最近因為內部有一些關於K8S網路上的一些問題,所以花了一點時間了解到底在Kubernetes cluster內部到底不同類型的資源是如何進行溝通的,仔細看完網路上許多大神的文章後,整理在一起並加入一些我的想法,給自已也給大家一個需要時可以參考的記錄。

以下是本篇所要說明的幾個重點:
- K8S網路基本概念
- 容器 — 容器
- Pod — Pod
- Pod — Service
- External — Service
- 服務如何發現
- 服務的類型
- 結論
1.K8S網路基本概念
kubernetes networking是設計來讓K8S內運行的實體可以相互溝通。K8S是透過許多的分層級設計(Namespace/Pod/Container)來做彼此的區別,因此相互溝通的做法在K8S是非常重要的。
※ 基本上K8S網路是針對以下需求去進行設計:
- 在不使用NAT的方式下,Pod之間要能溝通
- 在不使用NAT的方式下,所有節點的Pod要能相互溝通
- Pod 認為自己的 IP 與其他 Pod 認為的 IP 相同
所以根據以上三種需求加上所謂分層級的設計理念,所以發展出接下來說明的幾種情境。
2.容器 — 容器
容器間的網路是在Pod network namespace內產生。Network namespace讓網路介面與路由可以從整個系統做到抽離與獨立運行。每個Pod都有自已的Network namespace與container。在同一個Pod內部會共享同一個IP與Port。下圖的綠線說明了同一個Pod內的二個Container的相互溝通。
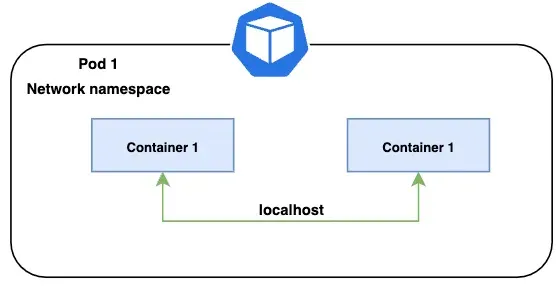
container interaction
在Linux內,我們可以透過ip指令切出network namespace該程序在這個邏輯命名空間內運行屬於這個空間的路由、防火牆規則、網路介面。所以,network namespace等於是處在同一個命名空間內的所有程序建立一個全新的網路Stack。
[root]# ip netns add ns1
[root]# ls /var/run/netns
ns1
[root]# ip netns
ns1
其實Linux本身其實就會建立一個Root network namespace,並將所有的程序都指派在這個netns之內,來接受外界所有的流量。
3.Pod — Pod
在K8S Cluster內部,每個節點都會有指定好的IP範圍來提供給Pod使用。確保每個Pod都會有一個唯一的IP(真實IP)位置。當一個新的Pod建立後,不會拿到已經有人在使用的IP位置。不像是容器對容器的網路直接在內部就交換完畢,Pod-to-Pod的溝通使用IP,不論將Pod部署在同一個節點或是不同的節點。
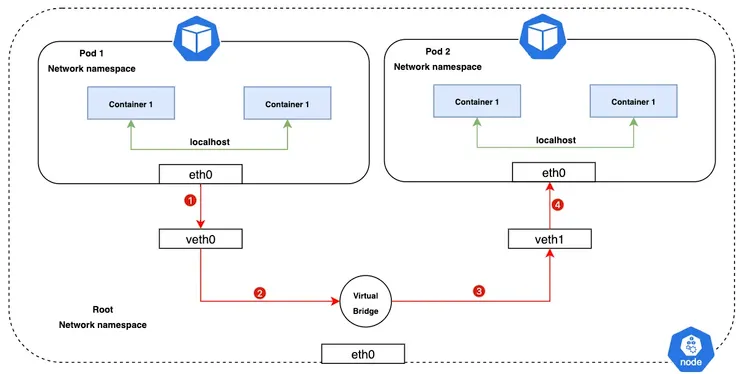
Pod-to-Pod Networking
上圖顯示Pod是如何相互溝通。透過virtual ethernet device or veth pair(veth0/veth1) 來實現流量在Pod network namespace與root network namespace之間的移動。Virtual Bridge (L2)會連接這些虛擬介面,允許流量透過ARP來進行移動。
