上一篇初步了解 AI 這個領域的分類和常用名詞,機器學習我將會拆成上集「監督式學習」、上級「監督式學習:預測」與 下集「非監督式學習」。
1. 監督式學習 (Supervised Learning)
1.1 分類 (Classification)
Logistic Regression 邏輯回歸:解釋如何進行分類預測。
在機器學習中,邏輯回歸是解決二元分類問題(正負、是否)的方法,雖然有「回歸」這兩個字,但主要用於分類,作為預測的是 Linear Regression 線性回歸。- 它的目的是將輸入的特徵(如年齡、收入等)投射到一個機率值(介於0到1),以決定該樣本屬於某個類別的機率。
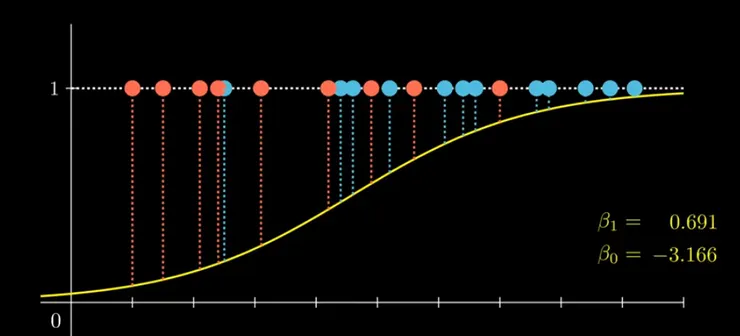
黃色的這條線是 Sigmoid 函數 計算出屬於某類別的機率,(此函數的數學較複雜,我就放棄了) Sigmoid 函數將任何實數 z 投影到 0 到 1 之間的範圍。
舉例
假設要預測一位顧客是否會購買產品:
- 特徵:年齡、收入。
- 模型輸出:購買的機率(如 0.8 表示 80% 機率會購買)。
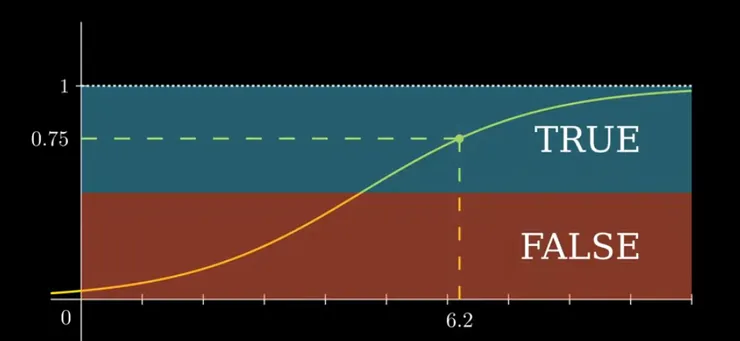
- 結果:若機率 > 0.5,則預測該顧客會購買。 0.5 的值可以隨使用者定,並不是定值
Logistic Regression in 3 Minutes圖片來源
Confusion Matrix:介紹混淆矩陣的組成與用途。
想像今天我要用一刀切資料,一定會有資料被是誤判。這些狀況可以用 Ture / Fasle 表示,寫成 Consion Matrix,讓我拿 Google 的影片來舉例。
Machine Learning Crash Course: Classification
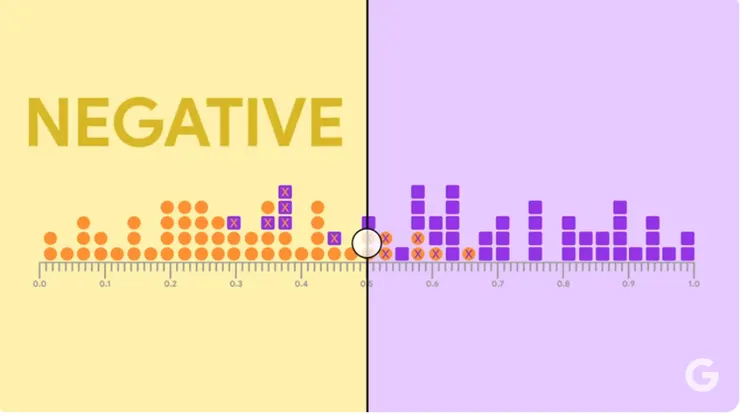
一、先隨機切,左半邊全是 Nagative,右半邊全是 Positive (但是一定有被錯誤分類的,例如實際陰性被歸類為陽性,實際陽性被歸內為陰性。
刻度量尺是 Threshold,Threshold 是一個設定的分界值,通常用在機率型模型(例如 Logistic Regression)中,來決定預測的類別標籤。模型通常會輸出一個機率(例如輸出一個數值在 0 到 1 之間),而 threshold 決定了這個機率需超過多少時,才能被分到某個類別。例如小於0.5 被歸類為負,大於被歸類為正。
