還有其他套件可使用 PyPDF2、 pdf2image,有嘗試過 pdf2image 對部分中文會消失。
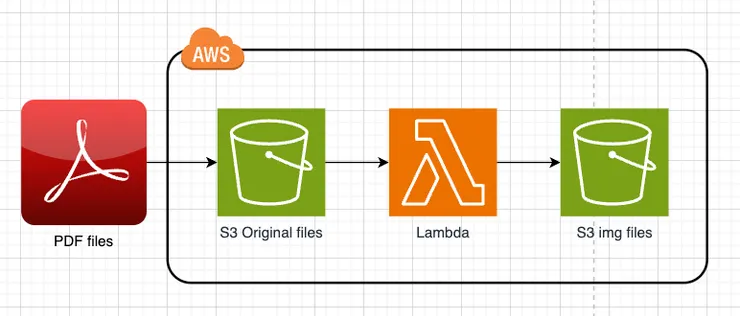
執行過程為,將 PDF 檔案上傳至 S3 Bucket > 觸發 AWS Lambda 轉換檔案 >把結果圖片放置到 S3 Bucket
這裡的 Lambda 採用 docker image 來建置,將程式碼和相依性打包到 Docker 映像中。 Dockerfile 應包含程式碼正確運作所需的依賴項和環境設定。
因此,我決定嘗試使用 Docker 建立自己的環境,由於它可以從一開始就安裝在執行環境中,因此不再需要使用 Lambda Layer。
設定部署環境
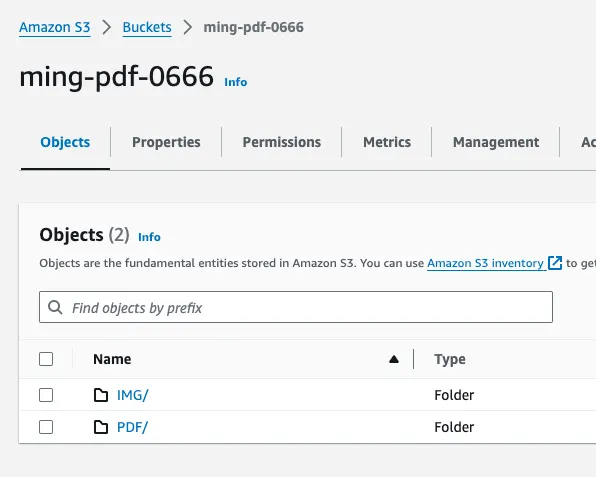
步驟1:建立 S3 Bucket
創建兩個資料夾,來放PDF與輸出的圖片檔
步驟2:編寫 Python 程式碼
app.py
import boto3
import fitz # PyMuPDF
import concurrent.futures
# 創建 S3 存儲桶中的資料夾
def create_folder(s3_client, bucket_name, folder_name):
s3_client.put_object(Bucket=bucket_name, Key='IMG/' + folder_name + '/')
# 將 PDF 頁面轉換為 JPG 圖像
def convert_page_to_jpg(s3_client, page, folder_name, bucket_name, object_key):
pixmap = page.get_pixmap(dpi=400) #DPI影響轉換速度
img = pixmap.tobytes()
# 將 JPG 圖像上傳至 S3,檔案名稱包含物件名稱和頁碼
s3_client.put_object(Bucket=bucket_name, Key=f'IMG/{folder_name}/{object_key.split("/")[-1].split(".")[0]}-page-{page.number}.jpg', Body=img)
# 將整個 PDF 轉換為 JPG 圖像
def convert_pdf_to_jpg(s3_client, pdf_doc, folder_name, bucket_name, object_key):
