前言
承上一篇筆記文章,繼續閱讀推薦的第二篇論文:Identity Mappings in Deep Residual Networks—Kaiming He、Xiangyu Zhang、Shaoqing Ren、Jian Sun。也是一樣的發表者,內容是對他們之前發表的Deep Residual Learning for Image Recognition—Kaiming He、Xiangyu Zhang、Shaoqing Ren、Jian Sun,這篇論文提出更精進的版本。
正文
深度殘差網路(ResNets)由許多堆疊的"殘差單元"組成。每個單元(下圖(a),為上一篇論文提出;而下圖(b)為此篇論文提出)可以用一般形式表示(下下一張圖):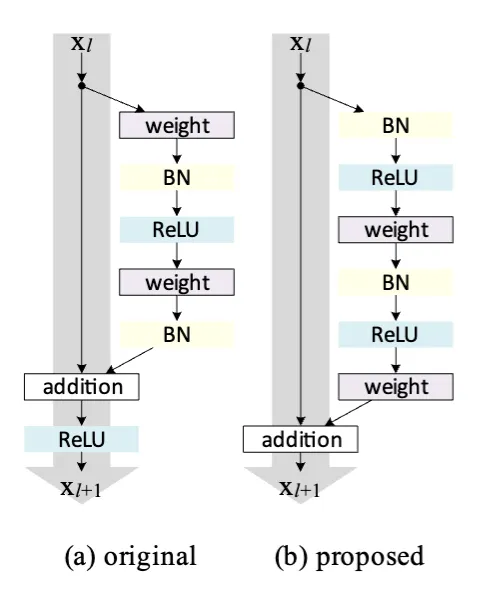
來源:https://arxiv.org/abs/1603.05027
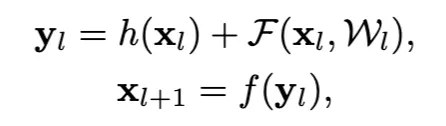
來源:https://arxiv.org/abs/1603.05027
其中 xl 和 xl+1 分別是第 l 個單元的輸入和輸出,而 F 是殘差函數。在上一篇論文中,h(xl) = xl 是一個恒等映射,f 是一個 ReLU 函數。在這篇論文中,Kaiming He等人通過專注於創建一條"直接"傳播信息的路徑來分析深度殘差網路——不僅在殘差單元內,而且貫穿整個網路。Kaiming He等人的推導顯示,如果 h(xl) 和 f(yl) 都是恒等映射,則信號可以在前向和後向傳播中直接從一個單元傳播到任何其他單元。Kaiming He等人的實驗實證表明,當架構更接近上述兩個條件時,訓練會變得更容易。
這裡 Wl = {Wl,k|1≤k≤K} 是與第 l 個殘差單元相關的一組權重(和偏置),K 是一個殘差單元中的層數(在上一篇論文中,K 是 2 或 3)。F 表示殘差函數,例如上一篇論文中兩個 3×3 卷積層的堆疊。函數 f 是元素級相加之後的操作,在上一篇論文中,f 是 ReLU。函數 h 被設置為一個恆等映射:h(xl) = xl。如果 f 也是恆等映射:xl+1 ≡ yl,可以將上圖第二條方程式代入上圖第一條方程式裡得到:

來源:https://arxiv.org/abs/1603.05027
遞迴地(xl+2 = xl+1 + F(xl+1, Wl+1) = xl + F(xl, Wl) + F(xl+1, Wl+1),等等),將得到:
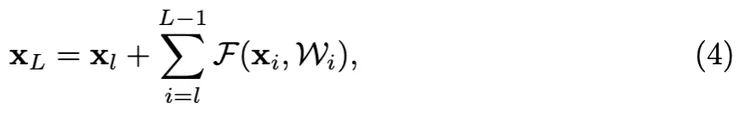