二、混淆矩陣出現:共四種情況

- True Positive (TP):模型正確預測為正類(實際是正,預測也為正)。
- False Positive (FP):模型錯誤預測為正類(實際是負,但預測為正,稱為「假警報」)。
- False Negative (FN):模型錯誤預測為負類(實際是正,但預測為負,稱為「漏報」)。
- True Negative (TN):模型正確預測為負類(實際是負,預測也為負)。
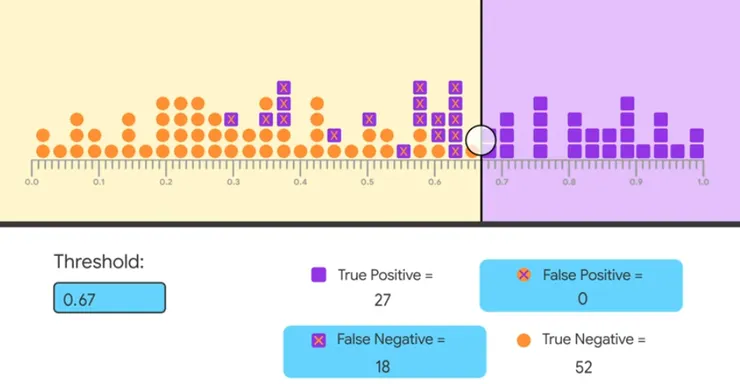
透過調整 threshold (閥值)使 false positive 降成 0
性能評估指標:Accuracy, Precision, Recall, F1 Score
透過混淆矩陣,我們可以計算多種指標,例如:( 數學公式請 ChatGPT 生成)

生活化例子:
假設你設計一個垃圾郵件分類器:
- TP:垃圾郵件被正確分類為垃圾郵件。
- FP:正常郵件被錯誤分類為垃圾郵件(誤刪重要信件)。
- FN:垃圾郵件被錯誤分類為正常郵件(可能讓詐騙郵件進入收件匣)。
- TN:正常郵件被正確分類為正常郵件。
痾... 還是分不清楚,沒關係,以下我會用這個影片解釋:
Never Forget Again! // Precision vs Recall with a Clear Example of Precision and Recall
用橘子和蘋果當資料,總共 10 顆水果。
Accuracy:
有哪些水果是正確被分類的?橘子邊的橘子4顆,加上蘋果邊真的是蘋果的3顆。

用 Accuaray 的計算有盲點,如果資料是極度不平均,例如 990 顆橘子跟 10 顆蘋果,準確率高達99% (990/1000) 模型很可能會跟我說「全部都是橘子」。
這時候就需要 Precision 跟 Recall 概念。我們主要關注 蘋果的類別。
Precision:
被分在蘋果邊中的水果有5個,真正是蘋果邊的有3個,所以 Precision 是 60%。

Recall:
全部的蘋果,有多少蘋果是被正確分類的?3顆,所以是3/4=75%。

提高 召回率(Recall),但可能犧牲 精確率(Precision)。如果我將模型重新調整:使 Precision 提高,但 Recall 就降低

範例應用
- 醫學診斷:
- 如果是癌症篩檢,應選擇較低的 threshold,因為寧可多檢查一些非癌症病例(提高召回率,犧牲精確率),雖然會有「偽陽性」出現,也不想漏掉真正的癌症患者。
- 垃圾信分類:
- 如果分類錯誤成本高(不想錯誤地將重要郵件分類為垃圾),可選擇較高的 threshold,來提高精確率。
ROC Curve & AUC:如何使用ROC曲線與AUC評估模型效能。
延續上一段,我們會調整 Threshold,在 Precision 和 Recall 之間取得平衡。通常我們會透過 ROC 曲線 或 Precision-Recall 曲線 來幫助選擇最佳的 threshold。
ROC (Receiver Operating Characteristic)
繪製 ROC True Positive Rate (TPR) 和 False Positive Rate (FPR) 的變化。
- 橫軸 (X): False Positive Rate (FPR)
- 定義:假陽性率 = 假陽性數量 / (假陽性數量 + 真陰性數量)。
- 代表模型誤將負類別判為正類別的比例。
- 縱軸 (Y): True Positive Rate (TPR)
- 定義:真陽性率(也叫 Recall)= 真陽性數量 / (真陽性數量 + 假陰性數量)。
- 代表模型正確判定正類別的比例。
ROC 曲線展示的是模型如何在不同的閾值下平衡 TPR 和 FPR。
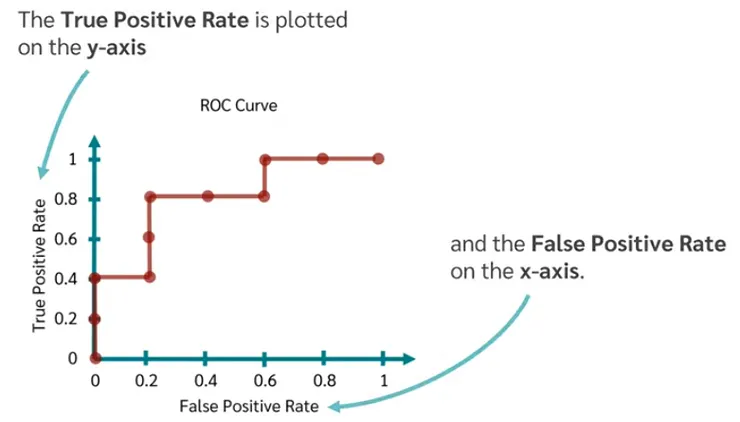
實際畫 ROC 的範例:
先畫第一個點,找到 TPR 畫虛線,再用 FPR 畫第二個虛線。交集處為第一個點,以此類推。
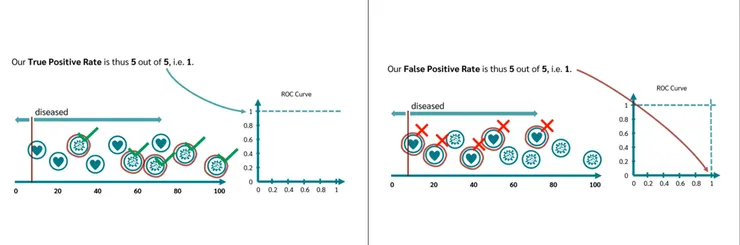
畫出線之後,要檢驗
AUC (Area Under the Curve)
AUC 是 ROC 曲線下的面積,數值介於 0 到 1 之間。
- AUC 的意義:
- AUC 越接近 1,表示模型性能越好。
- AUC = 0.5 表示模型和隨機猜測差不多(沒有預測能力)。
- AUC 越低於 0.5,表示模型在分類時表現得非常糟糕,甚至反向。
- 直觀解釋:
- AUC 代表從數據集中隨機選一個正樣本和負樣本,模型能正確區分它們的概率。
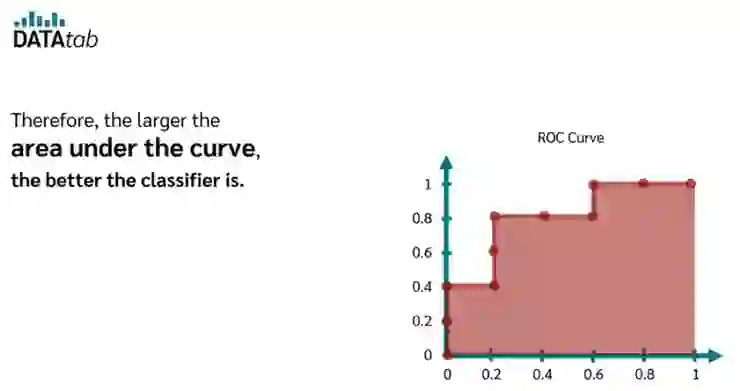
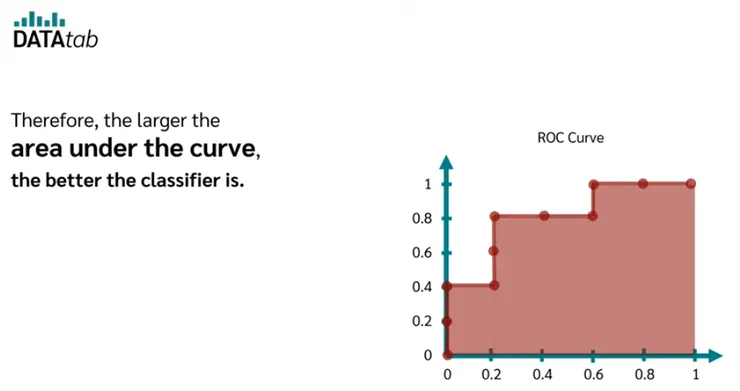
