嗨 我是CCChen
iPAS AI應用規劃師-中級,考試樣題更新114年9月版本整理CCChen
文章最後有 新舊樣題版本的分析說明
注意重點: 114年第二次AI應用規劃師中級能力鑑定,試題將新增程式邏輯判斷題型,內容涵蓋 Python 語法與程式片段解析等,以加強對考生程式思維與實務應用能力的評估。敬請考生參考最新樣題,提前熟悉題型變化。



已從文件中整理出「iPAS AI 應用規劃師-中級能力鑑定-考試樣題」的題目
iPAS AI 應用規劃師~中級能力鑑定-考試樣題 114年9月版
以下是「iPAS AI 應用規劃師中級能力鑑定-考試樣題」中的所有題目、選項與答案
整理如下:
iPAS AI 應用規劃師-中級能力鑑定-考試樣題 114年9月版
◆ 科目一:人工智慧技術應用與規劃
1. 下列何者並未使用人工智慧(AI)或機器學習(ML)技術?
選項 (A) 使用一組預定義規則來確定最佳移動做法的象棋遊戲 (B) 使用深度神經網路來提高其準確性的語音識別系統 (C) 使用感測器和預定義的自動駕駛汽車-定義導航規則 (D) 使用自然語言處理算法來理解和反應用戶查詢的聊天機器人
正確答案 A
2. 在文本資料處理過程中,通常會需要「將接續的文本轉換為詞彙單位」,以便後續的處理。請問上述所指的是文本資料處理中的哪一個方法?
選項 (A) 詞形還原(Lemmatization) (B) 停用詞移除(Stopword Removal) (C) 斷詞(Tokenization) (D) 詞 頻 - 逆 向 文 件 頻 率 ( Term Frequency-Inverse Document Frequency, TF-IDF)
正確答案 C
3. 下列何者為自然語言處理(NLP)在機器學習應用中的主要用途?
選項 (A) 情緒分析 (B) 圖像識別 (C) 預測性維護 (D) 供應鏈優化
正確答案 A
4. 關於深度學習模型,下列敘述何者不正確?
選項 (A) 卷積神經網路(Convolutional Neural Networks)適合影像辨識 (B) ReLU(Rectified Linear Unit)比 tanh 和 Sigmoid 好,因為 ReLU 可以減緩梯度爆炸與消失的現象 (C) 遞迴神經網路(Recurrent Neural Networks)適合處理序列相關資料 (D) Elman 神經網路(Elman Neural Networks)適合處理影像辨識
正確答案 D
5. 下列何者為機器學習模型在業界部署的主要趨勢?
選項 (A) 越來越多地採用自動化機器學習(AutoML)技術 (B) 轉向使用更簡單的機器學習算法 (C) 基於雲的機器學習平台的使用率下降 (D) 依賴手動超參數調整進行模型優化 正確答案 A
6. 下列何者「最適合」使用迴歸(Regression)模型進行預測?
選項 (A) 根據顧客的購買行為,預測他最可能加入購物車的商品類別 (B) 根據病患的症狀與病史,判斷其可能患有的疾病類別 (C) 根據電影的特徵與用戶評分,推薦適合的電影類型 (D) 根據歷年銷售數據,預測明年某產品的總銷售額
正確答案 D
7. 附圖中,展示了電腦視覺辨識的幾項技術。請問下列選項中,何者正確配對了圖中(a)、(b)、(c)、(d)所代表的技術名稱?
