AI 魔法禁書目錄
這次我要來介紹如何使用 talking-head-anime 創建自己的 vtuber 角色,talking-head-anime 是一個超酷的開源軟體,只要輸入一張圖片,並且搭配手機的鏡頭去偵測臉部動作,他就可以直接把你的表情和動作套用到輸入的圖片上。talking-head-anime 的作者最早在 2019 年就已經釋出第一個版本,目前是到第三個版本。
環境準備
talking-head-anime-3-demo
首先要先安裝 talking-head-anime-3-demo,這個專案是用 python 寫的,有提供 conda 的 environment,所以只要執行下面這行指令就可以安裝。
conda env create -f environment.yml沒有 conda 的話,可以先去 miniconda 官網下載安裝,conda 有分 anaconda 和 miniconda,anaconda 包含了很多預設套件比較肥,所以大家通常都是裝 miniconda。
安裝完成後,要跑之前記得要用 conda activate 切換到對應的 python venv 環境。
conda activate talking-head-anime-3-demoiFacialMocap
接著,為了要偵測我們臉部的表情,所以要安裝一個手機的 App 叫做 iFacialMocap,不過他只有 IOS 的版本,或是也可以下載桌面版(但我沒測試過桌面版)。IOS 的 App 有分免費版和付費版的,免費版的叫做 iFacialMocapTr 會有廣告,付費版的是 iFacialMocap 要價 190 台幣,不是很貴。
Stable Diffusion
再來,我們還需要 Stable Diffusion 來幫我們畫出我們 AITuber 的皮,我習慣是用 AUTO1111 的 Stable-Diffusion-Webui,這裡我就不多作介紹,畢竟不是本篇的主軸。
OBS
最後,我們需要使用到 OBS 來幫助我們串流到 youtube, twitch 或是直接錄影都可以,前往 OBS 官網 下載。
工作流程
Stable Diffusion 畫皮
第一步,我們要先用 stable diffusion 畫出我們 AITuber 的皮,但這個皮也不能隨便畫,官方 repo 有說明,要像下面這樣,把角色擺在適當的位置才能跑出好的效果,並且背景的部分要是透明色(不是白色)。
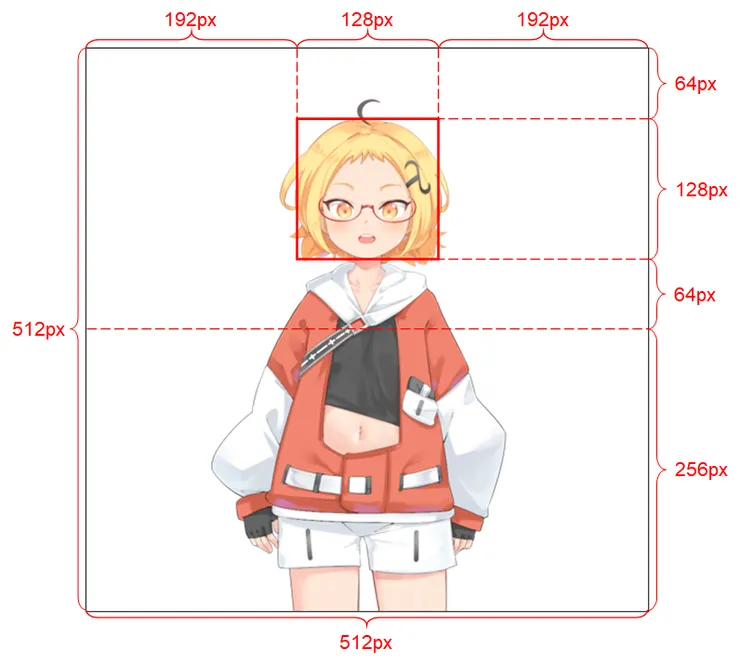
所以這邊我們利用 ControlNet 的 openpose 來把角色固定在官方建議的位置如下,Control Weight 我設定為 0.7,因為我想說不要綁得太死,給他一點發揮的空間,如果位置一直飄掉的話,可以把它調高一點。
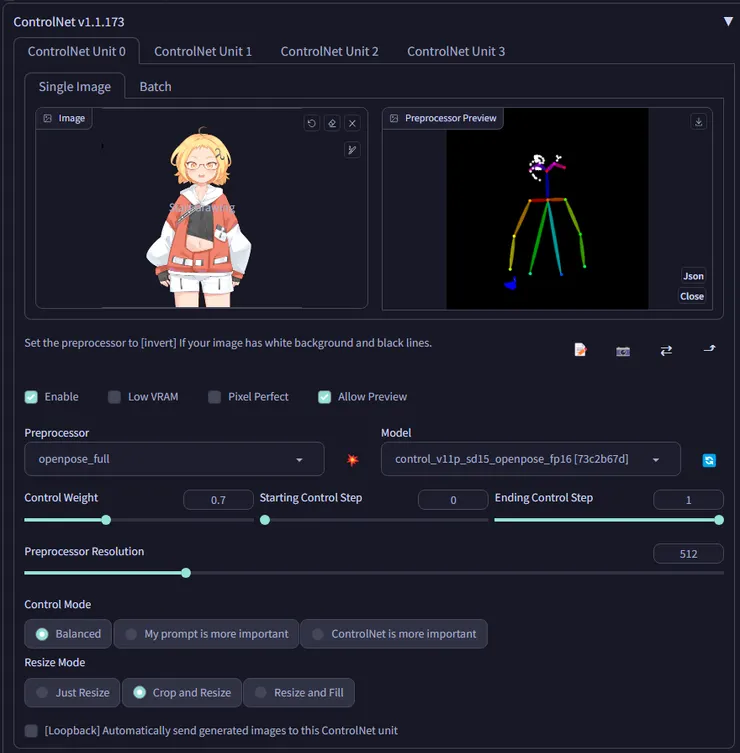
接下來 prompts 的部分,以下供參考。
1girl, solo, masterpiece, best quality, highres,
upper body, (simple background, white background),
(你想畫的角色的描述...)
結果出來之後,我是用 Clip Studio 修圖+去背,最後再把圖片縮小回 512x512 就完成了,我做的 AITuber 皮如下(就是一張圖片)。

