SO-VITS-SVC實戰經驗分享:從零開始打造我的專屬AI歌手_數據集準備與環境部署
AI唱歌系列之二-數據集準備與環境部署
本篇要介紹的是so-vits-svc,使用的是so-vits-svc4-1版本。
原文來自:
以下內容會包括我在使用過程中遇到的問題,以及解決方法。

重要通知:
這個項目是為了讓開發者最喜歡的動畫角色唱歌而開發的,任何涉及真人的東西都與開發者的意圖背道而馳。
聲名:
本專案為開源、離線的項目,SvcDevelopTeam 的所有成員與本專案的所有開發者以及維護者(以下簡稱貢獻者)對本專案沒有控制力。本計畫的貢獻者從未向任何組織或個人提供包括但不限於資料集擷取、資料集加工、算力支援、訓練支援、推理等一切形式的幫助;本計畫的貢獻者不知曉也無法知曉使用者使用該物品的用途。故一切基於本計畫訓練的 AI 模型和合成的音訊都與本計畫貢獻者無關。一切由此造成的問題由使用者自行承擔。
此項目完全離線運行,不能收集任何使用者資訊或取得使用者輸入資料。因此,這個專案的貢獻者不知道所有的使用者輸入和模型,因此不負責任何使用者輸入。
本項目只是一個框架項目,本身並沒有語音合成的功能,所有的功能都需要使用者自己訓練模型。同時,這個項目沒有任何模型,任何二次分發的項目都與這個項目的貢獻者無關。
使用約規:
Warning:請自行解決資料集授權問題,禁止使用非授權資料集進行訓練!任何因使用非授權資料集進行訓練所造成的問題,需自行承擔全部責任和後果!與倉庫、倉庫維護者、svc develop team 無關!
- 任何發佈到視頻平台的基於sovits 製作的視頻,都必須要在簡介明確指明用於變聲器轉換的輸入源歌聲、音頻,例如:使用他人發布的視頻/ 音頻,通過分離的人聲作為輸入源進行轉換的,必須要給予明確的原始影片、音樂連結;若使用是自己的人聲,或是使用其他歌聲合成引擎合成的聲音作為輸入來源進行轉換的,也必須在簡介加以說明。
- 本計畫是基於學術交流目的而建立,僅供交流與學習使用,並非為生產環境準備。
- 由輸入來源造成的侵權問題需自行承擔全部責任及一切後果。使用其他商用歌聲合成軟體作為輸入來源時,請確保遵守該軟體的使用條例,注意,許多歌聲合成引擎使用條例中明確指明不可用於輸入來源進行轉換!
- 禁止使用該項目從事違法行為與宗教、政治等活動,該項目維護者堅決抵制上述行為,不同意此條則禁止使用該項目。
- 繼續使用視為已同意本倉庫 README 所述相關條例,本倉庫 README 已進行勸導義務,不對後續可能有問題負責。
- 若將此項目用於任何其他企劃,請事先聯絡並告知本倉庫作者,十分感謝。
訓練需求
1. 環境需求與硬體建議
硬體建議:
- GPU:必須使用NVIDIA顯卡,顯存至少6GB,並安裝CUDA。
- 虛擬內存:至少設置30GB以上,並最好儲存在固態硬碟(SSD),否則速度會很慢
﹡電腦配備不足的可以使用雲端訓練。
AutoDL算力雲(下面會再介紹如何使用)。
Google Colab(有能力自己部署的,colab可以使用SOVITS4_for_colab.ipynb. 進行配置)。 - 操作系統:建議使用windows 10/11或Linux(雲端訓練請選擇linux)。
推理環境:
推理對硬體要求較低,可使用 CPU,但速度會較慢。支持命令行推理和 WebUI 推理。
訓練注意事項:
• 訓練過程中顯卡負載極高,可能持續數小時,建議避免同時使用電腦。
• 如果需要使用電腦,建議選擇雲端訓練(如 Autodl 或 Google Colab)。
2. 提前準備
- 訓練:目標說話人的授權數據集(至少30分鐘的乾淨純人聲/歌聲,1-2小時為最佳)。我一開始數據集質量不好,導致我重新訓練了4次...。(關於數據集會在另外說明,因為需要注意的部分很多)。
- 推理:請準備底噪小於30db,盡量不要有混響與和聲的乾淨『乾聲』。
※注意,推理歌聲請盡量用相同性別的數據。 - 重要!請事先下載好底模。底模可參考222-預訓練底模-强烈建議使用。
- 如要本地訓練,請事先安裝好環境依賴。
本項目需要的依賴:
NVIDIA-CUDA。
Python = 3.8.9(项目建議此版本)。
Pytorch(cuda版,非cpu版) 。
FFmpeg。
3. 如何製作數據集詳細步驟請參考:
用 SO-VITS-SVC 打造 AI 歌姬,零基礎也能輕鬆上手!-數據集的錄製與準備
用 SO-VITS-SVC 打造 AI 歌姬,零基礎也能輕鬆上手-數據預處理
注意事項:
- 格式必須為WAV.