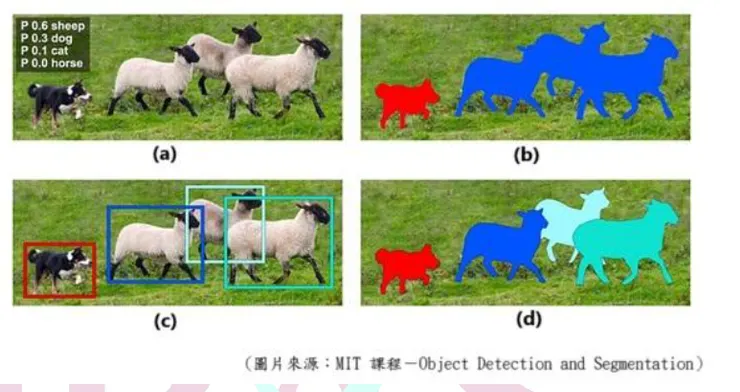
選項 (A) (a)實例分割(Instance Segmentation)(b)語義分割(Semantic Segmentation)(c)物件偵測(Object Detection)(d)圖像分類(Image Classification); (B) (a)圖像分類(Image Classification)(b)語義分割(Semantic Segmentation)(c)物件偵測(Object Detection)(d)實例分割(Instance Segmentation); (C) (a)圖像分類(Image Classification)(b)物件偵測(Object Detection)(c)語義分割(Semantic Segmentation)(d)實例分割(Instance Segmentation); (D) (a)圖像分類(Image Classification) (b)物件偵測(Object Detection)(c)實例分割(Instance Segmentation)(d)語義分割(Semantic Segmentation)
正確答案 B
8. 企業在生成式 AI 導入中,可選擇下列哪一種模型壓縮(Model Compression)技術以減少記憶體使用?
選項 (A) 參數剪枝; (B) 增加訓練數據量; (C) 增加模型層數; (D) 使用更高維數據 正確答案 A
9. 供應鏈攻擊(Supply Chain Attacks)如何影響企業內部 AI 系統安全?
選項 (A) 供應鏈攻擊的常見狀況,包括員工因釣魚郵件而被盜取帳號密碼; (B) AI 系統依賴的第三方開源模型或數據可能被植入惡意內容; (C) AI 系統只會受到 DDoS 攻擊影響,不會有供應鏈風險; (D) 供應鏈攻擊僅影響硬體層級、不影響 AI 模型
正確答案 B
10. 下列何者為自然語言處理(NLP)中的詞嵌入技術,能將文字轉換為向量以利機器學習處理?
選項 (A) TF-IDF (B) Word2Vec (C) Stop Words (D) Bag-of-Words
正確答案 B
11. 在多模態學習中,早期融合(Early Fusion)方法的主要特徵為何?
選項 (A) 將不同模態資料的輸出結果進行決策合併 (B) 在模型輸入階段或特徵提取階段整合不同模態資料 (C) 僅處理單一來源的資料輸入 (D) 利用注意力機制在深層隱藏層進行語意比對與融合
正確答案 B
12. 下列哪項技術最有助於強化醫療多模態 AI 系統在處理影像與文本數據時的整合能力?
選項 (A) 利用預先定義的規則產生診斷結果 (B) 僅使用 CNN 架構同時處理影像與文字資訊 (C) 利用單一模態資料建立通用醫療模型 (D) 採用 Transformer 架構整合醫療影像與臨床文本資訊
正確答案 D
13. 某線上音樂平台希望根據用戶的聽歌與查詢行為,將用戶劃分為不同的類型。若事前沒有定義用戶類型,下列哪一種模型最適合用於此任務?
選項 (A) 邏輯迴歸(Logistic Regression); (B) 決策樹(Decision Tree); (C) 基於密度之含噪空間聚類法(DBSCAN); (D) 線性迴歸(Linear Regression)
正確答案 C
14. 在訓練模型時,若數據中出現特徵尺度差異極大(例如:年齡為 0–100、收入為 0–1,000,000),容易導致模型偏向特定特徵。為提升模型效能與穩定性,以下哪一種預處理方式最能有效解決此問題?
選項 (A) 移除尺度較小的欄位以避免對模型影響過低 (B) 對所有特徵進行 Z-score 標準化(Standardization) (C) 將 特 徵 縮 放 至 0 – 1 區 間 進 行 最 小 - 最 大正 規 化 ( Min-Max Normalization) (D) 對所有數值欄位加上常數使其不為零
正確答案 B
15. 某企業即將部署 AI 模型至現有營運系統,進入系統整合測試階段。測試工程師需確認所有模組在實際環境中能正確協同運作。下列哪項驗證最應優先執行?
選項 (A) 確認模型在開發機上訓練集表現是否達標 (B) 驗證模型服務與資料平台、前後端介面協同是否正常,資料格式與流程一致性是否維持 (C) 檢查開發團隊提交程式碼時是否有依照 Git commit message 規範 (D) 審閱模型報告與 API 文件的格式是否符合交付標準
正確答案 B
◆ 科目二:大數據處理分析與應用
1. 在巨量資料分析班中,共有一年級至四年級,每個年級有 50 個學生,且學生身高呈常態分佈。下列敘述何者不正確?
