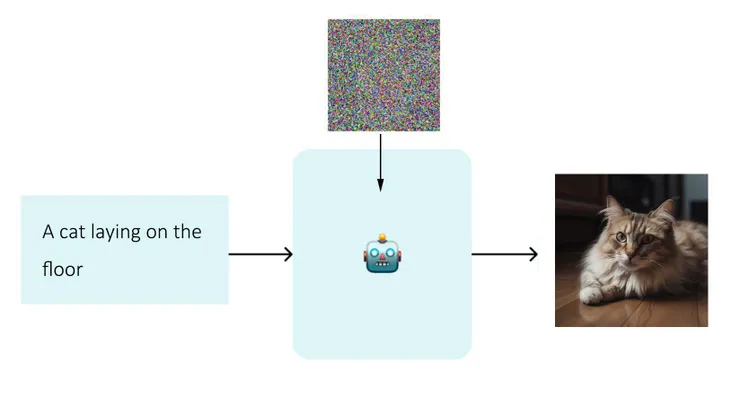
當我們餵給AI一段文字,加上一整張的雜訊的時候,他就可以把雜訊依照我們給的文字內容,"還原"成一張AI產出來的畫作了,是不是很神奇呢? 而且依照我們給的文字內容跟各種參數調校,產生出比原來的原始照片要漂亮很多的圖片都是非常有可能的。
目前的Diffusion model 依照餵給他訓練的圖片是什麼,就可以產出各式各樣不同的風格,畢竟”AI是看這些圖片長大的" 餵給他很多動漫風格的圖片,將來他產出來的圖片就會充滿動漫風格,如果給他看很多真實的照片,那麼這樣的AI model產出來的就會是非常擬真的圖片,甚至以假亂真。我們將來在其他篇裡面也會介紹到,不同資料訓練出來的AI model ,用同樣的文字可以產生出很多不同的結果。 希望以上的介紹,能夠幫助大家多少多了解一些AI怎麼學會畫圖的,我們下次見囉。

























