一. 引言
WaveNet 提供了一個先進的架構用於音訊重建,但是,有必要嗎? Mel 頻譜本身就是經過數學轉換而獲得的結果,不能反運算嗎 ? 到底 WaveNet 在其中扮演了甚麼腳色 ?它是如何運作的 ? 讓我們在這篇好好探討下去。
二. Mel 頻譜能反運算嗎
我們知道 Mel 頻譜是音訊波形經短時傅立葉變換(STFT)再進行 Mel 濾波器組而成的,那麼 Mel 頻譜能不能經過反運算計算回波形呢 ?
很不幸的這會是很困難的事,因為雖然短時傅立葉變換的結果保留了頻譜及相位訊息,但是在轉換到 Mel 頻譜時,通常只保留了幅度信息,相位信息在這個過程中丟失。
當只有幅度信息而缺乏相位信息時,直接反向運算會遇到以下挑戰:
- 缺乏相位信息的重建:缺少相位信息意味著我們無法確定每個頻率成分在時間上的精確位置。這會導致生成的波形失真,聽起來不自然。
- 相位估計的困難:雖然可以通過算法(如 Griffin-Lim 算法)來估計相位信息,但這些方法通常無法精確重建原始相位,從而影響波形質量。
例如我們有兩個 5Hz 的正弦波其中一個為 90 度相位 :
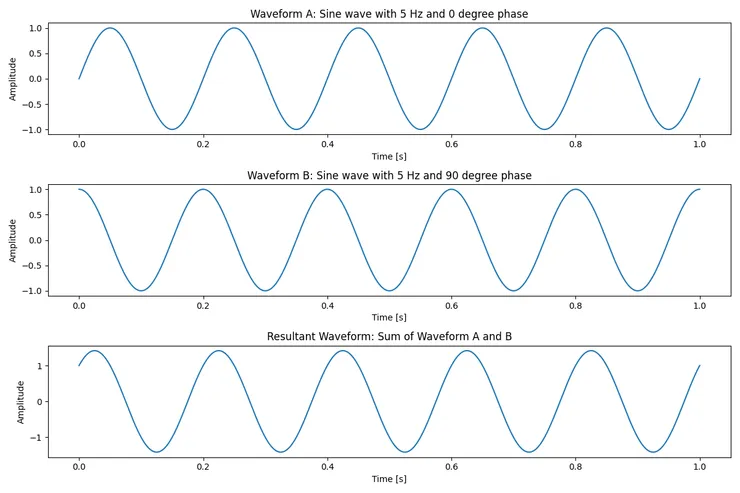
若是忽略相位訊息,以 A 與 B 波形的結合波形進行頻譜分析只會看到在 5Hz 處有能量變化,但無法分析其中包含 B 這個相位變化的內容。
所以對於 Mel 頻譜而言,在沒有相位訊息的的情況下,要直接反運算就會非常困難,於是有了 WaveNet 等深度生成模型通過學習大量數據中的相位模式,可以有效地從 Mel 頻譜中生成高質量的音訊波形,解決了相位信息缺失的問題。
三. WaveNet
WaveNet 是由 DeepMind 提出的生成模型,其基本設計有幾個重點 :
1. Dilated Causal Convolution(擴張因果卷積)
WaveNet 的核心是擴張因果卷積,其包含因果卷積及擴張卷積,它使模型能夠捕捉較長的時間依賴性。擴張卷積的步幅隨著層數的增加而指數增長,這樣在計算複雜度不變的情況下,感受野會迅速增大。
- Causal Convolution : 因果卷積是一種特殊的卷積,確保當前輸出的計算只依賴於當前及之前的輸入,而不依賴於未來的輸入。這對於處理序列數據(如時間序列或語音數據)非常重要,因為這樣可以保證模型的預測不會“看到”未來的信息。