同時適用於分類和回歸的方法:
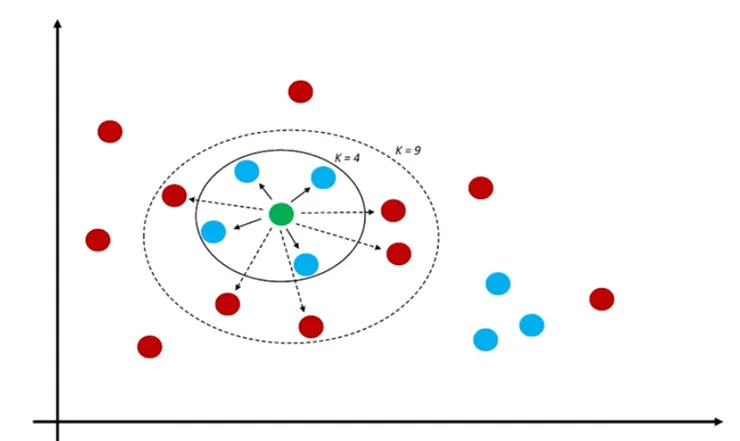
KNN (K-Nearest Neighbors):簡單值觀的機器學習演算法,不需要有回歸公式參數。它根據資料點與鄰近點的距離,決定該點的分類或預測值。
參考影片
All Machine Learning algorithms explained in 17 min
核心概念:
- 鄰近概念:KNN 使用距離(例如歐幾里得距離)來衡量資料點之間的相似度。
- K 值:K 是鄰近點的數量,演算法會考慮最近的 K 個點來決定輸出。
- 投票:對於分類問題,KNN 會基於 K 個最近點的多數類別進行分類;對於回歸問題,則取鄰近點的平均值作為預測。
例子:
假設你有一個資料集,包含紅色 (類別 A) 和藍色點 (類別 B)。當一個新點加入時,KNN 會計算它與所有已知點的距離,然後選取最近的 K 個點來決定新點的類別。例如,K = 3時,會選擇新加入的點附近三點,如果附近的3個點,有兩個是紅色1個藍色,新加入的點就被歸類為紅色。
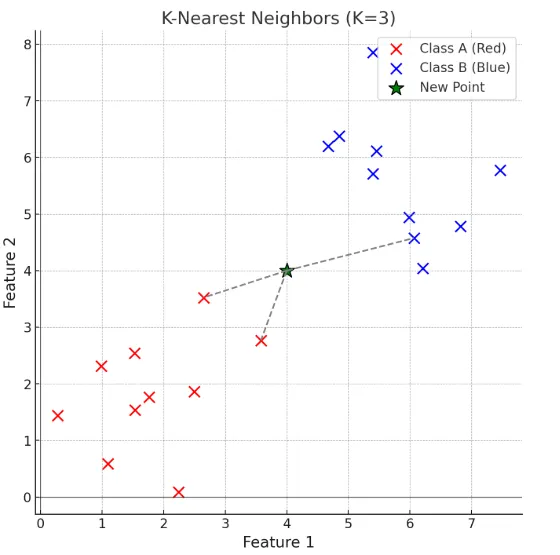
如果這是線性的值,例如最近的值是51, 52, 53, 就取平均
k = 4 即新加入的點,最近的4點。
優點:
- 簡單易懂,無需訓練過程。
- 對於小型資料集效果良好。
缺點:
- 計算量隨資料集大小增加。
- 對於高維度資料表現可能較差(受「維度詛咒」影響)。
SVM (Support Vector Machines) & Kernel Trick:支持向量機的核心概念與核函數技巧的作用。
目的是在不同類別之間找到「最佳的分隔線(或分隔超平面)」。(摩西分紅海?) 這個概念最在「多維度的資料」之中最有效過。
最佳的分隔線應該要 最大化兩個類別之間的邊界距離。
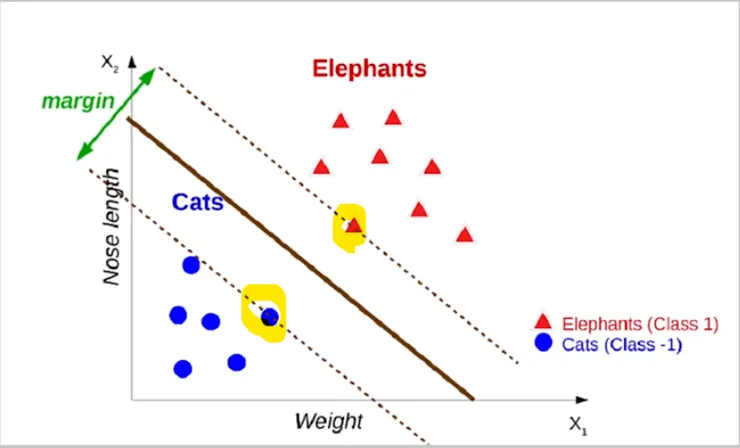
中間粗線是分隔線;支持向量是螢光筆區圈起來的點。
- 分隔線(Hyperplane):將資料分成不同類別的線(在高維度空間中可能是平面或超平面)。
- 支持向量(Support Vectors):最靠近分隔線的資料點,決定分隔線的位置與方向。
- 邊界距離(Margin):從分隔線到最近的支持向量的距離,目標是讓這個距離最大化。
冷知識:為什麼明明是點,要取名為「Support Vectors」?
