在 Kubernetes 的維運實務中,我們常被要求設定 ResourceQuota、LimitRange,並在每個 Pod YAML 中精確定義 CPU 與 Memory 的 Requests/Limits。但這些設定究竟是為了什麼?當你寫下 cpu: "1" 時,底層系統發生了什麼事?
1. 為什麼要設定 Limit 和 Quota?(The Why)
在一個共享的 Kubernetes 叢集中,如果不加限制,任何一個程式都可能因為 Memory Leak 或無窮迴圈,耗盡整個節點的資源,導致關鍵服務崩潰。這就是標準的「資源爭用 (Resource Contention)」或稱為「嘈雜鄰居 (Noisy Neighbor)」問題。
為了實現穩定的多租戶 (Multi-tenancy) 環境,Kubernetes 提供了兩層管理機制。
1.1 第一層機制:Namespace 級別的總量控制 (ResourceQuota)
ResourceQuota 是防止個別團隊過度消耗整個叢集資源的基礎。它限制的是該 Namespace 內所有 Pod 加總起來的資源用量。
- 情境:規定
dev團隊最多只能使用 4 顆 CPU 和 16GB 記憶體。 - 機制:一旦超過上限,API Server 會在 Admission 階段直接拒絕任何新 Pod 的建立請求 (403 Forbidden)。
範例:ResourceQuota YAML
apiVersion: v1
kind: ResourceQuota
metadata:
name: team-quota
namespace: dev-team
spec:
hard:
# 計算資源總量限制
requests.cpu: "4"
requests.memory: "16Gi"
limits.cpu: "8"
limits.memory: "32Gi"
# 物件數量限制 (防止惡意建立大量 Pod 癱瘓系統) # optional
count/pods: "30"
count/services.loadbalancers: "2" # 限制 LB 數量以控制雲端成本
1.2 ResourceQuota 的協同運作:LimitRange
許多使用者啟用 ResourceQuota 後,發現 Pod 無法啟動,錯誤訊息顯示 failed quota: ...。
- 原因:這是因為 Kubernetes 需要明確的數值來進行加總計算,若 Pod 未定義資源需求,系統將無法判斷配額是否足夠,因此會拒絕建立請求。
- 解法 (LimitRange):LimitRange 負責管理「個別 Pod」並提供「預設值」。
- 設定:每個 Pod 預設給 500m CPU (Default),最大不超過 2 CPU (Max)。
- 效果:即使開發者未在 Pod/Deployment YAML 中定義 resources,LimitRange 也會自動補上預設值,讓 ResourceQuota 能順利計算並放行。
範例:LimitRange YAML
apiVersion: v1
kind: LimitRange
metadata:
name: default-resource-limits
namespace: dev-team
spec:
limits:
- type: Container # 以「container 為單位」來判定。
# 也可以使用 "type: Pod" 來判定。
default: # 預設 Limit (若沒寫 limits 會自動套用此值)
cpu: "1"
memory: "1Gi"
defaultRequest: # 預設 Request (若沒寫 requests 會自動套用此值)
cpu: "500m"
memory: "512Mi"
max: # 單一 Pod 能設定的最大上限 (超過此值會被拒絕)
cpu: "2"
memory: "4Gi"
min: # 單一 Pod 能設定的最小下限
cpu: "100m"
memory: "128Mi"
2. 定義邊界:Pod 級別的 Requests 與 Limits
當請求通過了上述的治理層檢查,進入到 Pod 層級時,我們通常設定兩個數值:Requests 和 Limits。這兩個數值的組合不僅影響排程,更決定了 Pod 的 QoS 類別 (Quality of Service Classes),這是節點資源不足時的處理依據。
2.1 參數解釋
- Requests (請求值):這是給 Kubernetes Scheduler 看的。Scheduler 根據這個數值決定把 Pod 放在哪個節點上(確保節點有足夠的剩餘空間)。
- Limits (限制值):這是給 Linux Kernel 看的。這是硬上限,一旦超過,Process 就會被節流 (Throttled) 或終止 (OOM Killed)。
範例:Pod Resources YAML
apiVersion: v1
kind: Pod
metadata:
name: resource-demo
namespace: dev-team
spec:
containers:
- name: app
image: nginx
resources:
requests:
# Scheduler 會確保節點至少有 0.25 CPU 和 64Mi RAM 可用
cpu: "250m"
memory: "64Mi"
limits:
# Kernel Cgroups 會執行此硬上限
# CPU 超過 0.5 會被 Throttled (變慢)
cpu: "500m"
# Memory 超過 128Mi 會被 OOM Killed (重啟)
memory: "128Mi"
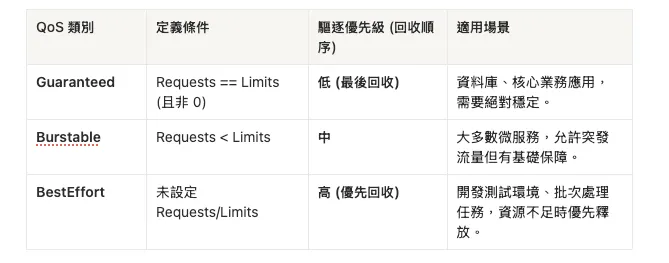
2.2 QoS (Quality of Service) 類別與驅逐順序
