俗話說, 一張圖勝千言萬語(好啦我不知道誰說的), 如果你想要一個畫面, 有時候很難一口氣描述出來, 那最好的方式, 就是把這張圖給AI跟他說, 我就是想要這樣的, 但是我要#@$#$的變化...
針對單一圖片進行風格變換或細節調整, 有我之前提到使用 IPAdapter的方式產生多個風格版本, 這次來試試 Flux Redux搭建的工作流程, 速度或是風格上有更大的彈性
Flux Redux 是專為 ComfyUI 設計的圖像變體生成適配器模型(adapter model ),能夠根據輸入圖片直接提取風格特徵並生成相似風格的新圖像,完全不需要文字提示詞。這使它非常適合用於風格轉換、圖片變體創作,以及多圖混合風格的應用場景。
看一下官方網站的圖片就可以知道做到什麼程度:


主要特點
- 無需文字提示:直接從參考圖片中提取風格,生成變體。
- 多圖混合(這個我們另外一篇文章來說明):可同時輸入多張圖像,融合多種風格。
- 高兼容性:支援 Flux.1 [Dev] 與 [Schnell] 版本模型。
- 適合批量變體生成:特別適合需要大量風格一致變體的創作需求
下載必要模型
CLIP Vision (sigclip_vision_patch14_384.safetensors) 放到 ComfyUI/models/clip_vision
Redux 模型 (flux1-redux-dev.safetensors) 放到 ComfyUI/models/style_models
下載工作流
點選以下來自 ComfyUI flux example介紹頁面 的這張圖片放大到原圖(不是縮圖), 拖曳到comfyui介面, 就會看到工作流:

工作流解說
工作流如下, 我用兩個部分來說明, 熟悉之後就可以按照看官您的習慣排成你想要的樣子
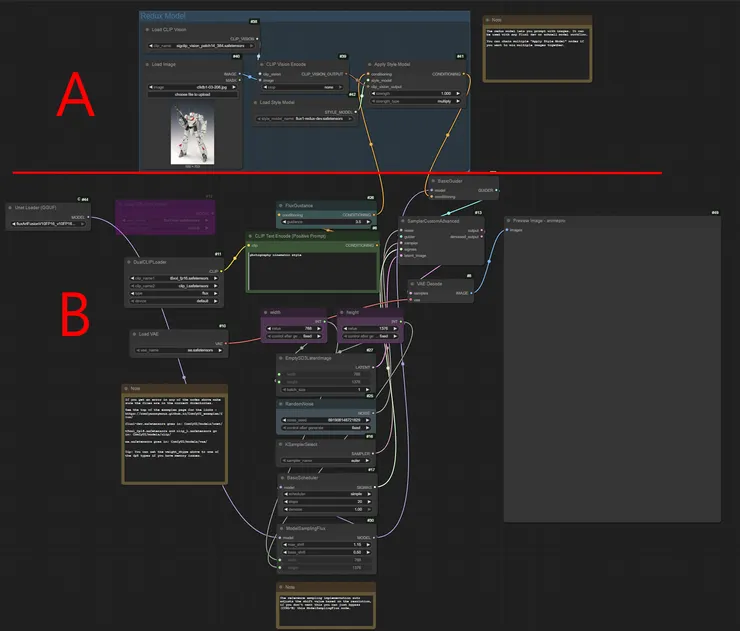
B部分 - 基本Flux工作流
B部分就是我們之前提到的 Flux 工作流, 詳細可以參考之前的文章
我下載的是GGUF版本的flux, 所以這邊更換節點使用Unet Loader載入GGUF版本的Flux
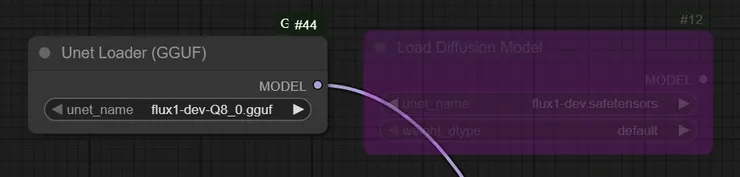
提一下 ModelSamplingFlux (有機會我再補上測試圖)
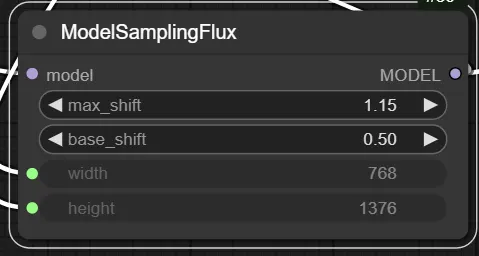
ModelSamplingFlux 節點讓你可以精細控制模型取樣時的「自由度」,進而影響生成圖像的風格與細節。先維持預設值是一個不錯的起點
max_shift、base_shift 主要調整變化幅度,base_shift 是起點,max_shift 是上限,
偏移值低時,結果較穩定、貼近訓練資料;偏移值高時,變化大但可能產生不預期效果
width、height 則決定輸出尺寸(這裡和輸出的潛像尺寸連動)
B部分最常用到的, 就是修改提示詞, 可以從這邊改變風格, 例如將原圖改成 comic style, photography style 等等
A部分 - Flux Redux 工作流
由左上角開始看,
Load CLIP Vision 載入 CLIP Vision 模型(sigclip_vision_patch14_384.safetensors),這是用來將圖片轉換為可被 AI 理解的「視覺特徵」的基礎模型
利用 Load Image 載入一張參考圖片(例如一隻貓的照片),作為風格和內容參考
CLIP Vision Encode 用 CLIP Vision 模型對這張圖片進行編碼,產生 CLIP_VISION_OUTPUT,這是一組高度抽象化的視覺特徵向量,後續將用於風格轉換
Load Style Model 載入 Redux 風格模型(flux1-redux-dev.safetensors),這個模型專門用來實現圖片變體生成與風格轉換
注意這邊原本是使用ApplyStyleModel, 我換成另外一個更直觀的節點來做操作
點選 Manager -> Custom Node 搜尋 Comfyui_Redux_Advanced 安裝後重新啟動ComfyUI