在數學裡,vectors(向量)是一種表示空間中方向和大小的數學工具。在 SVM 裡,每一筆資料(例如一個座標點)都可以視為一個向量,因為它有多個特徵,可以用向量來表示它們在空間中的位置。
舉例來說,如果有兩個特徵(例如年齡和薪水),每筆資料就可以被看成一個平面上的點或一個向量 [x,y]。這些向量決定了資料分布,SVM 則利用這些向量來畫出分界線。這些點「支撐」了 SVM 所畫出的分界線,它們決定了分界線的位置和方向。(要有一點想像力哈哈)
Kernel Trick (核函數技巧)
當資料無法用直線分開時,我們可以利用 Kernel Trick,將資料從低維空間轉換到高維空間,使其在高維空間中可線性分隔。
- 線性核(Linear Kernel):適用於資料本身可線性分隔的情況。
- 多項式核(Polynomial Kernel):對於非線性分隔資料,提供更多彎曲的決策邊界。
- RBF(Radial Basis Function)核:將資料映射到無限維空間,能解決更複雜的分隔問題。
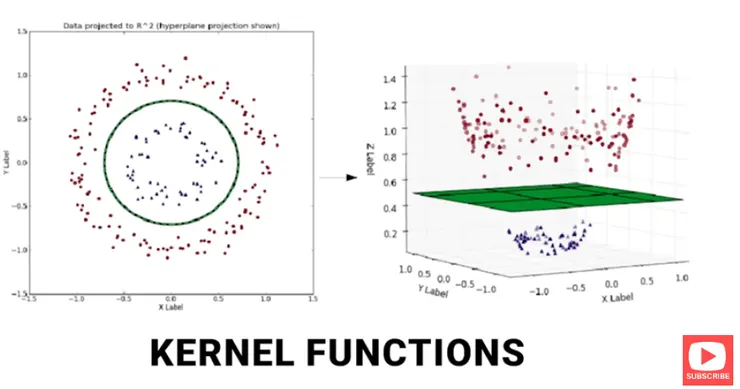
SVM 的應用
- 圖像識別(如手寫數字辨識)
- 疾病預測(如癌症檢測)
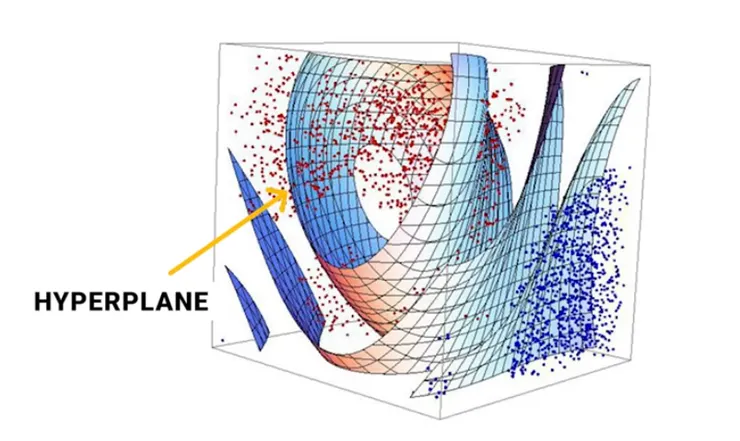
多維的資料模型
Naive Bayes Classifier:貝氏定理 (Bayes' Theorem) 的分類演算法
先看這個分類方式主要用在哪裡。因為我高中機率快忘光光,所以就不詳細研究這個主題。

垃圾郵件分類
- 特徵:郵件的詞彙(例如 "免費"、"促銷")。
- 類別:垃圾郵件 SpamSpamSpam 和正常郵件 NotSpamNot SpamNotSpam。
- 訓練:根據歷史郵件,計算每個詞出現在垃圾郵件和正常郵件中的機率。
- 預測:對新郵件計算其屬於垃圾郵件和正常郵件的機率,選擇機率較高的類別。
假設我們要分類一組電子郵件是否為垃圾郵件,訓練數據集中 40% 是垃圾郵件,60% 是非垃圾郵件。垃圾郵件的先驗機率(Prior Probability)已知的機率是
