這篇整理新考綱裡「合規」這塊的筆記。這部分的權重在 2026 版考綱拉得很高,自己讀下來發現,合規不是附屬在技術之後的章節,而是影響 AI 專案能不能上線的前置條件。整理成幾個區塊記下來。
為什麼合規會是考題的重點區
自己第一次讀這塊的時候,心裡的想法跟很多人一樣:這是 AI 證照,為什麼要讀這麼多法律條文。後來讀完會發現,考綱這個方向的調整是呼應一個實務現場的狀況——模型準確率再高,如果合規沒過關,整個專案可能在上線前就得銷毀。
這不是誇張的描述。在金融、醫療、個資密集的場景裡,合規未通過等於專案從零開始。規劃師如果只會算準確率、不會評估合規風險,這個角色在實務上的價值就很有限。考綱把這塊拉高,是在校正這個職能定位。
一、GDPR:三個容易被寫進情境題的權利
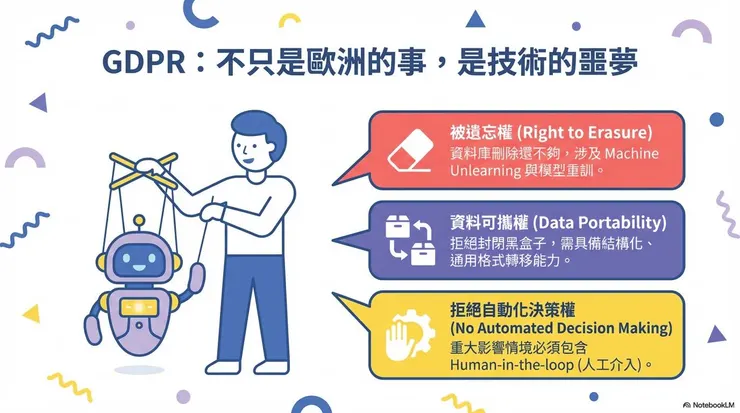
GDPR 是歐盟的一般資料保護規範。就算服務在台灣,只要使用者包含歐盟公民,就會適用。自己讀考綱時把三個權利整理出來:
被遺忘權(Right to Erasure)——使用者撤回同意後,資料要從系統中刪除。但在機器學習的場景裡會延伸出一個技術難題:如果這個人的資料已經融合在模型參數裡,光刪資料庫不夠,還要處理「機器學習遺忘」(Machine Unlearning)。考題如果問「模型已訓練完成後使用者要求刪除資料該怎麼處理」,方向會往這邊走。
資料可攜權(Data Portability)——使用者有權要求把自己的資料打包帶走,甚至轉交給別的服務。這意味著資料架構從設計初期就要考慮標準化、可匯出。
拒絕自動化決策權——在重大決策場景(貸款、錄取、醫療判斷),使用者有權要求人工介入。純 AI 決策不能單獨成立,系統要設計 Human-in-the-loop 的環節。這點跟前面整理過的歐盟 AI 法案「人類監督」是同一個脈絡。
二、台灣個資法(PDPA)的核心陷阱:特定目的限制
台灣個資法整體沒有 GDPR 那麼複雜,但有一個容易被忽略的點——特定目的限制。
舉例來說,公司五年前收集客訴錄音時,同意書寫的目的是「提升服務品質」。現在想拿這批錄音訓練語音生成 AI,即使資料就在公司手上,這也是違反特定目的限制。要嘛重新取得同意,要嘛不能用。
這個概念的重點是:擁有資料不代表擁有訓練權。考題會用「公司已有 XX 資料,直接拿來訓練 XX 模型」這種描述來測,要能辨認出「目的變更」這個關鍵字。
三、產業專用規範:醫療與金融的硬門檻
醫療 AI(HIPAA)——HIPAA 規定了 18 項識別符,包含姓名、地址、日期、電話、IP 位址、設備序號等等。很多人以為把姓名拿掉就是去識別化,但只要 18 項裡任何一項沒處理乾淨,這份資料就是違規。考題會用「某團隊已遮蔽姓名與身分證字號」這種敘述來測,要能看出其他識別符沒處理的漏洞。
金融 AI(PCI-DSS)——信用卡相關的應用要注意 CVV 這類敏感資訊,依規範連加密儲存都不允許。這不是技術問題,是合規的硬規則。
四、整理成檢核步驟
自己把這些規範濃縮成三個檢核步驟,方便面對情境題時快速判斷:
去識別化策略——依據 HIPAA 或相關標準處理 18 項識別符,不是拿掉姓名就算結束。
目的檢核——確認當初收集資料時的同意書範圍,有沒有涵蓋現在要做的用途。
最小化原則——只拿模型訓練真正需要的欄位,不要因為方便就撈整個資料庫。這個原則在考題裡常被用來當正確答案的方向。
自己整理下來的備考方向
一、GDPR 的三個權利要跟技術層對應起來讀。被遺忘權連到 Machine Unlearning、資料可攜權連到資料架構標準化、拒絕自動化決策連到 Human-in-the-loop。這樣記比背條文快。
二、「特定目的限制」是台灣個資法的考點核心。看到情境題裡出現「公司已有現成資料」「拿來做新用途」這類描述,要先想到這條。
三、醫療跟金融的產業規範各自有死線——HIPAA 的 18 項、PCI-DSS 的 CVV 不得儲存。這兩條是硬記的知識點,考題方向很固定。
合規這塊在新考綱的權重跟治理章節是連動的。把這兩塊一起讀,對情境題的判斷會比較完整。



