python Streamlit連動github程式碼實現YoloV8網頁版偵測物件
Streamlit網頁 實現YoloV8 偵測物件
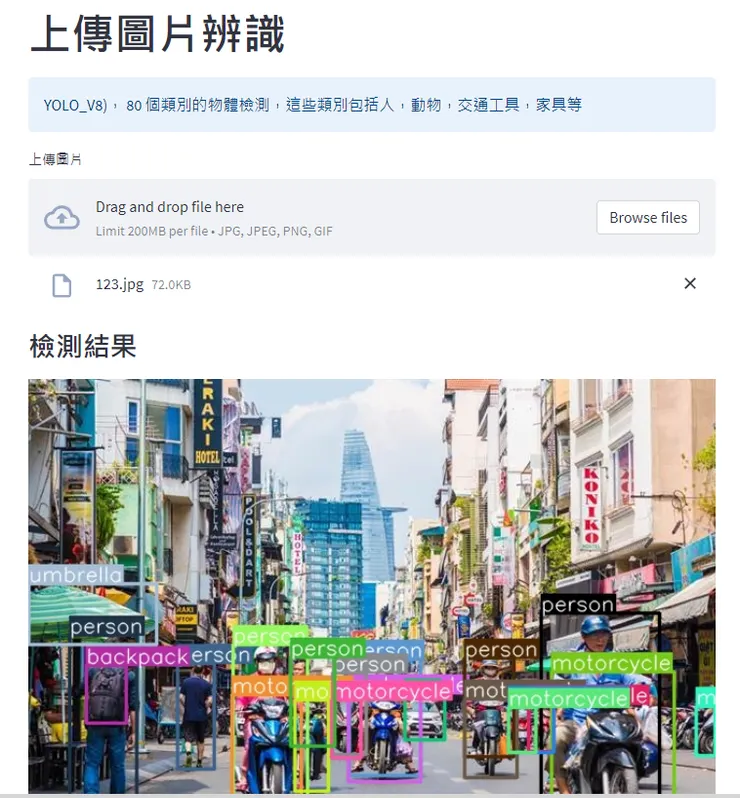
套用模型為YoloV8(YOLOv8n)最小模型,因github上傳檔案最大上限為25mb導入圖像(搜尋街景圖隨意抓取)
Streamlit網頁 實現YoloV8 偵測物件連結
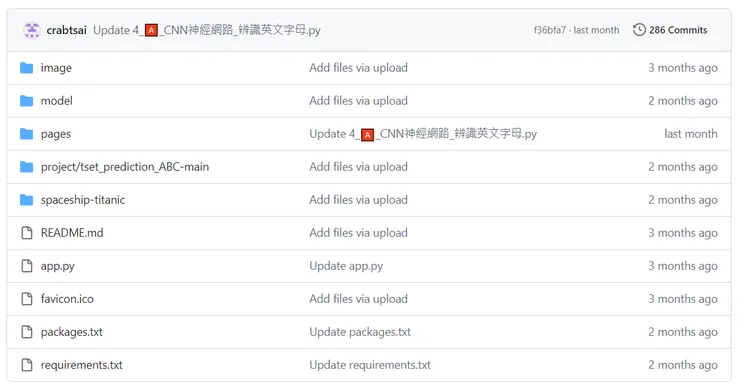
github資料夾說明
image -> 圖檔放置
model -> 存放模型
pages -> 呈現在streamlit上的程式碼放置位置
requirements.txt -> streamlit指定安裝python套件版本
packages.txt -> streamlit 安裝yolov8 libraries用
程式碼:
import streamlit as st
from skimage import io
import numpy as np
from ultralytics import YOLO
import matplotlib.pyplot as plt # 新增這一行
from ultralytics.utils.plotting import Annotator
from PIL import Image #1024
st.title("上傳圖片辨識")
st.info("YOLO_V8), 80 個類別的物體檢測,這些類別包括人,動物,交通工具,家具等")
uploaded_file = st.file_uploader("上傳圖片", type=['jpg', 'jpeg', 'png', 'gif'])
colors_rgb = {str(i): ((i * 30) % 256, (i * 50) % 256, (i * 70) % 256) for i in range(30)}
if uploaded_file is not None:
image = io.imread(uploaded_file)
if image.shape[-1] == 4: # 如果通道數為4,通常是带有alpha通道的圖像
image = image[:, :, :3] # 去除alpha通道
# 載入模型
pretrained_weights_path = './model/yolov8n.pt'
yolo = YOLO()
yolo = yolo.load(pretrained_weights_path)
try:
results = yolo.predict(image) #預測指令
# 顯示結果
st.subheader("檢測結果")
colors_count = 0
result_str = []
# 顯示物件類別
print(results[0].boxes.cls)
# # print()
for i, result in enumerate(results):
annotator = Annotator(image)
boxes = result.boxes
for box in boxes:
cls = box.cls
xyxy = box.xyxy[0]
result_str_1 = yolo.names[int(cls[0])]
result_str.append(result_str_1)
annotator.box_label(xyxy,yolo.names[int(cls[0])],colors_rgb[f'{colors_count}'])
colors_count += 1
img = annotator.result()
# 顯示標註後的圖片
st.image(img, caption="檢測結果", use_column_width=True)
st.write(result_str)
except Exception as e:
print(f"Error during prediction: {e}")
程式碼說明
st.title("上傳圖片辨識")
st.info("YOLO_V8), 80 個類別的物體檢測,這些類別包括人,動物,交通工具,家具等")
`st.title` 網頁開頭標題,Streamlit 中用來顯示標題的函式
`st.info` 可新增說明內容,是 Streamlit 中的一個函式,用於顯示信息提示框