veth0 & veth1 實現veth pair
Virtual Bridge會負責檢查透過的封包目的地來決定是否要轉送到已連接的其他網段,並且負責維護這個轉發表,透過檢查MAC來決定是否要drop。
接著,我們來看看如果資料要從Pod1流向Pod2的流程(同節點的移動)流程(參考上圖):

Step1. Pod1的流量透過eth0往Root network namespace的虛擬介面veth0
Step2. 流量透過veth0流向virtual bridge,這個virtual bridge與veth1連接(在L2層級,使用ARP協定來發現與廣播到所有相連的介面)
Step3. 流量透過virtual bridge流向veth1(透過arp table定義誰要回應)
Step4. 流量抵達Pod2的eth0
了解同一個節點內資料的流動方式之後,讓我們再來看一下如何要到其他節點的話,該怎麼流動:
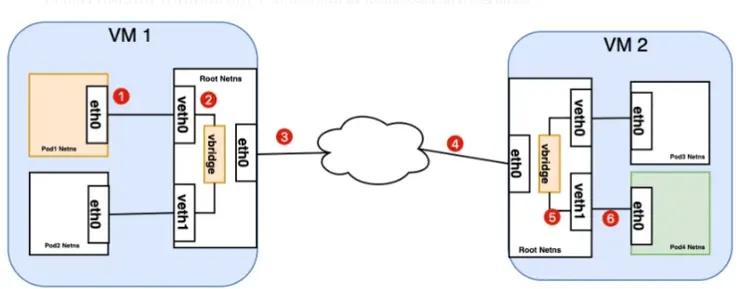
S1. 封包從Pod1出發,走到vbridge後因為找不到連接的目的地,所以bridge將封包往default route(eth0),此時封包就準備要離開這個節點。
S2. 假設網路環境是可以將這個IP正確路由到對的節點
S3. 封包進入另一個節點的root namespace,並且透過virtual bridge連結到正確的veth1
S4. 透過veth pair正確將封包傳到Pod4的eth0
4.Pod — Service
Pod是一個非常動態的元件。因為可能會有動態的擴展、也可能因為應用服務的需求而需要重新建立。這些情況可能導致Pod IP改變,會導致服務有無法使用的挑戰。
Kubernetes透過Service的方式來解決這個問題,透過以下做法:
- Service會在前端被指派一個靜態的虛擬IP,用來連接所有後端的Pod
- 這個虛擬IP會負載平衡所有要到後端Pod的流量
- 持續追蹤Pod的IP位置(就算是Pod IP 改變),因為外部使用者只會連結到前端的Service vip。
上述的負載平衡會用以下二種方式實現:
- IPTABLES:kube-proxy監看API Server的變化,當新的Service產生,就將Iptables rules塞進去。由規則捕捉往Service Cluster IP與Port的流量。並且重導至後端的Pod。要往那個後端Pod流動是隨機選擇。這個模式是可信賴的並且有較低的系統負載。
- IPVS:IPVS是建構在Netfilter與傳輸層之上的負載平衡。IPVS會使用Netfilter hook功能,使用hash table做為低層的資料結構並且在核心空間運行。表示kube-proxy使用IPVS模式會用低延遲、高輸出、最佳效能的方式將流量重導,比IPTABLES模式更佳。
下圖說明Pod to Service的流動方向:
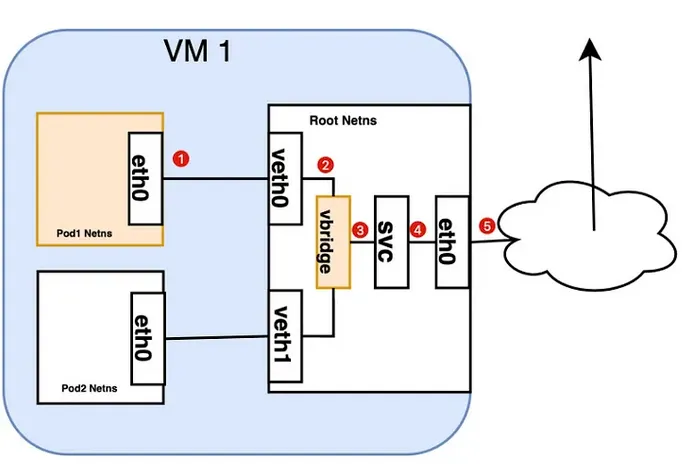
(1) 封包從Pod namespace的eth0出去
(2) 在vbridge上的ARP協定不知道Service的存在