- Dilated Convolution : 擴張卷積通過在卷積核之間引入空洞來擴大感受野

在 Pytorch 框架下,我們可以以下列方法定義 Dilated Causal Convolution :
class DilatedCausalConv1d(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, dilation):
super(DilatedCausalConv1d, self).__init__()
self.kernel_size = kernel_size
self.dilation = dilation
self.padding = (kernel_size - 1) * dilation
self.conv = nn.Conv1d(in_channels, out_channels, kernel_size, dilation=dilation)
def forward(self, x):
# Apply padding on the left side
x = F.pad(x, (self.padding, 0))
x = self.conv(x)
return x
2. Residual Blocks
WaveNet 使用殘差塊(Residual Block)來緩解深層網絡的梯度消失問題。
3. Gated Activation Units
在殘差塊中使用門控激活單元(Gated Activation Unit),其額外訓練一組參數作為門控,來進一步控制參數。
門控激活單元的概念很簡單,這裡展示一個簡單案例 :
class GatedActivationUnits(nn.Module):
def __init__(selfin_channels,out_channels,kernel_size):
super(GatedActivationUnits, self).__init__()
self.conv = nn.Conv1d(in_channels, out_channels, kernel_size, dilation)
self.gate = nn.Conv1d(in_channels, out_channels, kernel_size, dilation)
def forward(self, x):
h = self.conv(x)
g = self.gate(x)
out = torch.tanh(h) * torch.sigmoid(g)
return out
我們除了原本的 conv 外,額外增加一個相同輸出大小的 gate 作為門控,利用 sigmoid 限制門控在 0-1 之間,並與原本通過激活函式的 conv 相乘,進一步控制結果的輸出。
4.條件輸入
WaveNet 中定義了一個額外的條件輸入來輔助,例如可以輸入 Mel 頻譜,嗯 ? 不知道讀到這的人會不會跟我當時有一樣的疑問 ── 原來搞了半天 Mel 頻譜只是輔助輸入嗎 !? 這邊就要稍微提到生成模型的特性,那就是結果是一個一個跑出來的,可以理解成把時間 T 以內的訊息輸入到網路,他會輸出 T+1 的內容,所以主要輸入會是這個時序內容, WaveNet 也一樣,利用同時輸入時序資料與 Mel 頻譜資料,讓 Mel 頻譜資訊協助內容的生成。
四. 訓練資料處理
音訊在進行前處理也有一些細節要處理 :
1.正規化
首先我們需要將音訊根據需求做切割或是填充,然後將其根據自定義的取樣頻率進行取樣,然後正規化到[-1, 1]之間
2.μ-law 編碼
在WaveNet中使用了 μ-law 編碼,其為一種非線性量化技術,用於壓縮音頻信號的動態範圍,使得較小的振幅變化得以更詳細地表示。這有助於提高音頻的整體質量,特別是在語音合成應用中。
其公式如下 :
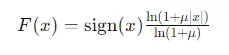
其中:
- x 是歸一化到 [-1, 1] 的原始音頻信號。
- μ 是一個壓縮參數,常設為255。
3.量化
量化是將連續的音頻信號映射到一組離散的值。在WaveNet中,音頻信號通常被量化成256個離散值(8-bit),這樣可以降低數據的複雜度,並使得模型更容易處理。
4. One-hot編碼
為了網路計算,通常會將量化後的整數值轉化成 One-hot 編碼供網路計算
所以一連串運算下來,若是以採樣頻率16000進行採樣,一個2秒的音頻會有32000個採樣點,經過正規化、μ-law 編碼、量化、One-hot編碼後,會編碼成 [32000,256] 的張量,而為了網路能夠計算,我們需要將其顛倒成 [256,32000]。
5. Mel 頻譜
也別忘了我們的條件輸入也是要處理的,Mel 頻譜計算時取量化後音訊結果,將其限制在 [-1,1] 的範圍內,便可以計算 Mel 頻譜,計算時可以指定要計算成幾個頻帶,短時傅立葉的窗口要多大,移動步伐要多大等參數,若設定80個頻帶,結果可能會變 [80,601] ,80 為我們設定的頻帶,601為計算出來的時間步,可以看到跟原本的 32000 的時間步是對不上的,所以我們還需要對其進行內插,將 601 平均擴充至 32000 ,最終獲得 [80,32000] 的張量。
五.訓練流程
WaveNet 的訓練因 WaveNet 在設計上有自回歸的特性,這意味著網路的輸出為下一個時間段的輸入,所以在設計訓練流程時得考慮這一塊
如果按照邏輯,應該設計成這樣
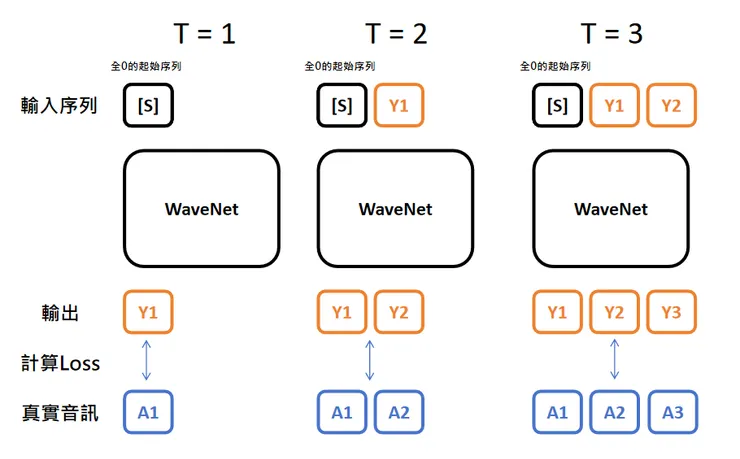
但 WaveNet 採用了一種訓練機制 ── Teacher forcing,其常用於序列到序列模型(如RNN、LSTM 和 GRU)。在訓練過程中,模型預測每個時間步的輸出時,並不是使用模型本身在前一步的預測結果,而是使用真實的標籤資料。這種方法幫助模型更快收斂並且減輕誤差傳播的問題。
也就是會變成這樣

其目前完整結構程式碼我會放在Github上,但目前打算再進行調試,所以內容可能會再做更換。
六.結語
本次的內容真的是愈寫愈多,有些感覺寫得太複雜的想了想還是選擇刪掉,最後刪刪減減還是發出來了,這次的 WaveNet 我認為結構上不算太難,但是要調試出一個能夠收斂到可用的,就非常複雜了,這幾天光是結構,就看到的很多不同的變形,已經分不出來哪個是最接近原版的,多次嘗試後才定下目前的結構,就連訓練循環也看到很多不同版本,最後還是選擇選擇設計較符合論文中描述的訓練方式,這幾天打算再調試看看,可能會花個幾天,那麼,下一篇再見。





