with concurrent.futures.ThreadPoolExecutor() as executor:
# 使用多執行緒處理 PDF 的每一頁
executor.map(lambda page: convert_page_to_jpg(s3_client, page, folder_name, bucket_name, object_key), pdf_doc)
# 處理 S3 事件
def handle_s3_event(event, context):
# 創建 S3 客戶端
s3_client = boto3.client('s3')
# 獲取 S3 事件相關資訊
bucket_name = event['Records'][0]['s3']['bucket']['name']
object_key = event['Records'][0]['s3']['object']['key']
# 從 S3 中獲取 PDF 文件
obj = s3_client.get_object(Bucket=bucket_name, Key=object_key)
pdf_content = obj['Body'].read()
# 使用物件名稱作為資料夾名稱
folder_name = object_key.split('/')[-1].split('.')[0]
# 創建資料夾,存轉換後的圖像
create_folder(s3_client, bucket_name, folder_name)
# 使用 PyMuPDF 開啟 PDF 文件
pdf_doc = fitz.open(stream=pdf_content)
# 將 PDF 轉換為 JPG 並上傳至 S3
convert_pdf_to_jpg(s3_client, pdf_doc, folder_name, bucket_name, object_key)
def handler(event, context):
try:
# 處理 S3 事件
handle_s3_event(event, context)
print("Successfully converted PDF to JPG and uploaded to S3")
except Exception as e:
# 處理錯誤,並拋出異常
error_msg = "An error occurred: {}".format(e)
print(error_msg)
raise Exception(error_msg)