uploaded_file = st.file_uploader("上傳圖片", type=['jpg', 'jpeg', 'png', 'gif'])
st.file_uploader 是 Streamlit 中用來創建檔案上傳元件的函式。它允許使用者在應用程式的網頁界面上選擇並上傳檔案,通常用於接收使用者提供的圖片、文件等。

colors_rgb = {str(i): ((i * 30) % 256, (i * 50) % 256, (i * 70) % 256) for i in range(30)}
這一段程式碼創建了一個名為 colors_rgb 的字典,其中包含了30種不同的RGB顏色,為了YoloV8偵測到的物件,框起來顏色不同所設計,用到的是python語法中生成器的一種概念。
for i in range(30):這是一個迴圈,從0到29迭代,共迭代30次。{str(i): ((i * 30) % 256, (i * 50) % 256, (i * 70) % 256) for i in range(30)}:這是一個字典生成式,用於創建一個包含30個鍵值對的字典。每個鍵都是i的字串表示,而對應的值是一個包含三個數字的元組,這三個數字分別代表紅色(R)、綠色(G)和藍色(B)的值。
if uploaded_file is not None:
這個if條件語句檢查是前面創建的上傳檔案按鈕的變數 uploaded_file 是否為非空值(不是 None)。在這個上下文中,它用於確保在使用者上傳了檔案之後才執行相應的程式碼塊。
具體來說,在這個程式中,如果 uploaded_file 不是 None,代表使用者已經上傳了一個檔案,那麼下面的程式碼塊就會被執行。這通常是為了處理使用者上傳的檔案,例如讀取並顯示圖片,進行檔案的處理或分析等相應的操作。
這樣的條件語句有助於檔案上傳的情況下執行相應的邏輯,同時避免沒有檔案上傳時執行相關程式碼,防止出現錯誤或不必要的操作
image = io.imread(uploaded_file)
if image.shape[-1] == 4: # 如果通道數為4,通常是带有alpha通道的圖像
image = image[:, :, :3] # 去除alpha通道
image = io.imread(uploaded_file):使用io.imread函式讀取上傳的檔案,並將其資料轉換為圖片數據。這裡使用的是skimage库的io模組。if image.shape[-1] == 4::這個條件語句檢查圖片的通道數是否為4。通常,如果一張圖片具有4個通道,那麼它帶有一個 alpha 通道,表示透明度。image = image[:, :, :3]:只保留前三個通道(紅、綠、藍),將圖片轉換為一個沒有透明度信息的普通RGB圖片。
總的來說,這段程式碼確保讀取的圖片是一個三通道的RGB圖片,去除了可能存在的 alpha 通道。這樣的處理通常是為了確保後續的圖片處理和模型預測能夠正確進行。
# 載入模型
pretrained_weights_path = './model/yolov8n.pt'
yolo = YOLO()
yolo = yolo.load(pretrained_weights_path)
pretrained_weights_path = './model/yolov8n.pt':這是一個相對路徑,指向存儲了預先訓練權重的檔案。yolo = YOLO():創建一個 YOLO 模型。yolo = yolo.load(pretrained_weights_path):使用load方法載入預先訓練的權重。這個方法將預先訓練的權重載入到之前創建的 YOLO 模型,以便使用這些權重進行物體檢測
try:
results = yolo.predict(image) #預測指令
# 顯示結果
st.subheader("檢測結果")
colors_count = 0
result_str = []
# 顯示物件類別
print(results[0].boxes.cls)
# # print()
for i, result in enumerate(results):
annotator = Annotator(image)
boxes = result.boxes
for box in boxes:
cls = box.cls
xyxy = box.xyxy[0]
result_str_1 = yolo.names[int(cls[0])]