串起來
畫好皮之後,我們就可以來把所有東西串起來了,首先打開進到 talking-head-anime-3-demo 的資料夾,切換到正確的 python venv 環境。
conda activate talking-head-anime-3-demo接著執行腳本
python.exe tha3/app/ifacialmocap_puppeteer.py --model standard_half他提供了四個模型可以選擇,有 standard_float(預設), separable_float, standard_half, separable_half 四種,float 是用單精度浮點數(32 bytes)儲存模型,half 是用半精度浮點數(16 bytes)儲存模型,所以 half 的模型大概會比 float 還小一半,如果你的硬體不好就選 half 的模型,但是它的效果可能會稍差一點,一般是不會差太多啦,而 standard 和 separable 的差別作者好像沒有提到,我就不知道了。
跑起來就會像下面這樣。
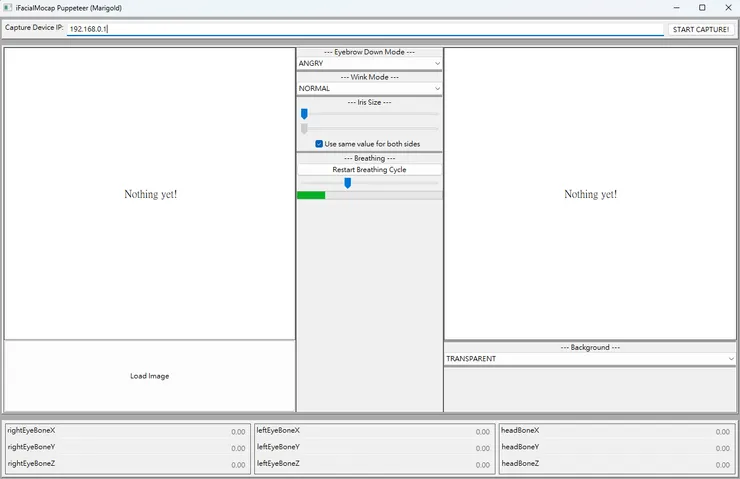
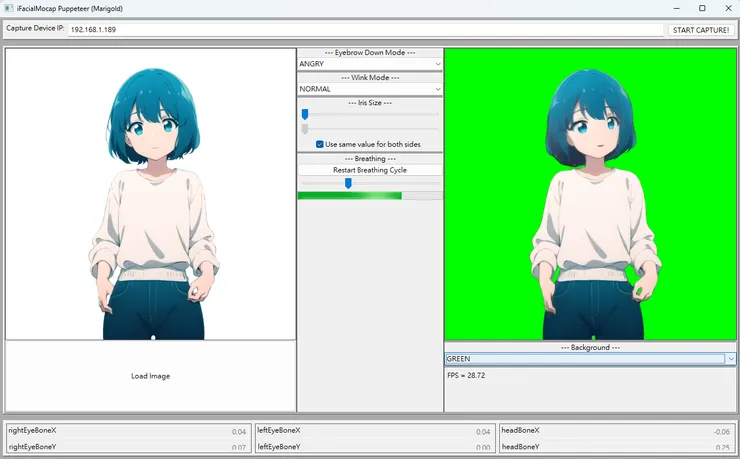
接著,就可以來打開 iFacialMocap 如下