來源:https://arxiv.org/abs/1603.05027
對於任何更深的單元 L 和任何更淺的單元 l。方程式(4)展示了一些好的特性:(i) 任何更深單元 L 的特徵 xL 可以表示為任何更淺單元 l 的特徵 xl 加上一個殘差函數的和,表明模型在任何單元 L 和 l 之間是殘差形式。(ii) 任何深層單元 L 的特徵 xL,是所有前面殘差函數輸出的總和(加上 x0)。這與"普通網路"中特徵 xL 是一系列矩陣-向量乘積的情況形成對比。
方程式(4)也帶來了好的反向傳播特性。從反向傳播的鏈式法則中有:
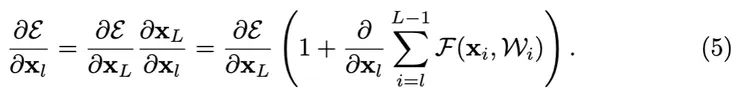
來源:https://arxiv.org/abs/1603.05027
方程式(5)表明梯度可以分解成兩個可加的項:等式最右邊的第一項,直接傳播信息而不考慮任何權重層,確保了信息能夠直接傳播回任何更淺的單元 l。第二項通過權重層傳播,這一項不會總是對所有 xl 為 -1。這意味著即使權重非常小,一層的梯度也不會消失。
方程式(4)和方程式(5)表明信號可以在任意單元之間直接傳播,既可以正向傳播,也可以反向傳播。方程式(4)的基礎是兩個恒等映射:(i) 恒等跳躍連接 h(xl) = xl,和 (ii) 條件是 f 是一個恒等映射。
這些直接傳播的信息流由第一張圖中的灰色箭頭表示。當這些灰色箭頭不涉及任何操作(除了加法)時,上述兩個條件成立,因此它們是"乾淨"的。在接下來的兩個部分中,Kaiming He等人分別探討這兩個條件的影響。
接著,Kaiming He等人進行修改恒等跳躍連接的實驗,變異分別為下圖:
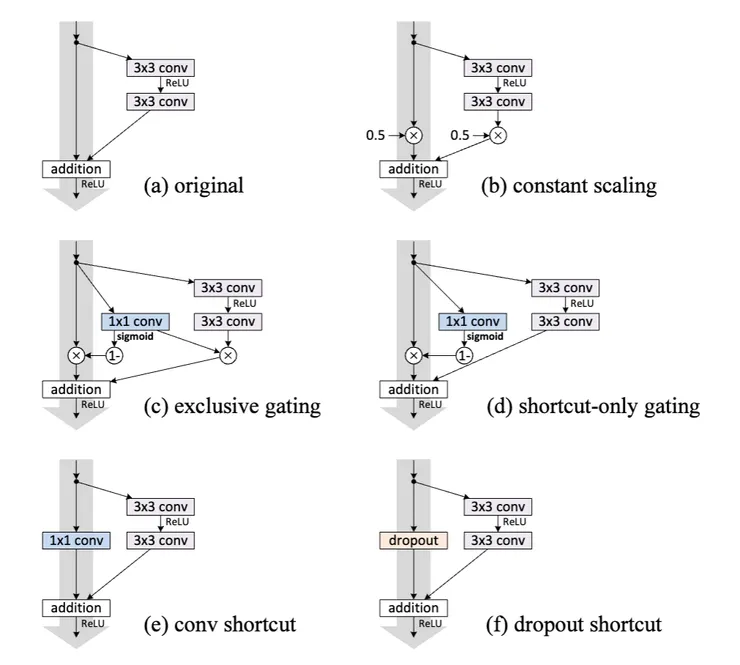
來源:https://arxiv.org/abs/1603.05027
實驗結果如下圖,Y軸為訓練損失指標:
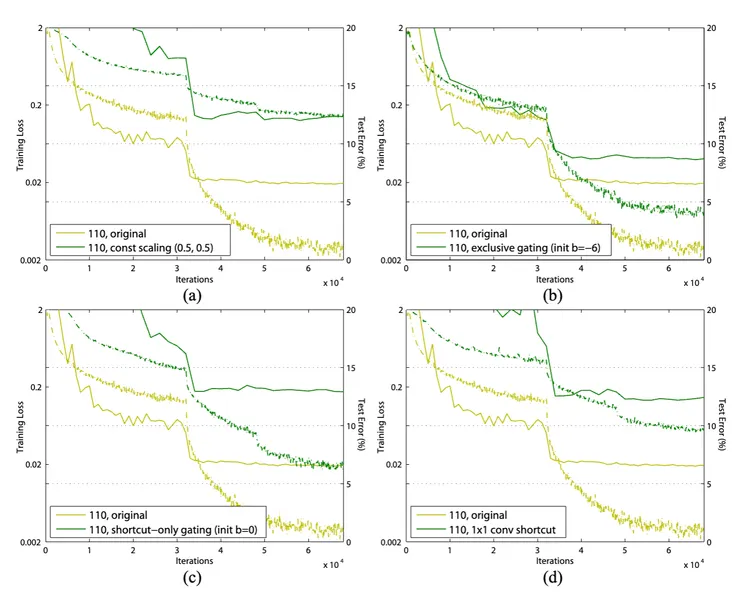
來源:https://arxiv.org/abs/1603.05027
結論是,如本文第一張圖中的灰色箭頭,捷徑連接是信息傳播的最直接路徑。對捷徑進行如上上圖的乘法操作(縮放、門控、1×1 卷積和 dropout)會阻礙信息傳播並導致優化問題,訓練損失比較如上圖。
接著,Kaiming He等人進行激活函數的實驗。若希望將 f 設置為恒等映射(下圖(c)、(d)、(e)),可以通過重新排列激活函數(ReLU 和/或 BN)來實現。實驗的變異如下圖:
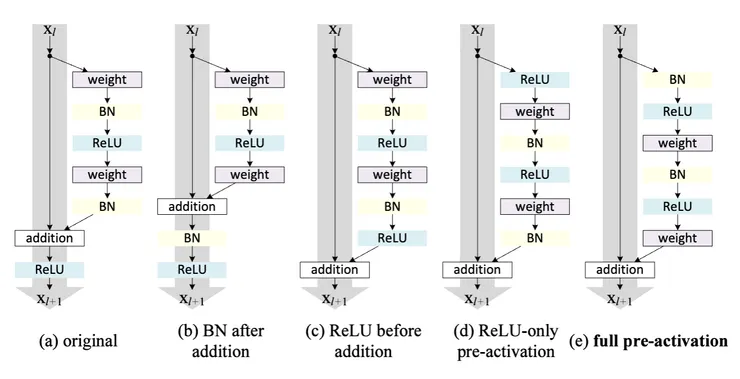