(3) vbridge只會將封包往default route名為eth0方向流出
(4) 當封包進入SVC時,iptables 使用 kube-proxy 在節點上安裝的規則來回應 Service 或 Pod 事件,將封包的目的地從 Service IP 重寫到特定的 Pod IP
(5) iptables 利用 Linux 核心的 conntrack 實用程式來記住所做的 Pod 選擇,以便將未來的流量路由到同一個 Pod(禁止任何擴展事件)。本質上,iptables直接在Node上做了叢集內的負載平衡
反過來,如果是Service to Pod,當封包進入Iptables之後,判斷目的IP是那個Pod,SVC會將SRC修改成SVC的IP,讓封包繼續往目的Pod的方向前進。
5.External — Service
以上我們說明了在Cluster內部的流動方式,接下來我們來說明應用服務暴露到外部網路的情境,以方向來說明,分成Egress 與 Ingress二個方向:
- Egress(內->外) :
從Cluster內部流向外部。將這個情況Iptables會實作source NAT,在流量上的呈現會是來自已節點而非Pod。
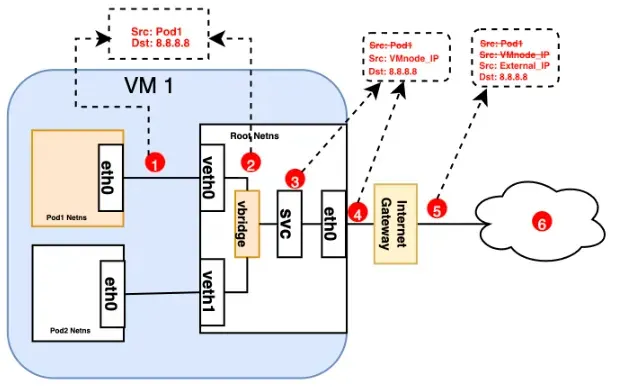
流程如下:
Step1. 封包從Pod namespace出發,透過veth pair連接到root namespace
Step2. vbridge因為Dst IP 沒有在記錄內,所以透過default route流出
Step3. SVC進行source NAT將Pod IP轉換成VM IP(如果持續保持source ip為Pod IP的話,到Internet gateway會被丟掉,因為只認得VM ip)
Step4. 因為已經完成source NAT,就可以被internet gateway接受
Step5. Internet Gateway會再將VM internal ip,再做一次NAT將其改成external IP,然後往Internet移動
Step6. 返回時,封包將遵循相同的路徑,所有來源IP的 修改都會被撤消,以便讓系統的每一層都可以收到可以理解的IP 位址:節點或VM 等級的VM 內部,以及Pod 內部的Pod IP 。命名空間。
- Ingress (外-> 內):
從外部網路流入Cluster的Service。Ingress也可以允許或阻擋特定的連線(透過規則)。有以下二種方式:
(1) Service Load Balancer(L4):建立一個Cloud controller,當Service一建立,就會連動到Loadbalancer,由Loadbalancer配發一個IP,使用者就可以開始將流量導至Loadbalancer,讓Loadbalancer來與Service溝通。
如果私有不對外環境,可以使用先前介紹過的Metallb來實現。
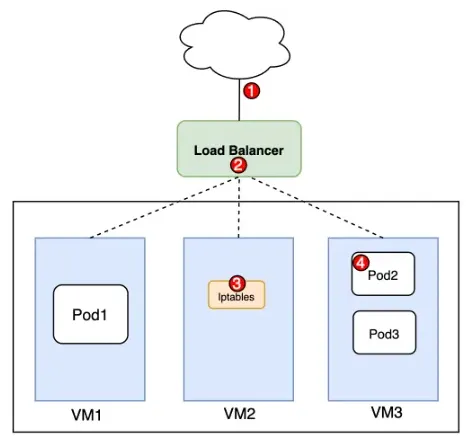
Step1. 將封包導向Loadbalancer
Step2. 由Loadbalancer隨機選擇一個VM節點
Step3. 在被選中的VM節點上,透過內部的Loadbalancer(ex. Kube-proxy)規則來將封包導到正確的Pod
