前幾篇介紹了合成資料的定義與生成,今天要介紹的這篇《A Multi-Faceted Evaluation Framework for Assessing Synthetic Data Generated by Large Language Models》,使用 SynEval 開源工具,從「保真度(Fidelity)」、「實用性(Utility)」與「隱私保護(Privacy)」三個維度,全面評估由大型語言模型生成的表格型合成資料是否足以應用於下游任務,並避免敏感資訊泄漏。
評估合成資料生成的品質和可靠性重要性
- 大型語言模型能生成大量資料,滿足不同應用需求,但可能存在偏差和隱私洩露風險。
- 生成資料的真實性、實用性以及隱私性,確保這些數據在實際應用中是可靠和安全的。
- 可以提高資料使用的安全性和可信度,但評估過程可能會增加開發和使用的成本。
提出的方法
真實性(Fidelity)
合成資料與原始資料集相似程度,不僅簡單的統計,還包括對資料存在的關係、依賴關係和情境資訊。
- 結構保留分數(Structure Preserving Score)
- 評估合成資料是否保留與真實資料相同的列名和順序。
- 此評估涉及識別真實(r)和合成(s)資料集中的所有列名稱。
SPS=|𝑟∩𝑠|/|𝑟∪𝑠|- 完整性評分(Integrity Score)
- 連續資料:如時間戳記,包括均值、標準差、最小最大值、中位數等統計特徵的保留情況。
- 離散數據:不該有真實資料集中缺少的新類別值。所以從真實列 (Cr) 計算該組中找到的合成資料與該列中所有合成資料相比的百分比。
IS=|s,s∈Cr|/|s|透過數個分析方法,確保對合成資料進行全面評估,不僅透過模仿評論中表達的公開情緒來衡量其保真度,而且還保留了表徵真實資料集的潛在主題和風格上的細微差別,
Claude 平均評論長度最接近真實數據,ChatGPT 最初會產生冗長的評論,但長度會隨著時間的推移而減少。Llama 在不失去連貫性的情況下產生擴展內容。
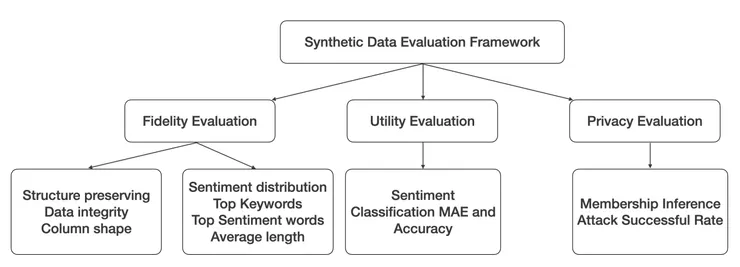
- 結構保留分數:三個模型均為100%
- 資料完整性分數: Claude(98.4%),ChatGPT(93.9%),Llama(87.59%)
- 列形狀分數: Claude(80.92%),ChatGPT(80.97%),Llama(62.29%)
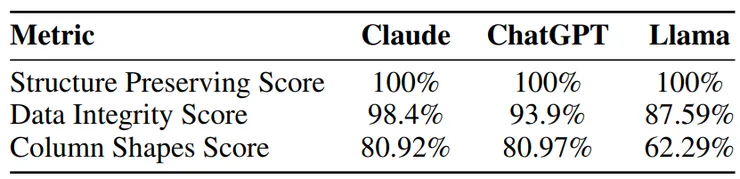
非文字表格資料的真實性評估結果

文本分析結果
實用性(Utility)
評估合成資料在實際任務中的效用,合成資料是否能夠用於訓練模型並在真實資料上取得良好表現。
- TSTR(Train-Synthetic-Test-Real)框架:
- 模型訓練: 合成資料
- 模型測試: 真實資料
- 比較模型在真實資料上的表現,衡量合成資料的實用性。
- 可以直接反映合成資料在實際應用中的效用但需要大量計算資源進行訓練和測試。
- 評估指標:
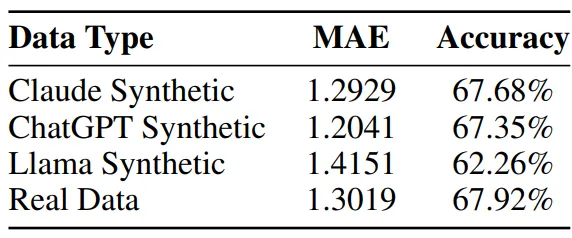
- MAE(Mean Absolute Error):
- 用於衡量回歸模型的預測準確性,平均絕對誤差越小,表示模型表現越好。
- 準確率(Accuracy):
- 用於衡量分類模型的預測準確性,準確率越高,表示模型表現越好。
隱私性(Privacy)
評估合成資料在保護隱私方面的效果,確保生成數據不會洩露訓練數據中的敏感信息,成員推斷攻擊成功率越低,表示生成數據的隱私保護效果越好。
- 成員推斷攻擊(Membership Inference Attack, MIA):
- 利用已知的模型訓練資料和非訓練資料來訓練一個攻擊模型。
- 判斷某一特定數據點是否存在於合成資料生成模型的訓練集中。
- 成員推斷攻擊成功率越高,表示生成模型越容易洩露訓練數據中的信息,隱私保護效果越差。

成員推斷攻擊成功率(越低表示生成數據的隱私保護效果越好)




















