
HeidiSQL 概念圖 by ChatGPT
近期工作上剛好需要針對 MySQL 資料庫進行備份,於是特別研究了有哪些方法。由於目前仍是小型的初期專案,資料庫的 Server 部署在一台虛擬機上,隨著資料量快速增長,備份需求也逐漸浮現。
因應未來可能開放 API 供同仁查詢資料,建立一套可靠的備份機制就顯得格外重要。有鑑於此,本文將探討幾種備份方法,並比較它們的優缺點,讀者可依需求選擇最適合的解決方案。
首先簡單的介紹一下 HeidiSQL 這個資料庫介面工具。
HeidiSQL 是一款免費而且開源的資料庫管理工具,支援包含常見的 MySQL、MariaDB、PostgreSQL 等多種資料庫系統。它在功能上與其它的工具如 DBeaver、Toad 都很類似,皆可以用來瀏覽資料庫結構、查詢資料、編輯資料表等操作。
相較之下,我個人還是偏好 HeidiSQL,因為它簡潔、不繁複,且有一個我非常喜歡的設計:在執行各種 CRUD 操作時,會即時在介面下方顯示對應的 SQL 原始碼,而且這些內容是持續可見的,也就是你可以往回翻找先前操作的 SQL。
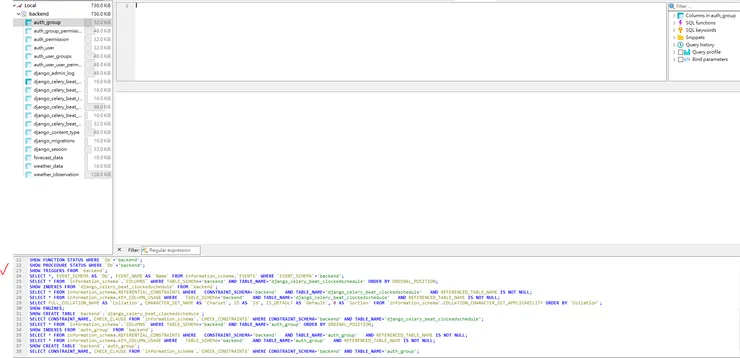
HeidiSQL 介面 - SQL 原始碼
接下來就實際操作看有哪些備份機制,我們一個一個的來介紹:
- 使用 HeidiSQL 內建的 export 功能
首先對著你的 Database 名稱點右鍵 > Export database as SQL
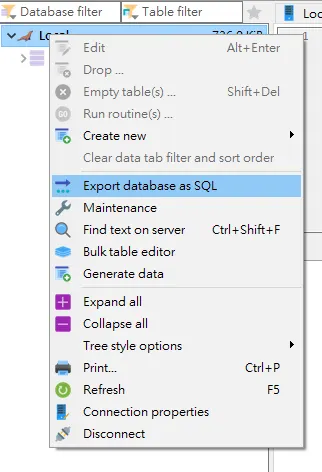
export database
進去後就是設定你想怎麼匯出,如果想跟你原本的 Database 完全一樣的話建議選擇 Delete + insert
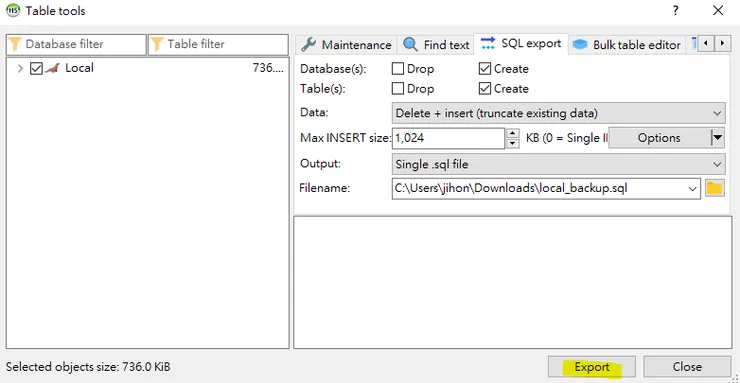
export 設定
完成後會產生一個 .sql 檔,此檔就是你完整的 Database
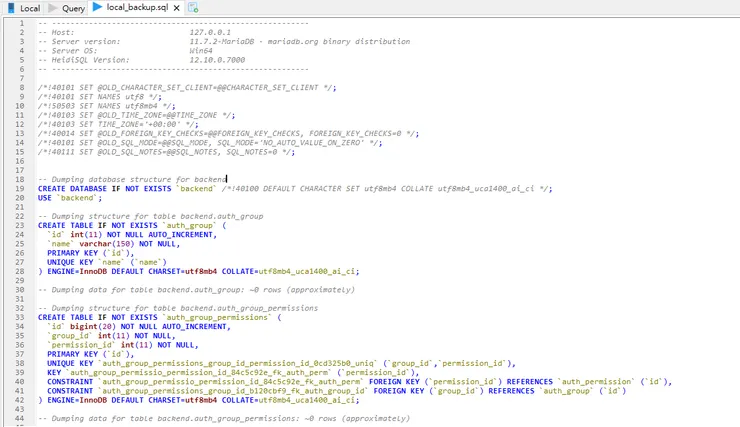
Database 的 .sql 檔
當然如果你的 .sql 檔案非常大的話,沒辦法用上圖的方式呈現,要直接在 Query 的位置點選右鍵 > Load SQL file 去執行
Load SQL file
基本上每個資料庫都會有配置的手動匯出功能,這也是最直觀、簡單的備份方式。
- Master & Slave
在資料庫系統中,Master-Slave 架構通常使用在大型的專案上,目的就是為了實現讀寫分離,降低資料庫的負載。兩者的主要功能如下:
- Master(主資料庫):主要負責處理所有的寫入操作,包含新增、修改、刪除,並記
錄這些變動在 Binary Log 之中。
- Slave(從資料庫):負責從 Master 複製資料,保持內容同步。一般都只處理讀取的操作,從資料庫不一定只會有一個,可以設計為多個。
*Slave 不會將資料寫回 Master
