AI影像論文(02):ControlCom影像合成模型-論文筆記整理
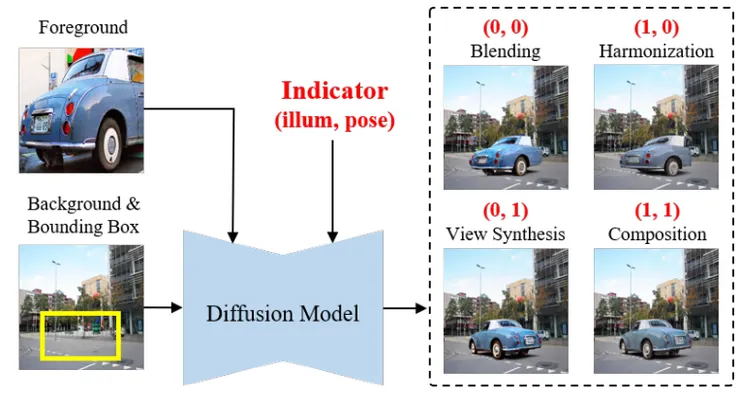
根據「影像合成是如何實現的?」我對於其中的ControlCom非常感興趣,在上篇Survey論文中提到ControlCom為一個object-to-object模型。該模型的特色在於提供整體與局部的圖像融合。
🌟簡介
研究團隊將四項任務整合入一個diffusion模型,這四樣任務分別是Blendingm(混合), Harmonization(調和), View Synthesis(視角合成), Composition(組合),以下針對這四種技術去做一個基本的介紹:🎈Blendingm(混合):主要用於將兩個或多個影像部分結合成一個無縫且協調的整體。而混合的關鍵是要確保在交界處的顏色和亮度能夠平滑過渡,從而達到自然的視覺效果。
🎈Harmonization (調和):調和技術用於調整一個或多個影像元素的風格、顏色、照明等,以使其更好地融入背景中。
🎈View Synthesis (視角合成):視角合成是指從已有的影像中創建新視角的影像的技術。通過分析多個視角的影像,可以合成新的視點影像,提供更多的視角覆蓋。
🎈Composition (組合):組合技術涉及將多個圖像元素或層合成為一個統一的圖像。合不僅涉及物理位置的安排,也包括光線、陰影和視覺效果的匹配,以創建出引人入勝的最終產品。
而此模型的目標在於通過選擇前景的元素屬性(ex.照明&姿勢)來實現圖像生成。而此模型採用自監督學習框架能夠同時在上方任務中進行訓練,從而提高生成圖像的品質和控制度。
🌟之前做法&相關研究
過去的方法大多是將圖像合成分解為多個任務,如圖像融合、圖像和諧化和視角合成,每個任務都旨在解決一個特定問題,但這些方法往往是繁瑣且不切實際的,因為需要依次應用多個模型。
近期的生成式圖像合成方法嘗試通過統一模型解決所有問題,這樣可以大大簡化合成流程。這些方法通常建立在預訓練的diffusion模型上,由於其在合成逼真圖像方面的出色能力,但它們仍面臨缺乏控制性和前景真實性低的問題。在控制性方面,diffusion模型通常以一種不可控的方式調整前景的所有屬性(例如照明和姿態)。而在真實性方面,雖然生成的前景與輸入前景屬於相同的語義類別,但一些外觀和紋理細節的顯著變化,並未滿足圖像合成的要求。
🌟方法
此模型的優勢在於提出了一種可控的圖像合成方法,通過條件擴散模型進行命名為 ControlCom,可以選擇性地調整部分前景屬性(即照明、姿態)。特別地,引入了一個二維指示向量來指示是否應更改前景的照明或姿態,並將該指示向量作為條件信息注入到擴散模型中。
🔍問題定義
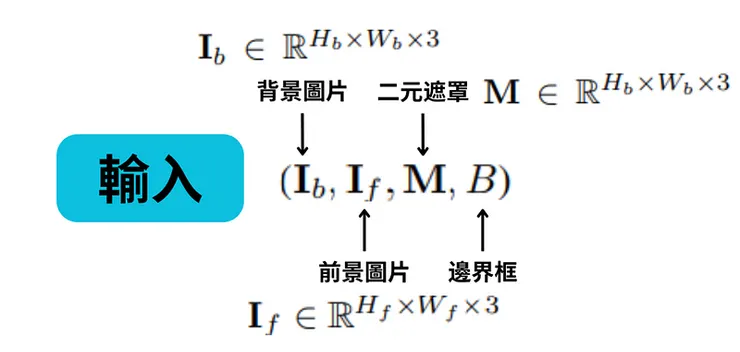