來源:https://arxiv.org/abs/1603.05027
對於上圖(d)和(e),通過兩種設計進行實驗:(i) 只有 ReLU 的預激活,(d);和 (ii) 全預激活,其中 BN 和 ReLU 都在權重層之前採用,(e)。而預激活,Kaiming He等人發展了一種不對稱形式,其中一個激活只影響 F 路徑,下圖(a)到(b):
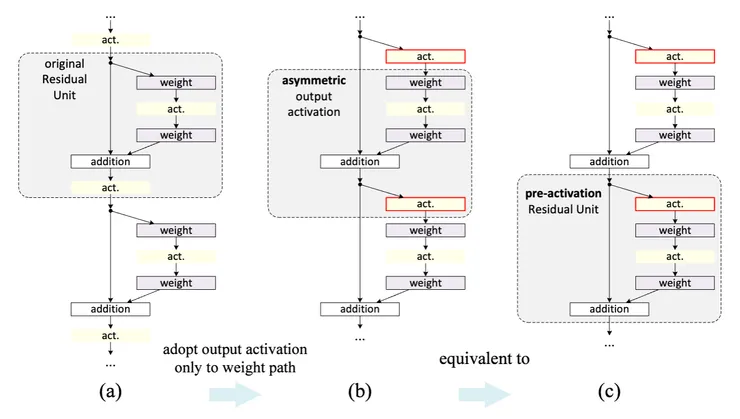
來源:https://arxiv.org/abs/1603.05027
實驗發現,當 BN 和 ReLU 都作為預激活使用時,結果顯著改善,如下圖(數值為分類錯誤率):
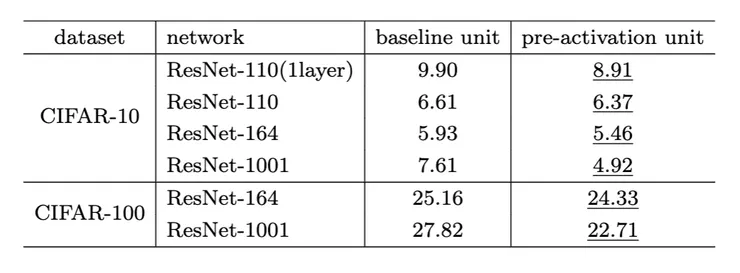
來源:https://arxiv.org/abs/1603.05027
發現預激活的影響是雙重的。首先,與上一篇論文基準的 ResNet (上上上圖(a))相比,優化進一步簡化了,因為 f 是一個恆等映射。其次,使用 BN 作為預激活改善了模型的正則化效果。
優化的簡化:使用上一篇論文中的原始設計(上上上圖(a)),訓練誤差在訓練初期下降非常緩慢。對於 f = ReLU,如果信號是負的,那麼當有許多殘差單元時,這種效應會變得顯著。相反地,當 f 是一個恆等映射時,信號可以在任意兩個單元之間直接傳播。這篇論文的 1001 層網路非常快速地降低了訓練損失,表明了優化的成功。
減少過度擬合:在原始的殘差單元中(上上上圖(a)),儘管 BN 對信號進行了歸一化,但這很快被添加到快捷路徑中,因此合併後的信號並沒有被歸一化。然後,這個未歸一化的信號被用作下一個權重層的輸入。相反地,在我們的預激活版本中(上上上圖(e)),所有權重層的輸入都已經被歸一化。
此篇論文研究了深度殘差網路連接機制背後的傳播公式。推導表明,跳躍連接和激活對於使信息傳播平穩至關重要。實驗展示了可以輕鬆訓練並實現改進精度的 1000 層深度網路。
參考
- Identity Mappings in Deep Residual Networks—Kaiming He、Xiangyu Zhang、Shaoqing Ren、Jian Sun
- ChatGPT
小結
讀完了兩篇論文,覺得對殘差網路有比較了解了,接下來會配合書中的範例程式,實際動手玩玩看。然後想說的是,最近不是在忙工作就是在睡覺,沒有出現在方格子和各位格友互動不好意思(XD)。最後,繼續趕路,繼續留腳印(XD),週末快樂!


