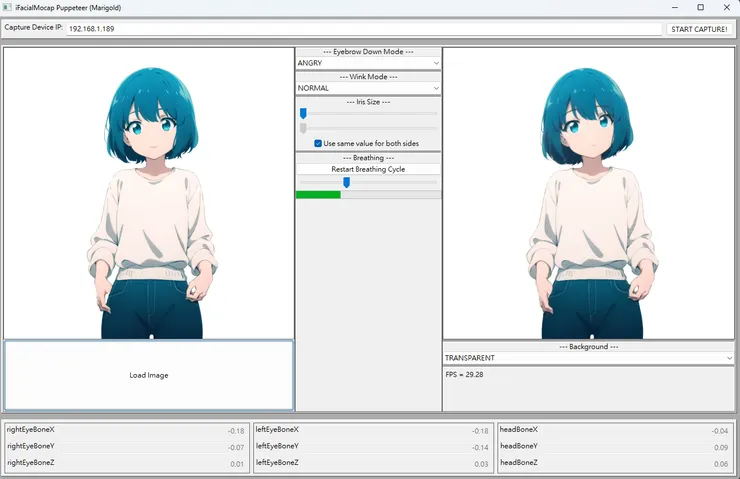
把最上面那行顯示的 ip 位址複製下來或是記起來(這裡沒有顯示的話,也可以去手機的設定查看 ip 位址),寫到 talking-head-anime-3-demo 最上面 Capture Device IP 這裡,然後按下右邊的 START CAPTURE!
最後選擇 Load Image 載入我們剛剛做好的皮就大功告成了!

OBS
OBS 的設定也非常簡單,我們拉一個視窗擷取出來,然後把它裁剪到只剩右邊的人物(按 Alt 拖動邊框)

接著,把背景設成綠色的,就是傳說中的綠幕。
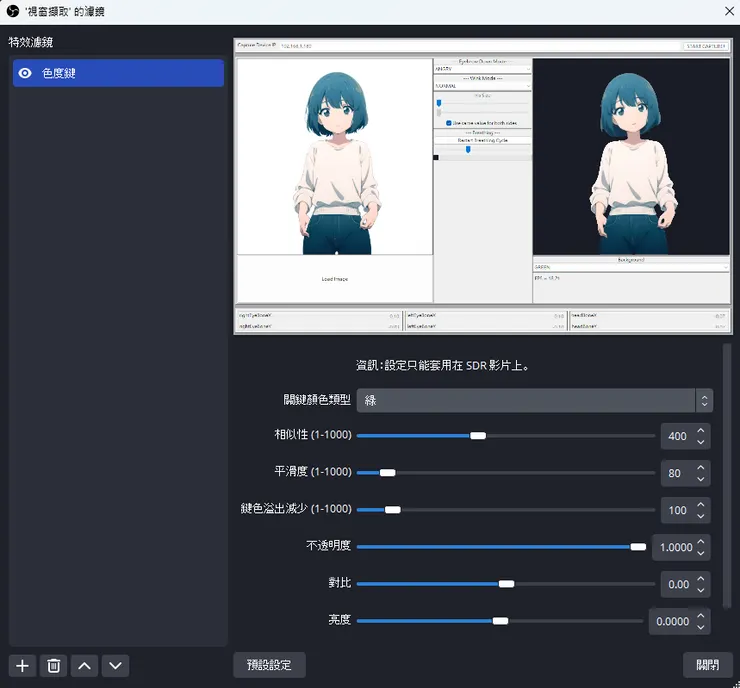
在視窗擷取中點右鍵濾鏡,新增一個色度鍵(Color Key),關鍵顏色類型選綠色。
最後把我們的 AITuber 拉到右下角適當的位置就完成啦。
總結
在這篇文章中,我們介紹了如何利用 talking-head-anime 來讓 stable diffusion 產出的人物動起來,並且可以在 OBS 中進行串流。相比於 Live2D,因為 talking-head-anime 需要實時跑模型去讓人物動起來,硬體需求還是稍微高一點,但優點就是只需要一張圖片即可。不過整體而言,離真正全自動的 AITuber 還是有一段距離,現在只是畫個可以動的皮出來xD
如果這篇文章對你有幫助,不要吝嗇給我一個大大的愛心❤️
歡迎追蹤我的 twitter、pixiv、patreon😆
https://linktr.ee/novelaimagician











.jpg)