- 切片語音每條時長最好在5-15秒。(最短不低於3秒,最長不高於17秒)。
- 數據集要確保按照上面的說明處理成乾淨的乾聲,就算只帶有一點的雜音都會影響訓練好的模型。想要模型能推理出高音質的數據,請務必在準備數據集的時候不要偷懶。 否則訓練出的模型無法用,還得重新再來過,更耗時耗力。
4. 環境依賴安裝
4-1.so-vits-svc4.1 源碼
使用 git 拉取源碼。通過以下命令:
git clone https://github.com/svc-develop-team/so-vits-svc.git
4-2.CUDA
- 更新Nvidia顯卡驅動至最新。
- 在 cmd 控制台輸入 nvidia-smi.exe 以查看顯卡驅動版本和對應的 cuda 版本。
- 前往NVIDIA-CUDA官網下載與系統對應的CUDA版本。
- 依照自己的系統需求選擇安裝(一般本機 Windows 使用者請依序選擇 Windows , x86_64 , 系統版本 , exe(local) )。
- 安裝成功之後在 cmd 控制台中輸入 nvcc -V , 出現類似以下內容則安裝成功:
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2022 NVIDIA Corporation
Built on Tue_May__3_19:00:59_Pacific_Daylight_Time_2022
Cuda compilation tools, release 11.7, V11.7.64
Build cuda_11.7.r11.7/compiler.31294372_0
※ 注意事項:
- nvidia-smi.exe 中顯示的 CUDA 版本號碼具有向下相容性。例如我顯示的是 12.4,但我可以安裝 <=12.4 的任一版本 CUDA 版本來安裝。
- CUDA 需要與下方 1.4 Pytorch 版本相符。
- CUDA 卸載方法:開啟控制台-程序-卸載程序,將有 NVIDIA CUDA 的程序全部卸載即可(一共 5 個)。
4-3.Python
python版本:3.8版本。
版本過高會導致依賴安装不上。
- 前往python官網下載 Python3.8.9 安裝,若python環境還需要應用於其他項目,則進入SVC目錄,創建python3.8.9的虛擬環境,後續每次使用時首先激活該虛擬環境再行其他操作。
# 进入SVC目录
cd D:/so-vits-svc/
# python虚拟环境创建
xxxx/python-3.8.9/python.exe -m venv 虚拟环境名
# 此后每次使用前,先执行activate脚本激活虚拟环境
D:/so-vits-svc/venv/Scripts/activate
- 安裝完成後在 cmd 控制台中輸入 python 出現類似以下內容則安裝成功:
Python 3.8.9 (tags/v3.8.9:9d38120, Mar 23 2022, 23:13:41) [MSC v.1929 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>>
4-4.pytorch安装:
※ 此處安裝的 Pytorch 需要與安裝的 Cuda 版本相符。例如:安裝的cuda為11.7,則下載的pytorch則需要是符合cu117的版本。
參考以下文章:
Anaconda安裝pytorch(GPU和CPU)超簡單的兩種方法-CSDN博客。
※ 安裝 torch , torchaudio , torchvision 這三個函式庫之後,在 cmd 控制台運用下列指令偵測 torch 能否成功呼叫 CUDA。最後一行出現 True 則成功,出現 False 則失敗,需要重新安裝正確的版本。
python
# 回车运行
import torch
# 回车运行
print(torch.cuda.is_available())
# 回车运行
4-5.FFmpeg安装:
- 下載
進入之後點選下載,選擇自己的版本,我是windows。
- 安裝
下載好後解壓縮到一個自己不常動的資料夾。開啟bin目錄,複製此路徑。
如我的路徑:D:\1863\ffmpeg-2024-11-28-git-bc991ca048-full_build\bin
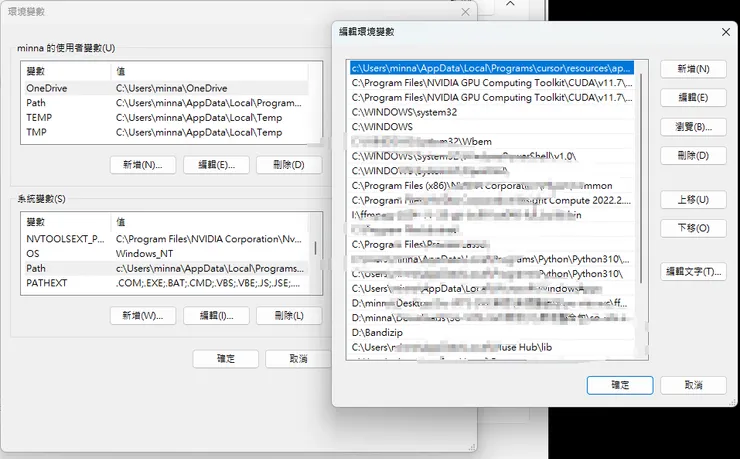
將此路徑添加到環境變量:
此電腦 > 右鍵 > 屬性 > 進階系統設定 > 環境變數 > 點開path > 新建 > 貼上路徑。
然後一直按確認就可以了。
查看是否可用:
ffmpeg -version
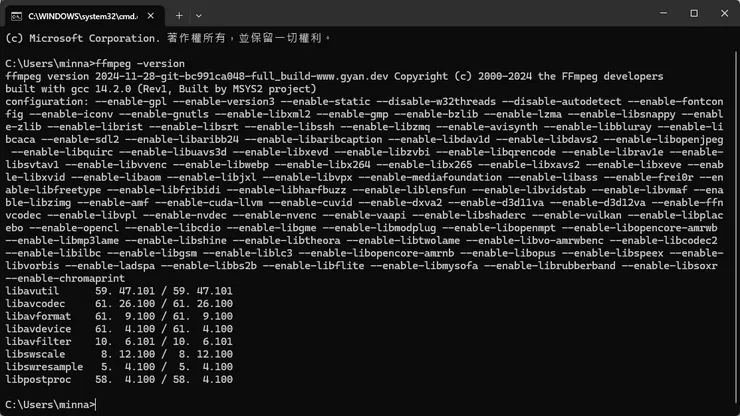
出現以上表示安裝成功。
4-5.其他python環境依賴:
在開始其他相依性安裝之前,請務必下載並安裝Visual Studio 2022 或 Microsoft C++ 產生工具(體積較前者較小)。 勾選並安裝元件包:“使用 C++的桌面開發”,執行修改並等待其安裝完成。 (依賴項中的fairseq、faiss等需要使用VC編譯器輔助編譯才能產生wheel,進而才能安裝到python環境)。
- 設定pip鏡像來源:
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple/
注意:請先安裝pythorch在安裝fairseq,否則會自動安裝cpu版本的pythorch。
pip install fairseq==0.12.2
- 在虛擬環境命令列輸入程式碼進入自己安裝so-vits-svc的資料夾
cd /dD:\hina\hina_vits\so-vits-svc-4.1-Stable
- 在 虛擬環境 venv中 。使用下面的指令先更新 pip , wheel , setuptools 這三個包。
pip install --upgrade pip wheel setuptools
- 執行下面命令以安裝庫( 若出現報錯請多次嘗試直到沒有報錯,依賴全部安裝完成 )。請注意,專案資料夾內含有三個 requirements 的 txt ,此處選擇 requirements_win.txt )
pip install -r requirements_win.txt
- 確保安裝 正確無誤 後請使用下方指令更新 fastapi , gradio , pydantic 這三個依賴:
pip install --upgrade fastapi==0.84.0
pip install --upgrade pydantic==1.10.12
pip install --upgrade gradio==3.41.2
注意:此處指定這三個函式庫版本,是因為SVC原始碼中對於該三個函式庫所呼叫的部分介面在不多的版本號後就被棄用甚至移除了。所以,若版本較新會造成SVC原始碼呼叫錯誤。
5. 關於相容 4.0 模型的問題
- 可以透過修改 4.0 模型的 config.json 對 4.0 的模型來支援。需在 config.json 的 model 字段中新增 speech_encoder 字段,如下:
"model":
{
# 省略其他内容
# "ssl_dim",填256或者768,需要和下面"speech_encoder"匹配
"ssl_dim": 256,
# 说话人个数
"n_speakers": 200,
# 或者"vec768l12",但请注意此项的值要和上面的"ssl_dim"相互匹配。即256对应vec256l9,768对应vec768l12。
"speech_encoder":"vec256l9"
# 如果不知道自己的模型是vec768l12还是vec256l9,可以看"gin_channels"字段的值来确认。
# 省略其他内容
}
下載地址
完整整合包:
百度網盤:
提取碼:g8n4
Google Drive:https://drive.google.com/file/d/19e7HJYk32WHVIXm-CuhvbwF8IHjZ48QU/view?usp=sharing
增量更新
v1.x 版本的整合包無法通過增量更新更新至 v2,请参考這裡瞭解更新方式。
v2.3.14 以前版本请直接下载完整整合包。
百度網盤:
提取碼::yryv
5.訓練
5-1. 主模型訓練(必須):
使用下面的指令訓練主模型,訓練暫停後也可使用下面的指令繼續訓練。
1.python train.py -c configs/config.json -m 44k
5-2.擴散模型訓練(可選):
- So-VITS-SVC 4.1 的一个重大更新就是引入了淺擴散 (Shallow Diffusion) 機制,將 SoVITS 的原始输出音頻轉換為 Mel 譜圖,加入噪聲並進行淺擴散處理後經過聲碼器输出音频。經過測試, 原始輸出音頻在經過淺擴散處理後可以顯著改善電音、底噪等問題,輸出質量得到大幅增強 。
- 尚若需要淺擴散功能,需要訓練擴散模型,訓練前請確保你已經下載並正確放置好了 NSF-HIFIGAN( 参考 2.2.3-可選項)。並且預處理產生 hubert 與 f0 時新增了 --use_diff 參數( 參考2.4.3-生成-hubert-與-f0)。
擴散模型訓練方法為:
1.python train_diff.py -c configs/diffusion.yaml
5-3.模型保存位置:
- 主模型:logs/44k
- 擴散模型:logs/44k/diffusion
簡單來說,即SVC在使用模型推理出的音頻,會被當做輸入使用擴散模型做進一步推理,此操作可大幅提高輸出品質。
模型怎樣才算訓練好了?