Step4. 由iptables執行正確的NAT將封包導流到正確的Pod
(2) Ingress Controller (L7):網路堆疊的 HTTP/HTTPS 協定範圍上運行,並且在Service之上運行,例如NodePort。
6.服務如何發現
Kubernetes使用以下二種方式來發現Service:

- 環境變數:
kubelet服務來設定環境變數給每個運行中的服務(透過 {SVCNAME}SERVICE_HOST 與 {SVENAME}SERVICE_PORT),如果使用這種方式的話,Service就要在Pod建立之前先建立好,不然Pod建立時就不會將變數塞入。
2. DNS:DNS service作為kubernetes服務的方式部署在K8S內。這個服務會對應一到多個DNS server pod,所有在cluster內的Pod在啟動時候會被設定來使用這個DNS service,所以DNS搜尋清單就會包含Pod namespace與Cluster default domain。
一個Cluster感知的DNS,例如CoreDNS,會去監控K8S API是否有新的Service建立,並且同步建立新的DNS記錄。如果有啟用DNS,所有的Pod就能夠透過自已的DNS名稱自動解析Service。同時,Kubernetes DNS Server也是唯一可以存取ExternalName Service的方式。
7.服務的類型
Kubernetes Service提供一個可以存取整組Pod的方法,實作上通常會使用label selector來搭配使用。應用服務可能要存取同一個Cluster內其他應用服務,或是將應用服務暴露給外部世界。Kubernetes Serivcetype 可以讓你指定用什麼方式將Service暴露出來。
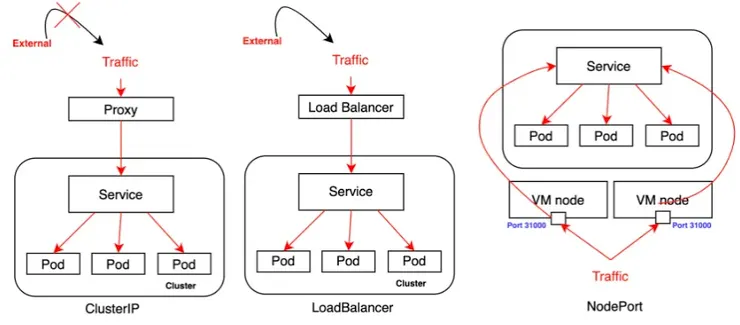
- ClusterIP: 預設的Service Type,只允許在同一座cluster內的Application service相互溝通,無法接受外部連線。
- LoadBalancer: 需要
Cloud Load balancer provider,流量會從外部的Load Balancer直接抵達後端Pod,由Cloud LB來決定流量要怎麼流動。 - NodePort : 透過在所有節點上開啟特定的Port,讓外面的服務可以透過指定Port的方式將流量轉發至Service後,再根據規則將流量送到後端Pod
8.結論
本文說明了幾種K8S內部網路溝通的幾種基本概念,從最小的容器到內部網路與外部網路是如何進行溝通的流程,這些概念對於在管理K8S時,如果有服務無法連線時非常有幫助,除了可以在建立Service時可以指定正確的位址,也可以透過Label來定義負載要如何平均分配到那些Pod上運行。
了解這些基本概念對於管理K8S Cluster是極度重要的,個人經驗許多問題其實一開始就可以避免,但是因為基本概念不夠紮實,導致在維運時會出現許多不必要的麻煩。
最後,感謝大家的閱讀,我們下次再見~~~

References:





