result_str.append(result_str_1)
annotator.box_label(xyxy,yolo.names[int(cls[0])],colors_rgb[f'{colors_count}'])
colors_count += 1
img = annotator.result()
# 顯示標註後的圖片
st.image(img, caption="檢測結果", use_column_width=True)
st.write(result_str)
results = yolo.predict(image):使用載入的 YOLO 模型對上傳的圖片進行預測。results包含了檢測結果,每個結果對應一個或多個檢測到的物件。st.subheader("檢測結果"):使用 Streamlit 的st.subheader函式顯示一個子標題,標題為 "檢測結果"。- colors_count = 0 定義偵測框的初始值,給先前建立的顏色字典做索引的使用
- result_str = [] 建立result_str的list,儲存偵測到的結果用
for i, result in enumerate(results):
annotator = Annotator(image)
boxes = result.boxes
for box in boxes:
cls = box.cls
xyxy = box.xyxy[0]
result_str_1 = yolo.names[int(cls[0])]
result_str.append(result_str_1)
annotator.box_label(xyxy,yolo.names[int(cls[0])],colors_rgb[f'{colors_count}'])
colors_count += 1
這段程式碼是一個迴圈,用於處理模型的每個檢測結果,並在圖片上標註檢測框和物件類別
for i, result in enumerate(results)::這個迴圈遍歷模型的每個預測結果,enumerate(results)同時提供了索引i和對應的檢測結果result。annotator = Annotator(image):為每個檢測結果創建一個Annotator實例,這個實例用於在圖片上添加標註。boxes = result.boxes:取得當前檢測結果中的所有檢測框。for box in boxes::這個迴圈遍歷每個檢測框。cls = box.cls:取得檢測框中物件的類別。xyxy = box.xyxy[0]:取得檢測框的四個座標點。result_str_1 = yolo.names[int(cls[0])]:根據物件的類別索引,從模型的yolo.names中取得物件的名稱。result_str.append(result_str_1):將檢測到的物件名稱加入到result_str列表中。annotator.box_label(xyxy, yolo.names[int(cls[0])], colors_rgb[f'{colors_count}']):使用Annotator的box_label方法,在圖片上標註檢測框和物件類別,同時指定標註的顏色。colors_count += 1:更新顏色計數,以便每個不同的物件標註使用不同的顏色。- 迴圈結束後,
img = annotator.result():取得標註後的圖片,包含了所有檢測結果的標註。
總的來說,這段程式碼的目的是遍歷模型預測的每個檢測框,為每個檢測框添加標註,包括物件類別和邊界框,然後取得標註後的圖片。這個圖片將在後續用於顯示檢測結果。
# 顯示標註後的圖片
st.image(img, caption="檢測結果", use_column_width=True)
st.write(result_str)
這兩行程式碼用於在 Streamlit 的界面上顯示物體檢測的結果:
st.image(img, caption="檢測結果", use_column_width=True):使用st.image函式顯示標註後的圖片。這裡的img是經過標註的圖片,caption參數指定了圖片的標題,並且use_column_width=True使得圖片的寬度自適應列的寬度。st.write(result_str):使用st.write函式顯示檢測到的物件名稱。這將在應用程式的界面上顯示一個區域,其中包含了所有檢測到的物件的名稱。

