這是一個非常無聊且沒有意義的問題。
除了你自己,沒有人能回答這個問題。
模型的訓練關聯於你的數據集品質、時長,所選的編碼器、f0 演算法,甚至一些超自然的 玄學因素;即使你有一個成品模型,最終的轉換效果也要取決於你的輸入來源以及推理參 數。這不是一個線性的過程,之間的變數實在是太多,所以你必須問「為什麼我的模 型出來不像啊」、「模型怎麼算訓練好了」這樣的問題,我只能說 WHO F**KING KNOWS?請用你的耳朵來聽。
常見問題與建議
- 模型效果不佳?
- 檢查數據集質量,確保乾淨無雜音。
- 調整模型參數,並多次試聽推理結果。
- 如何判斷模型訓練完成?
- 使用耳機試聽推理音頻,耳朵是最好的判斷工具。
- 訓練過程太慢?
- 增加虛擬內存,或選擇雲端訓練。
6. Tensorboard
你可以用 Tensorboard 來查看訓練過程中的損失函數值 (loss) 趨勢,試聽音頻,從而輔助判斷模型訓練狀態。但是,就 So-VITS-SVC 這個項目而言,損失函數值(loss)並沒有什麼實際參考意義(你不用刻意對比研究這個值的高低),真正有參考意義的還是推理後靠你的耳朵來聽!
- 使用下面的命令打開 Tensorboard:
tensorboard --logdir=./logs/44k
Tensorboard 是根據訓練時預設每 200 步的評估產生日誌的,如果訓練未滿 200 步,則 Tensorboard 中不會出現任何影像。 200 這個數值可以透過修改 config.json 中的 log_interval 值來修改。
Losses 詳解:
你不需要理解每一個 loss 的具體意義,大致上:
- loss/g/f0、loss/g/mel 和 loss/g/total 應當是震盪下降的,並最終收斂在某個值。
- loss/g/kl 應當是低位震蕩的。
- loss/g/fm 應當在訓練的中期持續上升,並在後期放緩上升趨勢甚至開始下降。
Important:
觀察 losses 曲線的趨勢可以幫助你判斷模型的訓練狀態。但 losses 並不能作為判斷模型訓練狀態的唯一參考,甚至它的參考價值其實並不大,你仍需要透過自己的耳朵來判斷模型是否訓練好了。
Warning:
- 對於小資料集(30 分鐘甚至更小),在載入底模的情況下,不建議訓練過久,這樣是為了盡可能利用底模的優勢。數千步甚至數百步就能有最好的結果。
- Tensorboard 中的試聽音訊是根據你的驗證集產生的, 無法代表模型最終的表現 。
也可使用下載資料夾啟動:
- 雙擊啟動tensorboard.bat 運行 Tensorboard。
雲端訓練
雲端訓練可參考:
AutoDL算力雲:
Google Colab:
結語:
這篇是SO-VITS-SVC製作數據集、處理數據集,以及訓練的說明。本來想把推理的部分也寫完,但一次給太多東西可能會很難吸收,就放到下一篇文章吧!
訓練體驗:
我自己都使用過後的感覺是Autodl算力雲>Google Colab>本地訓練。
- Autodl:提供已部署好環境的鏡像,直接從數據預處理開始,節省大量時間。
- Google Colab:需手動部署部分環境,但每天有免費時數可用。
像我這種命令行跟python的小白…部署環境真的挺吃力的,我選擇雲端。(具體參照個人能力及硬體)。
關於問題:
如果對於文章內容部分在實際操作中遇到問題的,可以提問喔!
到目前為止,我已經訓練了 4-5 個模型,前幾次因數據集質量問題導致失敗,推理出的音頻慘不忍聽。重新訓練的過程非常耗時且令人疲憊,因此數據集的準備至關重要!
下一篇文章將分享推理的詳細步驟,並提供一些推理音頻樣本供大家參考。希望這篇文章能幫助到有需要的朋友,若有問題歡迎提問,我會盡量回答!
感謝閱讀,你們的鼓勵是我最大的動力!


