選項 (A) 要檢測一年級和二年級的平均身高是否有差異,可以利用 t 檢定 (B) 要檢測一年級、二年級、三年級之間的平均身高是否有差異,可以利用 t 檢定 (C) 要檢測二年級、三年級、四年級之間的平均身高是否有差異,可以利用 F 檢定 (D) 要檢測一年級的平均身高是否等於 170 公分,可以利用卡方檢定
正確答案 D
2. 關於接受者操作特徵(ROC)曲線,下列敘述何者正確?
選項 (A) ROC 曲線繪製了真陽性率與假陽性率的關係 (B) ROC 曲線用於評估模型的準確性 (C) ROC 曲線下的面積(AUC-ROC)始終等於 1 (D) ROC 曲線只適用於二元分類問題
正確答案 A
3. 下列何者不屬於特徵工程(Feature Engineering)?
選項 (A) 轉換(Transformation) (B) 萃取(Extraction) (C) 挑選(Selection) (D) 預測(Prediction)
正確答案 D
4. 拉拉網路商城的老闆擬透過機器學習的方式,利用過往的產品銷售資料,預測下一季的產品銷售數量,以調整現有的庫存水位。下列哪一個類型的模型,比較適合應用在老闆期望的預測目標?
選項 (A) 決策樹分類器(Decision Tree Classifier) (B) K-means 分群(K-means Clustering) (C) 主成份分析(Principal Component Analysis, PCA) (D) 線性迴歸(Linear Regression)
正確答案 D
5. 對於低結構化的文本或圖像資料,下列哪一種特徵工程(Feature Engineering)方法最為適用?
選項 (A) 特徵改善(Feature Improvement) (B) 特徵建構(Feature Construction) (C) 特徵學習(Feature Learning) (D) 特徵選擇(Feature Selection)
正確答案 C
6. 下列哪種方法屬於非監督式學習中的降維技術?
選項 (A) K-均值聚類((K-means) (B) 隨機森林(Random Forest) (C) 支持向量機(SVM) (D) 主成分分析(PCA)
正確答案 D
7. 異常值偵測使用 IQR(Interquartile Range)法時,下列哪一種範圍外的數值會被視為異常?
選項 (A) 超過 Q2 ± 2×IQR (B) 高於 Q1 − IQR 或低於 Q3 + IQR (C) 高於 Q1 − 2×IQR 或低於 Q3 + 2×IQR (D) 低於 Q1 − 1.5×IQR 或高於 Q3 + 1.5×IQR
正確答案 D
8. 差分隱私(Differential Privacy)在數據應用中的目的為何?
選項 (A) 添加隨機噪聲掩蓋個體訊息 (B) 加密所有數據 (C) 移除多數類樣本 (D) 提高數據完整性
正確答案 A
9. 若使用主成分分析(PCA)將資料降維至兩個主成分,這表示哪一種情況?
選項 (A) 僅保留兩筆樣本資料進行模型訓練 (B) 將原始高維資料轉換為兩個主成分表示 (C) 每筆資料僅保留兩個原始欄位的數值 (D) 模型將限制只能用於分類任務
正確答案 B
10. 假設有一組成績資料呈現常態分配,平均數為 70,標準差為 10,若某位學生的成績為 90,該學生的 Z 分數約為多少?
選項 (A) 0 (B) 1 (C) 2; (D) 3
正確答案 C
11. 在 AI 倫理治理的背景下,「透明性(Transparency)」通常是指什麼?
選項 (A) AI 系統的運算速度公開; (B) AI 系統僅使用公開數據; (C) AI 系統決策流程清晰且可解釋; (D) 所有 AI 模型都是開源的
正確答案 C
12. 若企業希望即時監控交易異常,應選擇下列哪一類數據處理架構?
選項 (A) 批次式資料倉儲 (B) 離線式資料湖 (C) 串流處理系統 (D) 冷資料備援架構
正確答案 C
13. 為了分析社群網路使用者之間的互動結構,應使用下列哪種分析方法?
