一.引言
我們前面幾篇已經講完TTS技術的一大半架構了,知道了如何將聲學特徵重建回音訊波形,也從中可以知道要是聲學特徵不完善,最終取得的結果也會不自然,剩下要探討該如何將文字轉換成聲學特徵,且能夠自然地表現停頓及細節變化,讓我們開始吧。
二.架構說明
聲學特徵轉換流程可以簡單總結成三個步驟 :
1. 文本前處理
所有 TTS 模型在生成聲學特徵之前都需要進行文本前處理(我們已在神經網路如何理解文字及Word Embedding中描述了部分處理)。這包括:
- 文本正規化:將文本轉換為標準格式,如展開縮寫、處理標點符號等。
- 文本清理:去除不必要的字符和符號,確保文本純淨。
- 音素轉換:將文本轉換為音素序列,這是生成聲學特徵的基礎,這部分根據語言的不同需要不同的拆解操作。
2. 序列建模
TTS 模型需要對輸入的音素序列進行建模,以捕捉其時間和空間關係。這通常通過以下結構實現:
- RNN/LSTM/GRU:循環神經網絡(RNN)及其變種(如 LSTM、GRU)用於處理序列數據。
- Transformer:基於自注意力機制的 Transformer 可以捕捉長距離依賴。
3. 聲學特徵生成
這是 TTS 的核心步驟,即將音素序列轉換為聲學特徵。常見的聲學特徵包括梅爾頻譜(Mel-spectrogram)和 MFCC。生成聲學特徵的過程通常包括:
- 特徵提取:從音素序列中提取與語音相關的特徵。
- 特徵映射:將提取的特徵映射到頻譜空間,生成可視化的聲學特徵。
三.Tacotron 2 架構分析
我們前篇談到了 WaveNet,正好 Tacotron 2 便是使用 WaveNet 進行後續重建工作,我們可以分析 Tacotron 2 的架構(根據原始論文提供)來呈現前段所述的三步驟 :
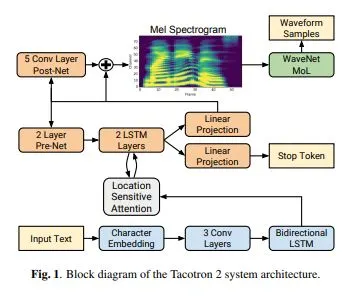
1. 文本前處理
- Input Text:這邊接收已進行前處理文本訊息,論文內並沒有詳細描述前處理過程,只有敘述已完成正規化,可以視為已經過前段所述的各種處理。
2. 序列建模
- Character Embedding:在Tacotron 2 中,選擇在架構中加入詞嵌入層,而不是使用預訓練的 Word2Vec 模型,在現今的架構中,使用這種方式讓模型在訓練中同時訓練詞嵌入的參數,能更符合各種任務。
- 3 Conv Layers :卷積層用於提取局部特徵,這是序列建模中的一部分。
- Bidirectional LSTM :雙向LSTM捕捉序列中的上下文信息,是序列建模的重要組件。
- Location Sensitive Attention :這一部分通過注意力機制在解碼過程中對編碼器輸出進行加權求和,目的是鼓勵模型在輸入序列中一致地向前移動,減少解碼器重複或忽略某些子序列的可能性。
- 2 Layer Pre-Net :進一步處理嵌入向量,助於穩定注意力機制並改善語音合成的準確性和自然度。
- 2 LSTM Layers :這是最關鍵的一層,其主要作用為進行序列建模,接收來自Pre-Net的輸出和注意力上下文向量,生成新的隱藏狀態和輸出特徵。
3. 聲學特徵生成
- Linear Projection :用於預測當前時間步的梅爾頻譜。
- Stop Token:判斷生成過程何時結束。
- 5 Conv Layer Post-Net :對預測的梅爾譜圖進行後處理,該網絡用於預測一個殘差,這個殘差會加到初始的梅爾頻譜預測上,從而提高整體的重建質量,通過這些卷積層,初始的頻譜預測得到進一步的細化和修正,使得生成的語音更加自然和清晰。
- Mel Spectrogram :最終生成的梅爾譜圖表示
經過一連串分析,可以看到基本架構不出三點,但其中每個部份能更夠變化及優化的部分就是各篇論文研究的方向,也是各個模型效果不盡相同的原因。
四.各模型介紹
除了 Tacotron 2 外,還有許多模型被提出,這也是為何本篇沒有提出Tacotron 2 的實作,因為還有好多值得實作練習的模型,現在就讓我們來看看 :
Tacotron 2
- 結構:使用 LSTM(長短期記憶)網絡來捕捉音素序列的時間和空間關係。
- 優點:能夠有效捕捉短距離依賴關係,生成的聲學特徵質量高,適合高質量語音合成
- 缺點:推理速度較慢,難以處理長距離依賴。
DeepVoice 3
- 結構:使用基於位置的注意力機制來建模音素序列。
- 優點:通過注意力機制可以捕捉更長距離的依賴關係,結構簡單,適合快速特徵提取。
- 缺點:相比 Transformer,注意力機制的效率和效果稍遜。
FastSpeech
- 結構:採用完全並行的 Transformer 結構來進行序列建模。
- 優點:顯著提高了推理速度,能夠捕捉長距離依賴,並且更加穩定。
- 缺點:模型訓練需要大量的數據和計算資源。
Transformer TTS
- 結構:基於自注意力機制的 Transformer 網絡。
- 優點:能夠有效捕捉全局上下文信息,適合處理長序列數據。
- 缺點:推理速度較慢,特別是對於實時應用。
VITS
- 結構:使用變分自編碼器(VAE)和流形學習(Flow-based)技術進行序列建模。
- 優點:能夠生成多樣且自然的語音,並能捕捉複雜的時間依賴關係。
- 缺點:模型相對複雜,訓練過程需要大量的計算資源。
共同點
- 文本前處理:所有模型都需要對文本進行預處理,包括正規化和音素轉換。
- 序列建模:無論使用 LSTM、CNN 還是 Transformer,這些模型都需要對音素序列進行建模,以捕捉時間和空間關係。
- 聲學特徵生成:所有模型都需將提取的特徵映射到聲學空間,生成梅爾頻譜或其他聲學特徵。
不同點
- 序列建模方式:LSTM 適合短距離依賴,Transformer 和 VAE 則適合捕捉長距離依賴。
- 特徵提取和映射方式:不同模型使用的技術和結構不同,影響了語音生成的質量和速度。
- 生成速度和穩定性:FastSpeech 和 VITS 通過並行和端到端的方式,顯著提高了生成速度和穩定性,而 Tacotron 2 和 Transformer TTS 在質量上有所提升,但速度較慢。
四.結論
這篇主要分析了聲學特徵轉換的基本流程,並帶出現在常看到的幾種模型,根據應用場景的不同,可以選擇適合的模型。例如,對於實時應用,FastSpeech 是不錯的選擇;對於需要高質量語音合成的應用,VITS 是最佳選擇,並且每個模型都有著不同的亮點,接下來我可能會研究看看 VITS,或是直接前往其他主題。

























