
大家好!簡單介紹一下我所製作的中華職棒球員分類模型。
所有資料都是從BASEBALL REFERENCE網站抓的資料檔,我選了2016至2020年度中華職棒的所有選手資料,因為選手每年的資料都會被記錄下來,所以最多會有同一位球員的五筆年度資料。
首先,先找一下各隊年度勝率和該年隊上球員的平均打擊表現的相關係數,發現打擊率和勝率最有相關,其次是上壘率,與想像的結果相符我用了紅框中圈起來的部分作為參考變項,因為這些打擊表現指標和勝率有著一定的相關(r>0.5)。

第二步驟是抓出各年度球員的資料,結合上述四個與全壘打率、被保送率、被三振率和犧牲打率做主成分分析(Principal component analysis),把這幾個變項做維度縮減,我最後只選定了兩個主成分當作變項,兩個主成分累積總變異數大概有到70%,還可以接受。
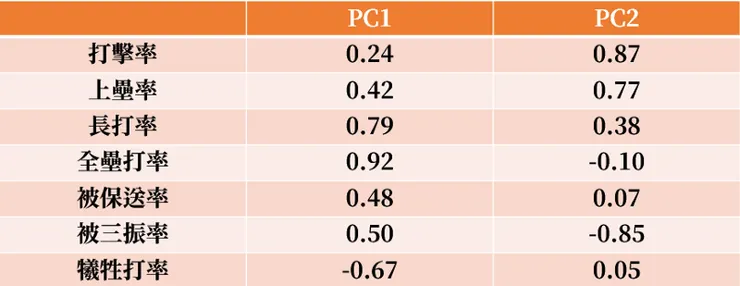
可以看到第一主成分主要由與長打有關的變項所構成,主要包含了長打率、全壘打率;第二主成分主要由打擊率、上壘率和負向的被三振率組成,有了這兩個主成分後,就把這五年所有球員(548筆)依照這兩個主成分做群集分析。
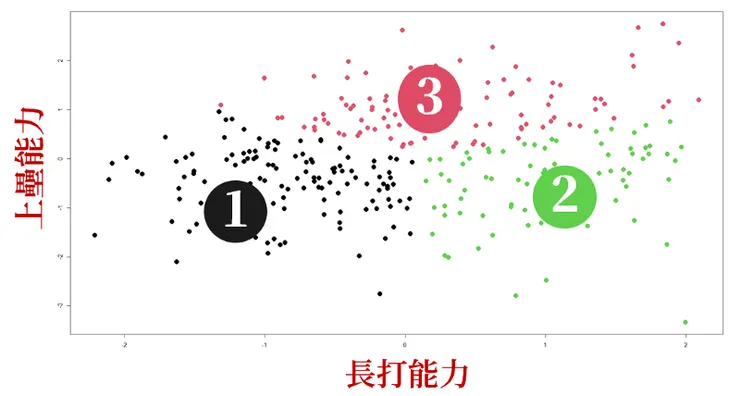
在群集分析中,我選擇k=3的分群結果(經過嘗試發現分成三群的結果較容易解釋),以下列出我對這三群打者的命名。
第一群:防守型球員,可以看到第一群打擊選手無論在長打或上壘能力都偏低,好像沒有太顯著的打擊能力特徵,所以我猜測這群選手可能是捕手或是二、游這種以守備見強的選手。
第二群:長打型球員,這類球員有著高長打率、高全壘打率,但上壘能力相對而言並不高,可能是因為具有高三振率的原因,可想而知這群選手應該是揮大棒型的選手。
第三群:均衡型球員,這群選手同時具有高上壘能力與高長打能力,猜測可能是我們耳熟能詳的一些知名球星組成。
下列為實際分群結果,因為資料密集,字體的顯示就顯得很醜XD