選項 (A) 文字探勘 (B) 主成分分析 (C) 圖論分析 (D) 分群分析
正確答案 C
14. 為了加速大數據環境下的 AI 模型訓練,以下哪一項為常見技術?
選項 (A) 早期停止(Early Stopping) (B) 批次分群(Mini-batching) (C) 混合精度訓練(Mixed Precision Training) (D) 主成分分析(PCA)
正確答案 C
15. 考慮使用 CIFAR-10 資料集進行資料處理,資料包括 32×32 像素的多筆彩色照片。下列程式碼的資料處理,請選出正確的選項。
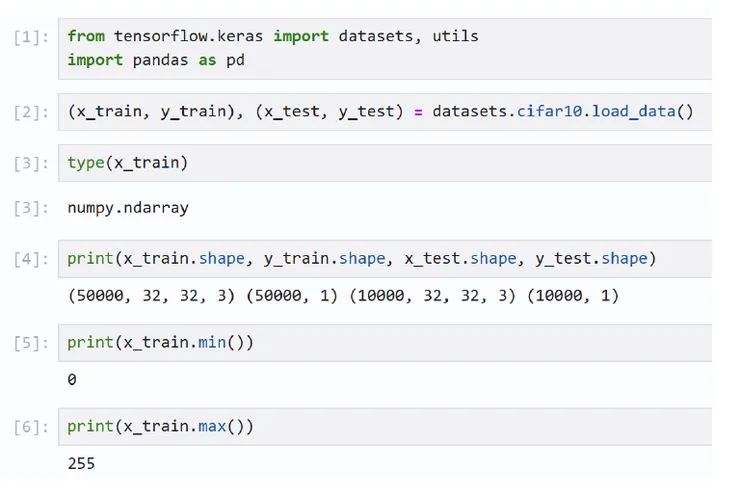
選項 (A) 訓練集(x_train)資料集個數為 100000 筆 (B) 測試集(x_test)資料集個數為 10000 筆 (C) 訓練集(x_train)是 Pandas 資料框(DataFrame)物件 (D) 如果希望將訓練集(x_train)像素值轉換為的範圍,則可以輸 入:x_train = x_train.astype('int32') / 255.0
正確答案 B
◆ 科目三:機器學習技術與應用
1. 在 MapReduce 計算框架中,關於 Map 和 Reduce 所負責處理資料的問題,下列敘述何者正確?
選項 (A) Map:一組資料映射成另一組資料;Reduce:統合與歸納資料 (B) Map:地圖式的搜索資料;Reduce:統合與歸納資料 (C) Map:一組資料映射成另一組資料;Reduce:過濾不符合的資料 (D) Map:一組資料映射成另一組資料;Reduce:生成更多的資料
正確答案 A
2. 下列何種卷積神經網路(Convolution Neural Networks, CNN)是將卷積層加寬而非加深?
選項 (A) R-CNN (B) Inception (C) ResNet (D) VGG19
正確答案 B
3. 當模型的訓練誤差(Training Error)低、但測試誤差(Test Error)很大時,這通常是在訓練過程中產生下列哪一種情況?
選項 (A) 模型的泛化能力強 (B) 模型出現過度擬合(Overfitting) (C) 模型出現欠擬合(Underfitting) (D) 訓練資料和測試資料之間沒有相關性
正確答案 B
4. 下列哪一種指標通常用於評估迴歸模型的效能?
選項 (A) R² (B) F1-分數 (C) 曲線下面積(AUC) (D) Precision
正確答案 A
5. 近年來,深度學習研究與應用蓬勃發展,但數據本身可能存在什麼潛在問題?
選項 (A) 數據標註品質鮮少被討論,但它卻直接影響模型性能 (B) 數據品質是完美可信賴的 (C) 大部分情況下,數據不存在類別不平衡問題 (D) 數據不需要領域知識的輔助
正確答案 A
6. 在分類任務中,深度學習模型通常搭配哪一種輸出函數?
選項 (A) Tanh (B) ReLU (C) Sigmoid 或 Softmax (D) Dropout
正確答案 C
7. 下列哪一種學習任務不適合使用監督式學習方法處理?