使用 StyleModelApplySimple(或 ReduxAdvanced)
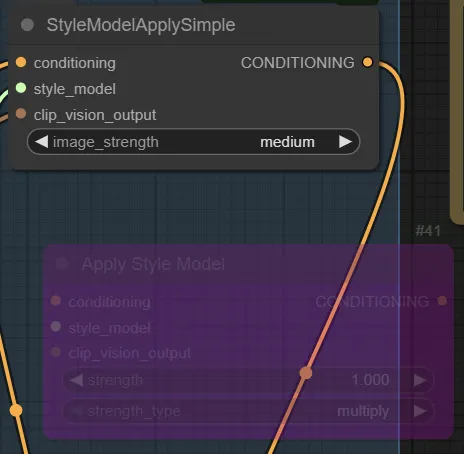
這個節點將三個來源(conditioning、style_model、clip_vision_output)結合起來,根據「image_strength」參數(預設 highest),決定參考圖片的風格影響力
這裡的 conditioning 通常是 text prompt(來自於我們flux工作流的Text Prompt),image_strength 設為 highest,圖片的風格會完全主導生成,prompt 幾乎不起作用
設定到 medium, 那就是圖片參考50%, 提示詞參考50%
來看一下效果, 還是跟圖片和提示詞種類有很大差異, 都要測試一下喔(廢話😆)
提示詞 comic style , 來源圖是一隻貓咪, 由右到左image_strength是highest, high, medium, low的結果如下
可以看到在low的時候幾乎不管參考圖了, 完全變成了狗...
highest的時候完全不管提示詞, 就是圖片貓
medium 圖片參考50%, 提示詞參考50%, 理論上應該要變漫畫風但是沒有表現很好, 要馬就是換動漫的model或是增加lora強化一下, 或是修改更詳細的動漫提示詞

我調整了一下提示詞, 這次要做3D卡通貓:
3d cartoon character, cute, chibi, highly detailed, vibrant colors, big eyes, smooth shading, pixar style, soft lighting
結果如下,
這次把原來的貓咪拿來做比對, 那這次的話我選high的效果是我要的
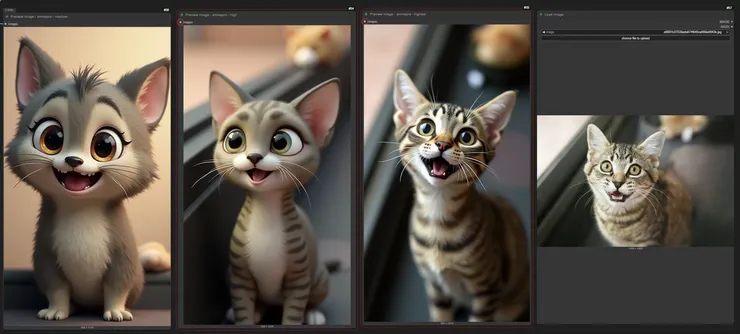
多跑幾次, 也會有各種變種:

好像狐狸了....

你會喜歡哪一種風格呢?
參考資料























