🌟簡介

什麼是盤中逐筆成交資料呢?盤中逐筆成交資料是指在證券交易過程中,每一筆交易的詳細記錄,像是以台灣證交所所提供的盤中逐筆交易資料除了基礎的交易的股票代碼、交易時間、交易價格、交易量等信息。甚至提供像是交易種類代號(普通、鉅額、零股)、投資人屬性( 投信基金、外資、自然人、其他一般法人)。
🐌那盤中資料有什麼樣的魅力?
像是我們在網路上看到的股價資訊為一天的資料,但若是我們用盤中資料來看以台積電為例那是幾十萬次的資料彙整而成的,若是以天看我們可能看到的是:哦~股價漲了,但若是以盤中資料來看可以看到非常精采的衝上衝下,震盪是非常大的!這也使得像是在量化交易中會需要這類型的資料去做使用。不過根據效率市場假說,所有有價值的信息都應即時反映在股價中,但市場操縱的存在可能阻礙這一過程。因此,透過分析歷史價格來獲取超額利潤並不可行。但即使在資本充足的市場如美國,市場效率也未能完全實現,例如:美國市場在普通時期和特殊時期都被證實是弱效率的。進而表明現實中的股市在某種程度上是可以預測的。
🌟研究方法
在此研究中研究人員使用了馬可夫鏈模型(Markov Chain Model)&擴散核模型(Diffusion Kernel Model)來去進行預測。接下來我們來針對這兩種模型以及他們怎麼針對數據來去做處理來介紹吧。
🐌馬可夫鏈模型(Markov Chain Model)
馬可夫性質:未來的狀態只依賴於當前狀態,而不依賴於之前的狀態。這種特性被稱為「馬可夫性質」。
馬可夫鏈模型在經濟學、博弈論、傳播理論、遺傳學和金融學,甚至在語言學這樣看似與數字無關的領域都有廣泛的應用。
馬可夫鏈主要元素:
1.狀態空間:系統可能處於的所有狀態的集合。
2.轉移概率:系統從一個狀態轉移到另一個狀態的概率。這些概率可以用一個矩陣(稱為轉移矩陣)來表示。
3.初始狀態分布:系統在開始時各個狀態的概率。
舉個簡單的例子,像是若是要將馬可夫鏈運用於股票預測中:1.狀態空間:上漲(U)、下跌(D)、不變(S)。狀態空間為 {U, D, S}。
2.轉移概率:我們需要收集股票的歷史價格數據。我們可以根據過去數據,計算出轉移概率矩陣。Ex.一個矩陣表示當前狀態(漲&跌)與未來狀態(漲&跌)
接著假設今天股票價格上漲,我們可以使用上述轉移矩陣來預測明天的價格狀態。使用隨機抽樣或概率計算方法來確定明天的狀態。根據模型的預測,投資者可以決定是買入、賣出還是持有股票。例如,如果模型預測明天股票將繼續上漲,投資者可能會選擇買入或持有。
🐌擴散核模型(Diffusion Kernel Model)
核(Kernel)的性質:透過定義在統計流形上的核,利用黎曼度量(如Fisher信息度量)來衡量數據點之間的相似性。這種方法將數據點嵌入到具有特定幾何結構的空間中,並使用熱方程來模擬數據點之間的’擴散’或資訊流。
而此模型與神經網路(neural network)挺相似的,模型的計算使用到了梯度下降的操作,因此不需要大量的訓練資料。

DK模型的預測性能隨著階數的提高而增加,但計算複雜性和成本也隨之增加。在這項工作中,為了確保3秒間隔數據預測結果的及時性,論文中採用了二階DK模型。
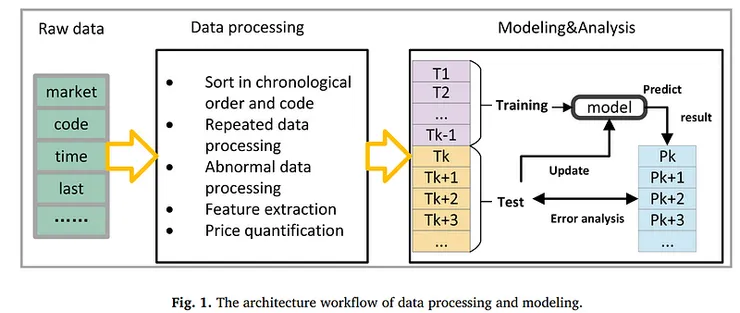
🐌數據&處理方法
資料:上海股市&深圳股市