選項 (A) 客戶信用風險分類 (B) 預測未來銷售額 (C) 找出資料中的潛在群集 (D) 判斷影像是否為貓或狗
正確答案 C
8. 在神經網路中,前向傳播(Forward Propagation)主要依賴下列哪一種數學操作?
選項 (A) 機率積分 (B) 矩陣乘法與向量內積 (C) 對數變換 (D) 條件機率推論
正確答案 B
9. 特徵縮放(Feature Scaling)中,下列何者為標準化(Standardization)的主要作用?
選項 (A) 將數據範圍限制在 0 到 1 且標準差-1 (B) 使數據平均值為 0 且標準差為 1 (C) 移除數據中的異常值 (D) 增加特徵間的相關性
正確答案 B
10. 關於準確率(Accuracy)的計算方式,下列何者正確?
選項 (A) TP/(TP+FP) (B) (TP+TN)/(TP+FP+TN+FN) (C) TN/(TN+FP) (D) TP/(TP+FN)
正確答案 B
11. 關於損失函數(Loss Function)的主要功能,下列何者正確?
選項 (A) 記錄模型預測歷史 (B) 計算模型結構複雜度 (C) 控制模型的學習率 (D) 衡量模型預測與真實值之間的誤差
正確答案 D
12. 關於歐盟《一般資料保護規則(GDPR)》,所謂的被遺忘權(Right to be Forgotten)主要賦予資料主體哪一項權利?
選項 (A) 要求平台永久備份其個資以防遺失 (B) 在符合條件下請求刪除其個人資料 (C) 將個人資料轉換為匿名格式保存 (D) 限制企業將資料輸出至境外伺服器
正確答案 B
13. 在進行模型訓練前,若針對資料中不同群體(例如分類標籤)之間樣本數量不平衡的情況進行比例調整,此方法通常屬於下列哪一種技術?
選項 (A) 資料重抽樣 (B) 特徵選擇 (C) 模型正則化 (D) 超參數調整
正確答案 A
14. 在優化器中,哪一個方法會自動調整每個參數的學習率,特別適用於稀疏資料?
選項 (A) Momentum (B) Adagrad (C) Adam (D) SGD
正確答案 B
15. 某零售公司希望利用顧客的年齡與每月消費金額,預測顧客是否為高價值顧客。提供相關資料 data.csv,包含欄位 Age、Spending、HighValue。請將下列程式碼片段依正確順序排序,以完成模型的建立與預測。
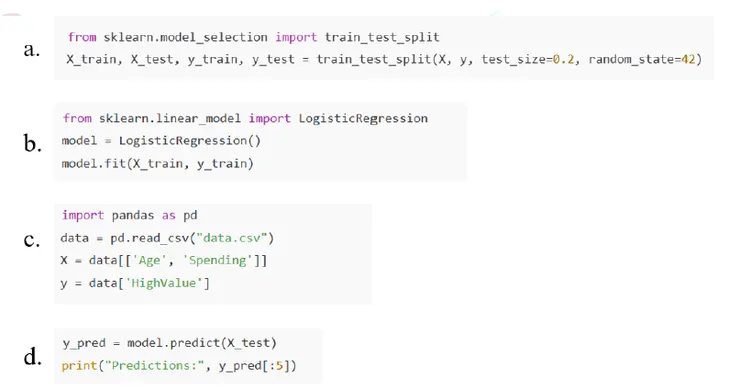
選項 (A) c → a → b → d (B) a → c → b → d (C) c → b → a → d (D) b → a → c → d
正確答案 A
根據您提供的文件,本報告將專業分析 iPAS AI 應用規劃師中級能力鑑定樣題兩個版本(114.01 版與 114.09 版)之間的差異。
iPAS AI 應用規劃師-中級鑑定樣題版本差異專業分析報告
中級樣題從 114.01 版更新至 114.09 版,核心趨勢是題量三倍擴充,內容方向由基礎技術認知,深化至系統部署、多模態應用、進階數據分析與專業治理等高階實務知識。
一、 比較結果與差異分析(一一條列)
1. 總題數與比例層面:
- 總題數大幅擴增: 舊版樣題(114.01 版)總題數為 15 題(每個科目 5 題)。新版樣題(114.09 版)總題數擴增至 45 題(每個科目 15 題),題量增加了 200%。
- 科目結構維持不變: 鑑定科目仍保持為三科:科目一:人工智慧技術應用與規劃(L21)、科目二:大數據處理分析與應用(L22)、科目三:機器學習技術與應用(L23)。每個科目的相對權重(各佔三分之一)在樣題中保持平均。
2. 內容繼承與擴展:
- 舊題完全保留並擴充: 新版樣題保留了舊版中所有 15 題的內容和題號順序,並在此基礎上新增了 30 題(每個科目各新增 10 題),展現了內容的持續累積和深化。
3. 難度與專業度層面:
- 難度顯著提升: 舊版著重於基礎概念(如:NLP 的基本用途、MapReduce 的功能、過擬合的定義),新版則增加了對專業細節和應用場景的考核,例如:特定的卷積網路架構(如 Inception)、特徵縮放的實際效果(如標準化)、以及串流數據處理架構的選擇。
- 技術應用層次提高: 新增內容要求考生理解系統級別的設計,如模型壓縮技術(參數剪枝)、多模態數據整合採用 Transformer 架構、以及 AI 系統部署前的系統整合測試重點 (Q15, L21)。
4. 題型變化層面:
- 新增程式碼邏輯題: 新版在科目三增加了要求考生對程式碼片段進行邏輯排序以完成模型建立與預測的題目 (Q15, L23),反映了鑑定對實作流程理解的要求。
- 強化視覺分析題: 新版強化了對圖像和電腦視覺(CV)技術的識別,如要求考生能正確配對圖像分類、物件偵測、語義分割和實例分割等技術的圖示 (Q7, L21)。
5. 範圍與方向轉變層面:
- 統計與數據分析深化: 統計檢定實務化: 新增了關於假設檢定(如 t 檢定、F 檢定)的適用性判斷,並要求計算 Z-score 判斷常態分佈數據點的位置。 降維技術應用: 明確考核非監督式學習中的降維技術 PCA 的作用。
- AI 治理與倫理的實務化: 新版涵蓋了數據隱私技術,如差分隱私(Differential Privacy)的目的,以及對 GDPR 中被遺忘權的理解。 納入了 AI 倫理治理中「透明性」 的具體定義。
- 大數據架構與優化: 強調對即時處理架構的掌握,如要求判斷串流處理系統在即時監控交易異常中的適用性。 增加了對模型訓練優化技術的了解,例如用於加速訓練的混合精度訓練(Mixed Precision Training) 以及適用於稀疏資料的優化器 Adagrad。
- 多模態與生成式 AI 深度: 擴展了多模態學習的知識,涵蓋了**早期融合(Early Fusion)**的特徵 和醫療領域整合技術(如 Transformer)的應用。 增加了 AI 系統安全的內容,例如供應鏈攻擊對 AI 系統的影響。
二、 新版中級樣題學習準備建議(5 點)
中級鑑定要求從基礎知識邁向技術應用與系統規劃,建議準備方向需更具專業深度和實戰性:
- 深入理解機器學習原理與數學基礎: 準備不僅應涵蓋模型的優缺點,更要掌握深度學習中的數學運算(如前向傳播的矩陣乘法與向量內積)和核心概念(如標準化的目的)。
- 精通數據分析的實用技術與統計推論: 除了大數據特性,應加強對敘述性統計的實務應用,包括計算 Z-score 和 IQR 法判斷異常值。同時,要能區分並選擇正確的統計檢定方法(如 t 檢定、F 檢定),並應用圖論分析社群網路結構。
- 掌握 AI 系統部署與性能優化技巧: 將準備重點放在 L21302 AI技術系統集成與部署 相關內容。理解模型訓練的加速技術,如混合精度訓練,以及模型部署前的系統整合測試步驟,確保系統的穩定性與可用性。
- 專注於多模態應用與進階 NLP 技術: 應超越單模態學習,深入學習多模態數據的融合策略(如 Early Fusion),以及 Word2Vec 等詞嵌入技術在 NLP 中的應用。同時要能識別電腦視覺中的各類別技術(如實例分割、語義分割)。
- 強化 AI 治理、隱私保護與架構選擇: 準備數據治理和法律遵循的內容,例如 差分隱私 的目的 和 GDPR 被遺忘權 的含義。在系統架構上,要能根據業務需求(如即時監控)選擇合適的處理架構(如串流處理系統)。
針對 iPAS AI 應用規劃師中級能力鑑定中,新增「程式邏輯判斷題型」所提供的學習重點與準備建議。