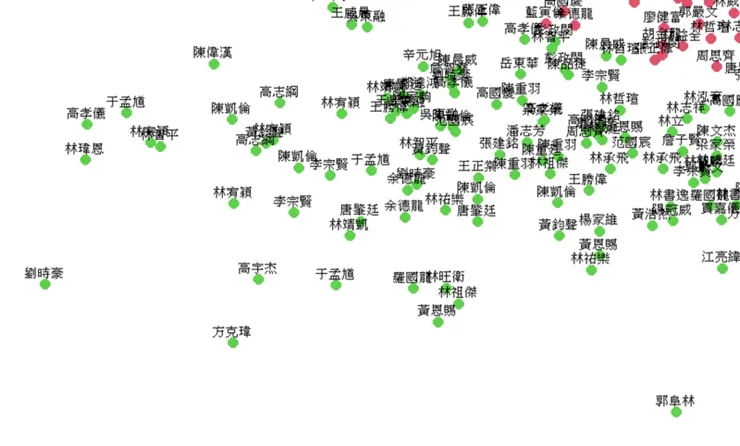

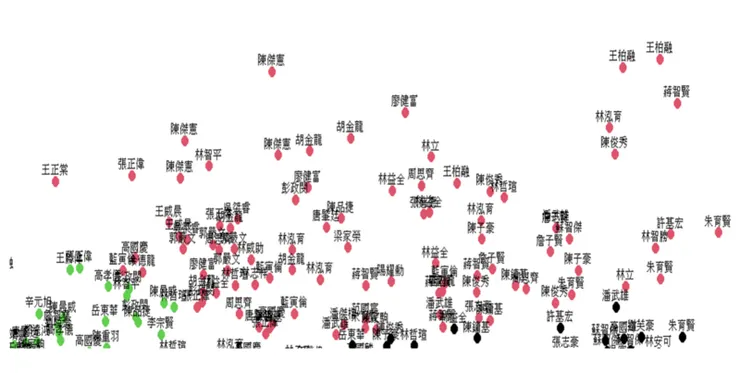
從球員名單中可以發現這個分群結果大概如我所料中的分布,回到一開始和勝率的相關,相關最高者為打擊率、上壘率再來才是長打率,所以我們按照這個順序給予這些選手積分,落在第三群的均衡型選手們可以獲得3分,第二群的長打型選手有2分,第一群的無打擊天賦型只有1分。
最後我們找了2016~2020的總冠軍第一戰來做預測,因為總冠軍第一戰尤其重要,兩隊應該都會派出狀況最好的選手應戰,比較有參考價值,列出兩隊名單後,先填入每個選手該年的積分,最後做全隊平均,哪邊打擊積分高就預測那隊獲勝。
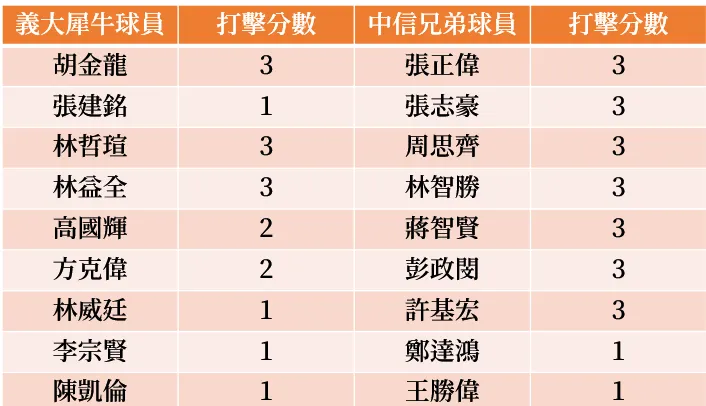
2016犀牛v.s.中信兄弟,兩隊的打擊積分平均是1.88和2.55,所以預測中信兄弟獲勝,雖然看起來打擊積分差很多,但實際上中信只贏了1分XD
用同樣的方式去預測2017~2020,發現這種方式只有在2017年的時候失準,當年兩隊第一戰的平均打擊積分分別為2.33和2.16,代表兩隊的打擊能力相去不遠,不太好進行預測。
也就是說透過此模型預測總冠軍第一場的準確度達80%(當然這樣本數超少,因為要逐年比較跟填入分數太麻煩了XD),如果是預測該年度總冠軍隊伍的話準確度也有80%(只有2016年預測錯誤,該年總冠軍隊伍為義大犀牛)
以上是透過選手打擊能力預測總冠軍勝負的過程,這個方法的研究限制太多了,沒有考慮到守備能力、代打、投手群等等,希望未來可以發展跟投手有關的數值,可以同時參考兩個指標,做出更準確的判斷;而且目前樣本數還太少,在一開始的打擊表現指標選擇上也還需要多做著墨,仍有相當大的改進空間。
喜歡這些內容麻煩幫我按讚,也可分享出去給更多人知道,學海無涯,這些只是一點點小知識,希望大家會喜歡!
