當節點 (Node) 本身資源耗盡發生 Node-pressure Eviction 時,Kubelet 會根據 QoS 類別來決定優先驅逐哪些 Pod,而不僅僅是看誰用最多。
QoS 類別定義條件驅逐優先級 (回收順序)適用場景:
3. 核心機制:Runtime 如何使用 Cgroups (The How)
當你在 YAML 寫下 resources: limits: cpu: "1" 時,這行文字最終之所以能生效,完全是因為底層的 Container Runtime (如 runc) 操作了 Linux Kernel 的 Control Groups (Cgroups)。
3.1 指令下達與傳遞
- Kubelet:讀取 Pod YAML,發現使用者設定了
memory: 512Mi。 - CRI 溝通:Kubelet 透過 CRI (Container Runtime Interface) 告訴 High-Level Runtime (如 containerd):「幫我啟動一個容器,並將記憶體上限設定為 512MB」。
3.2 實作配置 (Runtime 的工作)
High-Level Runtime (containerd) 會呼叫 Low-Level Runtime (runc)。這時,runc 會執行關鍵動作:
- 在宿主機的 Cgroup 階層中建立一個對應此容器的資料夾。
- 將數值
536870912(即 512MB 的 Bytes 值) 寫入該 Cgroup 資料夾下的設定檔中。
注意:Cgroup 版本差異 上述提到的路徑 /sys/fs/cgroup/memory 與檔案 memory.limit_in_bytes 是 Cgroup v1 的標準。 若您的節點使用較新的 Linux Kernel (如 Ubuntu 22.04+),可能會啟用 Cgroup v2 (Unified Hierarchy)。此時路徑會變為 /sys/fs/cgroup/...,且設定檔名稱會變為 memory.max。雖然檔案位置不同,但底層概念是一致的。
3.3 核心執行 (Kernel 的工作)
一旦設定檔被寫入,Linux Kernel 就接手了。Kernel 會根據這個 Cgroup 的設定,嚴格監控該容器內所有 Process 的資源用量。
- Memory:一旦用量超過設定值,Kernel 會觸發 OOM Killer。
- 實務細節:OOM 的兩種層級
- Pod 層級 (Cgroup OOM):Pod 用量超過 Limit,Kernel 精準終止該 Pod 內的 Process。
- Node 層級 (System OOM):整台機器記憶體不足,Kernel 會隨機終止機器上的 Process (有可能誤殺 Docker Daemon 或 Kubelet 導致節點異常)。這就是為什麼設定 Limit 保護 Node 如此重要。
- CPU:一旦用量超過設定的時間片 (Quota/Period),Kernel 會強制暫停該 Process 的執行 (Throttling),直到下一個週期。
一句話總結:ResourceQuota 是政策,Cgroups 是執行機制,而 Runtime 是負責傳達命令的組件。
4. 關鍵配置細節:Cgroup Driver 的不一致
這是資源管理中常見的配置問題,也是生產環境中導致節點不穩定的主要原因之一。Runtime 可以透過兩種方式來修改 Cgroups:
- cgroupfs 驅動:Runtime 直接去寫
/sys/fs/cgroup下的檔案。這是最原始的做法。 - systemd 驅動:Runtime 發送請求給 init system (systemd),請 systemd 幫忙建立 Cgroup。
配置衝突的後果: 如果您的 Kubelet 設定為使用 systemd (現代 Kubernetes 的預設),但底層的 Runtime (如 containerd) 卻設定為使用 cgroupfs,系統就會出現「兩套 Cgroup 管理者」。
- 影響:當系統負載變高時,Kubelet 與 Runtime 對資源的認知會不同步,可能導致 Kubelet 誤判資源壓力而驅逐 Pod,或是 Cgroup 限制未生效導致節點不穩。
- 最佳實務:務必確保 Kubelet 和 Container Runtime 的 Cgroup Driver 一致,通常建議統一使用 systemd。
如何檢查 Cgroup Driver? 您可以在節點上執行以下指令來確認當前的配置狀態:
# 檢查 Container Runtime (containerd) 的設定
crictl info | grep -i "cgroup"
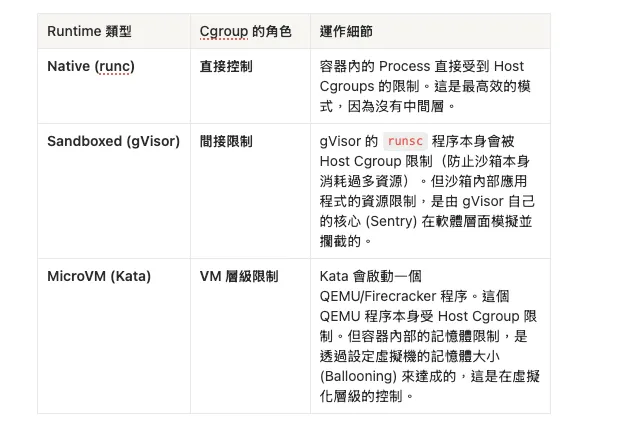
5. RuntimeClass 視角:不同 Runtime 的 Cgroup 行為
隨著技術演進,我們開始使用 RuntimeClass 來調度不同的 Runtime。它們在處理資源限制時的行為也有所不同:
6. 總結
Kubernetes 的資源管理是一個從上到下的完整體系:
- ResourceQuota & LimitRange (治理層):決定了「誰」可以使用「多少」資源,防止多租戶間的資源爭用。
- Pod Requests/Limits (宣告層):開發者宣告需求,並透過 QoS 類別 決定資源不足時的處理順序。
- Runtime (配置層):containerd/runc 負責將這些抽象需求轉譯為作業系統的設定。
- Cgroups (執行層):Linux Kernel 真正執行資源隔離與限制,並區分 Cgroup OOM 與 System OOM。
理解從上到下的關係,才能在遇到 OOMKilled 或效能瓶頸時,準確判斷是策略設定問題,還是底層實作的配置誤差,或是主機資源真的不足夠了。




