資料期間:2021.1月以及2022.7月
資料集:2021.1月介紹:總共包含4147只股票,每隻股票的數據都是以三秒鐘的時間粒度收集的。在這些股票中,有1800只來自上海股市,其餘來自深圳股市。數據集A包括18個交易日,每條記錄包括56個特徵,如股票代碼、時間、開盤價、收盤價和最新價等。
來源為每三秒鐘擷取一次股票目前的價格、最高價、最低價、交易量、交易金額及其他市場特徵。兩個股市的日常連續競價時段包括上午兩小時和下午兩小時,這使得擷取數量約為3800個。每天有超過2GB的全市場股票數據。
資料集:2022.7月介紹:挑選了2324只股票,這些股票在深圳股市的代碼與數據集A相同,並為每只股票構建時間序列。由於數據收集平台的差異,驗證數據集的收集頻率不如主數據集頻繁,大約每10秒間隔。這個數據集有21個交易日,包括27個特徵,包括時間、成交額、成交量等。在這個數據集中,選擇成交額作為預測目標。
資料來源:kaggle
預測目標:最新價以及成交額(時間顆粒度為秒)
🔨資料預處理
以量化間隔量化股價,使股價在一定範圍內變為一個狀態。意即取兩個量化值的差。而研究最初設定了兩個量化間隔,分別為0.01 CNY和0.05 CNY。
(1)過濾掉序列長度過短且狀態空間小於10的股票:
因為這些股票存在缺失數據或已經退市,沒有實際的預測意義。其中序列長度是由量化間隔算出。
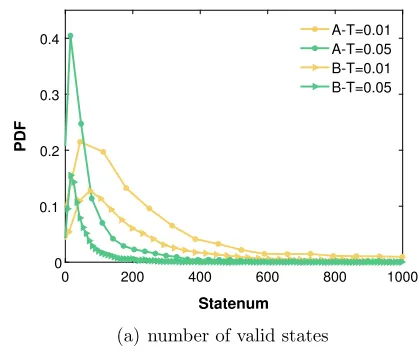
從上圖可以看出當股票被較大間隔量化時,它們的狀態空間較小。儘管X軸範圍從0到1000,實際上,在0.01 CNY的量化間隔中,也有209只股票的狀態超過1000,而在數據集A中的0.05間隔中有58只股票。
在建模時,研究團隊將第一天設為訓練集,其餘天數為測試集。在用訓練集訓練模型後,在測試階段每次預測後更新模型,因此改變訓練集和測試集之間的比例對預測結果沒有影響。
🐌研究成果&發現
(1)中國股票的高可預測性:
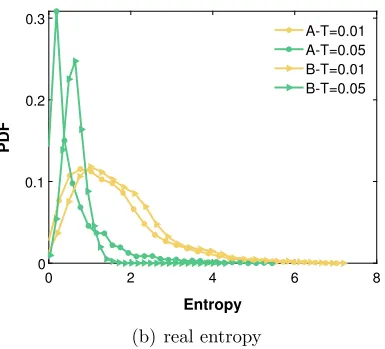
使用Limpel-Ziv數據壓縮方法計算每隻股票的實際熵,在數據集A中,約74%的股票(𝑇 = 0.01)和87%的股票(𝑇 = 0.05)的實際熵小於2,分別表明基於現有的歷史價格序列,大多數股票的未來三秒價格可以在少於22個狀態中找到。這一個觀察顯示交易價格的不確定性很低,因此股票價格可能容易預測。
(2)股票特徵的影響:
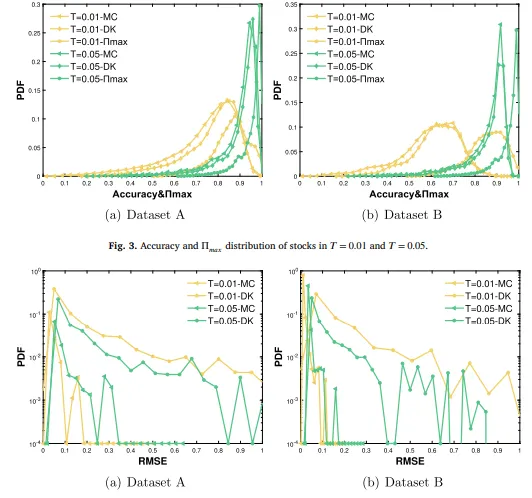
論文中觀察到平均股價和價格波動性與預測準確率之間存在負相關。這表明波動性更大和價格更高的股票更難以準確預測。
(3)模型表現:
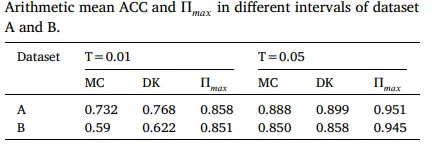
馬可夫鏈模型(MC):傳統的馬可夫鏈模型依賴於狀態的轉移概率,這可能不足以捕捉股價時間序列中的非線性和複雜動態。此外,如果模型只考慮有限的歷史數據(如一階或二階馬可夫鏈),則可能無法充分利用更長範圍內的數據相關性。
擴散核模型(DK):雖然DK模型試圖通過將運動軌跡映射到連續空間的擴散過程來捕捉數據點之間的關聯性,但其預測精度仍受到所選擴散核和量化間隔的限制。更大的量化間隔可能會導致信息的損失,影響模型捕捉股價微妙變化的能力。