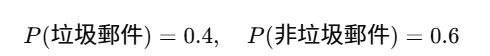
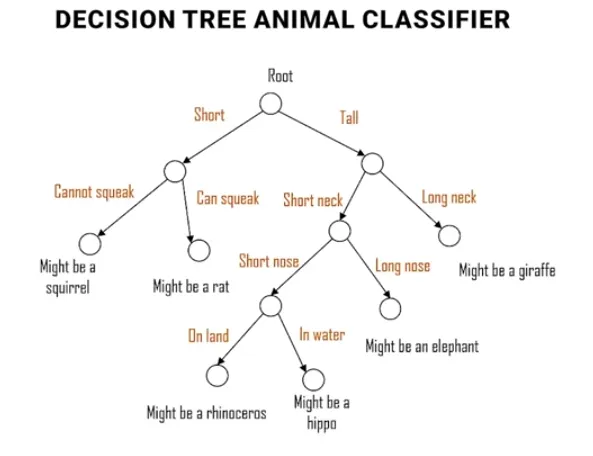
- Decision Trees:介紹決策樹的結構與分割方法。
每個節點往下都用「是否」問句來分類,或是二分法,例如我們要建立一個決策樹來預測一位動物,特徵包含身高、水生或陸地動物、脖子長短等等。
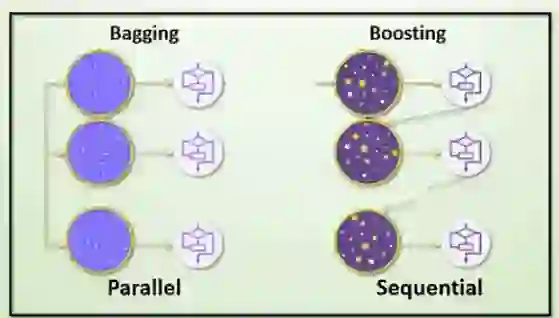
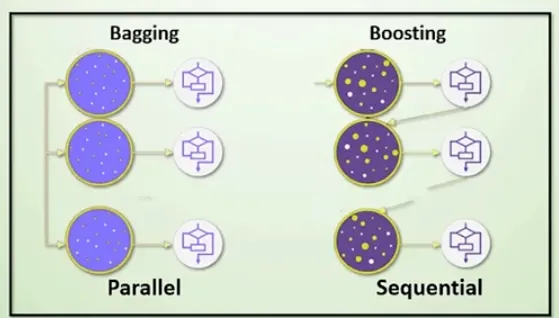
這樣聽起來很簡單,怎麼做到機器學習?如果把很多決策樹合在一起就可以做到了。這個技術就是 Bagging & Random Forests
Ensemble Algorithms:
- Bagging (Bootstrap Aggregating)(自助聚合法):
- 透過選取隨機的資料集,做獨立訓練。
- 每個模型都會在不同的重抽樣資料上進行訓練,最終的預測是透過平均(回歸問題)或投票(分類問題)來決定。
- 隨機森林 (Random Forests)是一個典型的例子. 它「同時」訓練不同的決策樹,再把每顆樹的結果整合,用來精準預測。
- Boosting(提升法):
- 逐步的訓練,第二個新模型的目的,是修正前一個模型所犯的錯誤。比 Bagging 精準,但會出線 Over-fitting 的問題。
- 模型會根據錯誤的樣本給予高權重,下一次訓練時就可以更注意修正錯誤
- 例如 Adaboost (自適應提升法) 和 梯度提升法 (Gradient Boosting)。在 Adaboost 中,會將多個弱分類器結合成一個強分類器,而梯度提升法則是通過步步降低誤差來進行訓練。(這已超出我腦袋能理解的範圍XD)
1.2 預測 (Prediction) --> 下集待續
- Linear Regression:解釋線性迴歸的數學模型與應用。

























