由 NVIDIA 發表,包括 Base、Instruct 與 Reward 三個版本,在 alignment 過程中超過 98% 的微調資料來自合成資料生成流程,展現有效運用 synthetic data 發展對齊模型的能力。Nemotron‑4‑340B 在 MMLU、ARC‑Challenge、BigBench Hard 等 benchmark 上與 Llama‑3 70B 或 Mixtral 8×22B 等大型模型競爭 - Nemotron-4 340B Technical Report
本篇貢獻
- 模型對齊過程中 98% 的訓練資料都是 Nemotron-4-340B-Base 生成的。
- 此模型具有高品質資料生成的能力,可以用來訓練其他的語言模型。
- 開源了合成數據的生成流程。
資料與訓練
資料組成
- 涵蓋 53 種自然語言和 43 種程式語言。
- 70% 英文自然語言資料
- 15% 多語種自然語言資料
- 15% 程式碼資料
- 高品質資料(9T)
- Llama-2 使用 2T Token ,Llama-3 使用 2T Token
- Nemotron-4 340B Base 只使用 9T Token 高品質資料集
- 8T Token 用於正式預訓練階段
- 1T Token 用於持續預訓練階段
- 模型校準
- 結合人類反饋的強化學習(RLHF)與直接偏好優化(DPO)
- 使模型更好地遵循指令、有效地進行對話和解決問題
持續訓練(Continued training)
- 資料分佈 : 在持續訓練階段中利用兩種不同的資料分佈。
- 第一種: 將重點放在更高品質的來源上。
- 第二種: 引入少量問答式,使模型可以更好的面對此類問題,增加來自模型精度較低區域的資料來源
- 訓練階段
- 這種資料分佈的順序和風格使模型更好地從訓練最後階段引入的數據。
模型對比
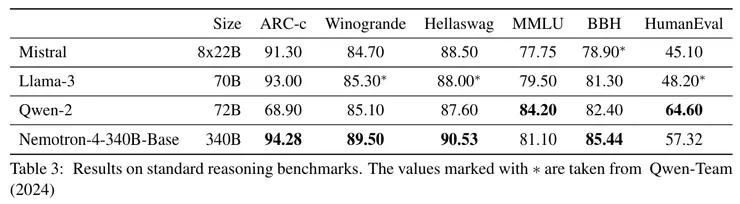
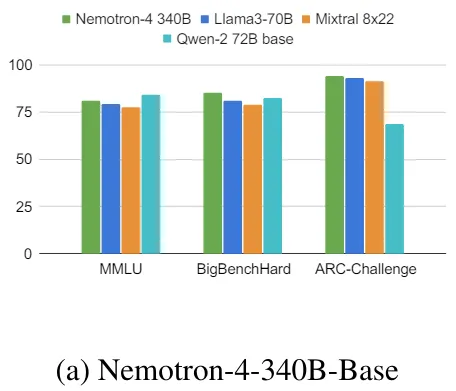
Nemotron-4-340B-Base
- 關聯性: 提供基本的語言理解和生成能力。
- 資料組成: 70% 英文自然語言資料、15% 多語種自然語言資料、15% 程式碼資料。
- 訓練說明:
- 使用多種標準化的任務設置進行訓練。
- 確保評估結果的可比性和可信度。
- 可能無法完全覆蓋真實世界中的多樣化需求。
- 模型用途: 各類語言任務,如文本生成、問答系統等,作為其他模型(指導模型和獎勵模型)的基礎。
- 任務說明:
- MMLU: 測量模型在多領域多任務表現的基準,由大量的多選題組成,涵蓋57個主題。
- BigBenchHard: 多樣化的挑戰任務,專為超出當前模型能力的任務設計。強調推理和創造能力。
- ARC-Challenge: 測試模型科學推理能力的問題集,測試模型在回答科學和常識問題上的能力。
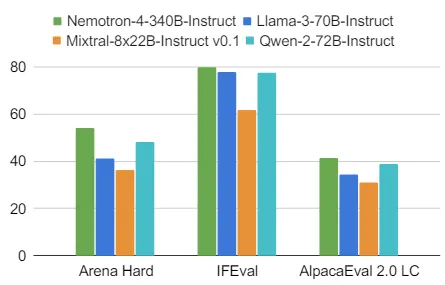
Nemotron-4-340B-Instruct
- 關聯性: 基於Base模型進行微調,專注於指令跟隨和對話能力。
- 資料組成: 基礎資料上進行微調,包括人類反饋強化學習(RLHF)和直接偏好優化(DPO)。
- 用途: 適合於需要準確跟隨指令的任務,如自動客服、虛擬助理等。
- 任務說明:
- Arena Hard: 是更為嚴苛的即時實際聊天,用於測試模型的即時反應和交互表現。
- IFEval: 針對自然語言指示的回應能力,評估其指令理解和執行的準確性和效率。
- AlpacaEval 2.0: 設計為簡化複雜指令,進行快速、自動化、可靠的模型評估。
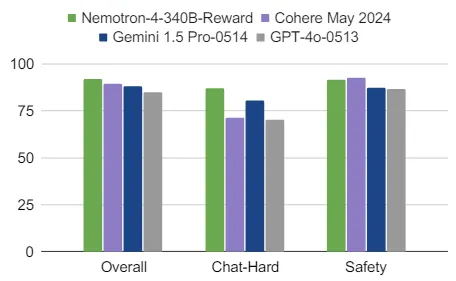
Nemotron-4-340B-Reward
- 關聯性: 用於評估和提高模型生成內容質量的獎勵模型。
- 資料組成: 使用大量合成資料進行微調。
- 訓練說明:
- 訓練10k 人類偏好數據來提高模型的指令遵循能力。
- 強化模型在多回合對話中的表現。
- 但偏好數據的品質和多樣性直接影響效果。
- 用途: 評估和優化模型生成內容的質量。
- 任務說明:
- Overall: 整體評估包含多項測試工具和數據集,用於綜合評估模型在不同任務和場景下的表現。
- Chat-Hard: 專注於多輪對話測試,測試更為複雜和多變的對話情境下的模型表現。
- Safety 安全性測試集專注於模型回答是否安全,避免生成有害內容,並確保在各種情境下的表現符合安全要求。