步驟3:編寫 Dockerfile
FROM public.ecr.aws/lambda/python:3.12
RUN pip3 install PyMuPDF boto3
# Copy function code
COPY app.py ./
CMD [ "app.handler" ]
步驟4:建立AWS ECR
步驟5:將 Docker Image推送到 AWS ECR,這裡採用Cloud 9
步驟6:建立 Lambda 函數
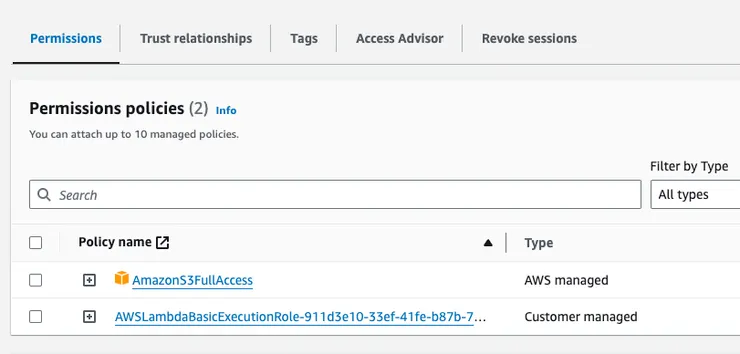
必須新增權限角色以允許 Lambda 存取 S3,這裡為了方便使用 AmazonS3FullAccess
步驟7 : 設置Memory 與 Timeout,根據檔案實際情況調整,
檔案大小、頁面複雜度都會影響。
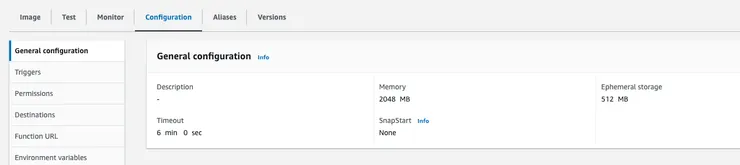
步驟8 : 設置觸發來源
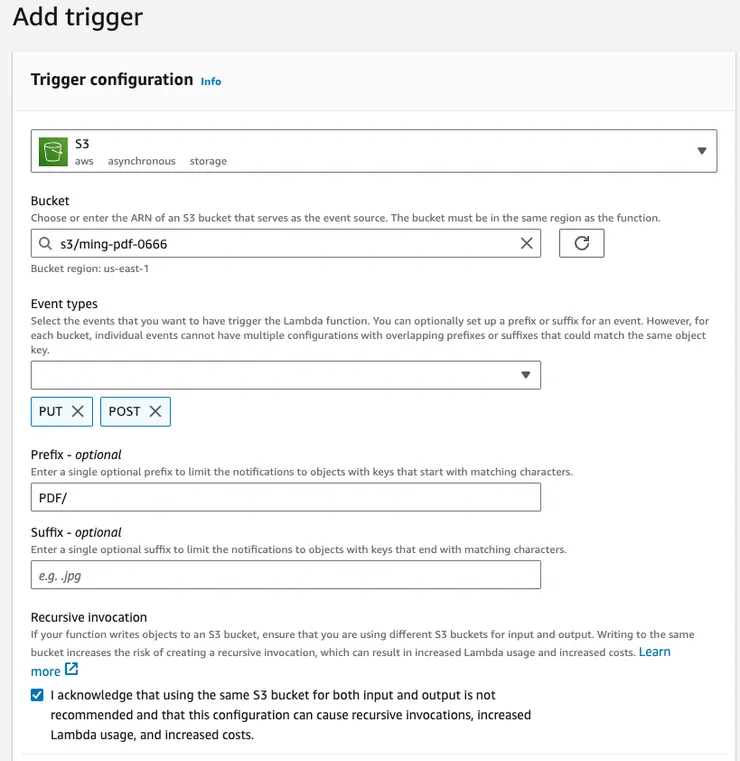
步驟9 : 觸發 Lambda 測試
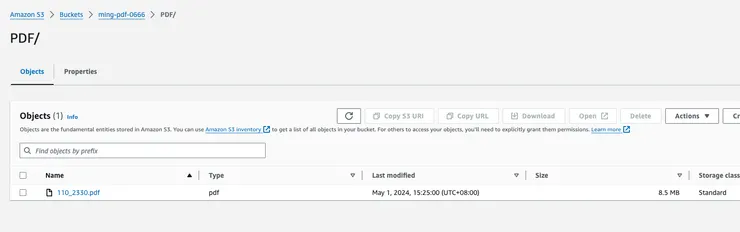
為了檢查轉換過程是否正常,我們將 PDF 檔案上傳到 S3 儲存桶並讓 Lambda 函數對其進行轉換。該過程完成後,我們將檢查輸出以確保其符合我們的期望。
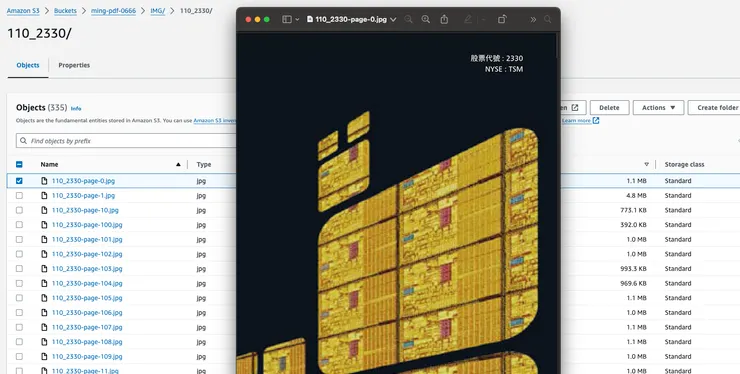
這裡以台積電年報為例,請注意 pdf 檔名不能中文
Billed Duration: 281148 ms Max Memory Used: 995 MB
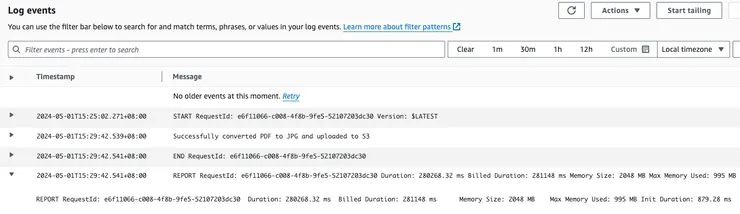
可以看到結果還是可以
結論
將PDF轉換為圖像對於各行各業和企業都是一項極具價值的工具。透過AWS Lambda和Docker的部署,能夠高效地實現這一轉換,無論是用於在網站上展示PDF或進一步處理,都無需煩惱基礎設施管理的問題。儘管有許多其他在線工具可供選擇,但利用AWS Lambda和Docker提供了一個強大且可擴展的解決方案。
參考
https://pymupdf.readthedocs.io/en/latest/
https://note.leoxyz.com/post/convert-pdf-to-image-with-aws-python-lambda-function-and-docker-deployment



