此新增題型旨在加強評估考生在 程式思維與實務應用能力。
根據最新樣題與鑑定範圍,此類程式邏輯判斷題主要落在**科目三:機器學習技術與應用(L23)**的範疇,並可能結合科目一(L21)和科目二(L22)的數據處理與模型選擇知識。
程式邏輯判斷題型的主要學習重點
新版中級鑑定中的程式邏輯題(例如:中級樣題科目三 Q15)通常要求考生能夠理解並排列程式碼片段,以完成特定的機器學習流程。因此,學習重點應涵蓋以下知識領域:
1. 機器學習建模流程(L232 / L233)
程式邏輯題的核心是判斷一個完整的機器學習專案從數據到模型的流程順序。考生必須熟悉以下步驟的邏輯先後關係:
- 數據準備與特徵工程(L23301): 識別讀取數據、數據清洗與預處理、特徵工程(如特徵縮放、數據集切分)的程式碼片段。
- 模型選擇與架構設計(L23302): 識別初始化、選擇或設定特定模型(如分類器或迴歸模型)的程式碼。
- 模型訓練與擬合: 識別使用訓練數據進行模型訓練(fit() 或 train)的步驟。
- 模型評估與預測(L23303): 識別使用測試集進行預測(predict())和計算評估指標的步驟。
2. Python 語法與函式庫的應用
雖然考試主要考核邏輯判斷而非程式編寫,但需要能識別與判讀機器學習相關 Python 函式庫的關鍵程式碼:
- 資料操作與處理: 熟悉 Pandas/Numpy 在數據讀取、資料集切分、陣列操作(例如:轉換像素值範圍 x_train = x_train.astype('int32') / 255.0)上的基本用法。
- 機器學習函式庫 (Scikit-learn/TensorFlow/PyTorch): 識別模型導入(from sklearn.linear_model import LogisticRegression)、模型實例化、訓練 (.fit()) 和預測 (.predict()) 的標準程式碼結構。
3. 數據與模型的專業知識結合(L213 / L222 / L224)
程式邏輯題會將數據分析與 AI 應用規劃的知識點嵌入程式碼情境中,要求考生能結合專業判斷:
- 數據集屬性判讀: 能夠從程式碼或情境中判斷數據集的大小、維度、資料型態(如:CIFAR-10 數據集的大小和屬性)。
- 預處理方法的目的: 理解特定程式碼(如特徵縮放、重抽樣)背後的數學和統計目的,以判斷其在流程中的正確位置。
- 模型選擇與適用性: 判斷所提供的程式碼是否適用於情境中描述的任務(例如:使用分類模型來解決分類問題)。
學習準備建議(5 點)
針對新增的程式邏輯判斷題型,中級考生應採取以下準備策略:
- 熟練機器學習標準化流程: 務必掌握從數據載入、預處理(如特徵縮放、處理缺失值)、訓練模型、到評估結果的完整 邏輯順序。應能清晰區分數據準備、模型訓練和模型驗證這三大階段。
- 注重 Python 機器學習框架的關鍵函式: 雖然不要求撰寫程式,但需熟悉常用的機器學習套件(如 Scikit-learn 或深度學習框架)中,用於模型訓練、預測、資料切割等功能的關鍵函式名稱和呼叫順序。
- 練習「流程排序」題型: 針對樣題中出現的程式碼排序題,多加練習不同機器學習任務(如分類、迴歸)的標準流程,確保能夠快速判斷各程式碼片段在整個專案中的執行順序。
- 理解數據處理程式碼的技術意涵: 不僅要看程式碼的表面,更要理解程式碼背後處理的數據維度、資料格式或轉換目的(例如:將像素值轉換到 範圍的程式碼)。
- 結合 L23 的基礎數學知識: 程式邏輯題可能結合數學基礎知識,例如理解**特徵縮放(標準化)**的程式碼效果(使數據平均值為 0 且標準差為 1),以確保程式碼的正確性符合理論依據。



