本文的重點不在操作細節部分,有興趣的讀者可以參考這篇,寫得蠻詳細的。不一定要使用兩個虛擬環境,只要在同一台電腦上建立兩個使用不同 port 的資料庫,也能達成相同效果。 - 使用腳本定期執行
這是最後採用的方法,通過腳本語言設定排程即可達到此效果,設定 Windows 排程器或是創建 Server 來定期執行都可以。
我們使用最熱門的 Python 來做說明,首先建立一個 .py 檔完成以下程式碼:
import subprocess
import datetime
import os
DATABASE_NAME = "backend"
BACKUP_DIR = "D:/DB_Backup"
MYSQLDUMP_PATH = "C:/Program Files/MariaDB 11.7/bin/mysqldump.exe"
timestamp = datetime.datetime.now().strftime("%Y%m%d_%H%M%S")
backup_filename = f"{DATABASE_NAME}_{timestamp}.sql"
backup_path = os.path.join(BACKUP_DIR, backup_filename)
os.makedirs(BACKUP_DIR, exist_ok=True)
dump_cmd = [
MYSQLDUMP_PATH,
"--defaults-file=C:/Users/jihon/.my.cnf", # DB 的登入帳號密碼設定檔
"--port=3307", # 這邊帶入你的 port
"--routines",
"--triggers",
"--single-transaction",
"--quick",
DATABASE_NAME
]
try:
with open(backup_path, "wb") as out_file:
result = subprocess.run(dump_cmd, stdout=out_file, stderr=subprocess.PIPE)
if result.returncode == 0:
print(f"✅ 備份成功:{backup_path}")
else:
print("❌ 備份失敗")
print("錯誤訊息:", result.stderr.decode(errors="ignore"))
except Exception as e:
print("❌ 執行備份時發生例外:", str(e))
較敏感的 DB 登入資訊建議另外寫入 .cnf 檔:
[client]
user=root
password=
完成後將路徑放到 dump_cmd 的指令內即可。執行後可看到:

備份成功
回到備份資料夾中可以看到已產生的 .sql 檔,這個就是完整的 DB 備份。
備份資料夾
本文分享研究 HeidiSQL 備份的幾種方式,從圖形介面操作到 Python 自動化腳本,希望對同樣正在找解法的你有所幫助。如果有更好的方式或任何建議,也歡迎一起討論,謝謝!


