從上方的圖可以看到,此模型有四個輸入分別是背景圖片&二元遮罩&前景圖片&邊界框,其中的H&W為圖像的長跟寬。
另外上方提到ControlCom的優勢在於可以選擇性地調整部分前景屬性(即照明、姿態),因此我們需要引入一個向量來表示是否應該改變照明與姿態,在此向量中第一維度控制照明,第二維度控制姿態,其中值0(分別為1)表示維持(分別為改變)前景的相應屬性。有了這個指示器,我們可以選擇性地調整前景的照明和姿態,從而實現可控的圖像合成。

🔨模型架構
此模型利用Stable-diffusion模型為基礎去建立可控生成器。首先下方是此模型之架構圖,接下來會分別下去解釋。
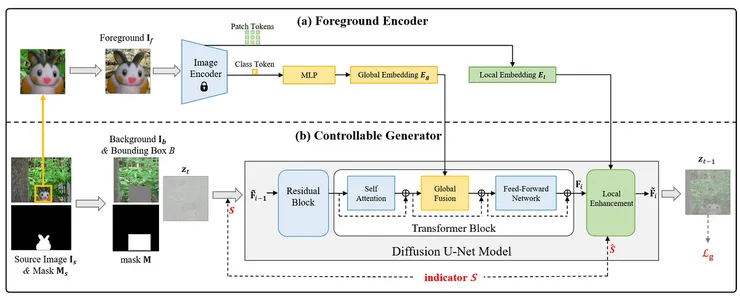
(a)前景編碼器

✅特徵提取
在前景編碼器中,研究團隊使用CLIP的ViT-L/14 image encoder來為圖片擷取特徵(224*224*3),而output資料為s 257 tokens以及1024 dimensions,其中包括 1 個類別 token 和 256 個補丁 tokens。類別 token 負責攜帶高層次的語義信息,而補丁 tokens 則包含局部細節。
✅全局嵌入
利用由 CLIP 編碼器最深層(第 25 層)產生的類別 token,通過多層感知器(MLP)生成全局嵌入 Eg(維度為 768),用於表示整體語義結構。
Global embedding(全局嵌入):將整個圖像或圖像的主要部分轉換成一個緊湊的數字表示形式,通常稱為特徵向量。這種嵌入捕捉了圖像的全局性質,例如整體結構、主要物體的類別、或者整體風格等高層次的語義信息。
✅局部嵌入
為了增豐富前景的細節信息,從較淺的層次(第 12 層)提取補丁 tokens 作為局部嵌入 El(維度為 256×1024)。這有助於捕捉前景的細節特徵,如外觀和紋理。
✅嵌入整合
將全局嵌入和局部嵌入整合進擴散模型的中間特徵中,生成具有豐富信息的表徵,從而使前景合成更加忠實和細緻。
(b)可控生成器
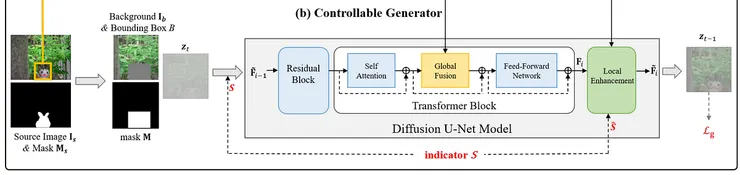
首先再輸入的部分,為了使得能更輕鬆地適應任務,在模型中添加了背景圖像以及二進位遮罩以便於重建背景,另外前面提到了調整部分前景屬性(即照明、姿態)向量會在接下來提到的Unet輸入以及居部增強模組中使用。
接下來生成的部分分為兩階段:全局&局部
✅全局融合
通過全局融合模組融合全局嵌入先產生一個與背景場景一致的粗糙前景促體。
利用 U-Net 的交叉注意力。為了應對圖像合成,我們用前景的全局嵌入 Eg 替換文字嵌入,這會通過交叉注意力注入到 U-Net 的每個變換器塊中的中間表徵。
✅局部增強
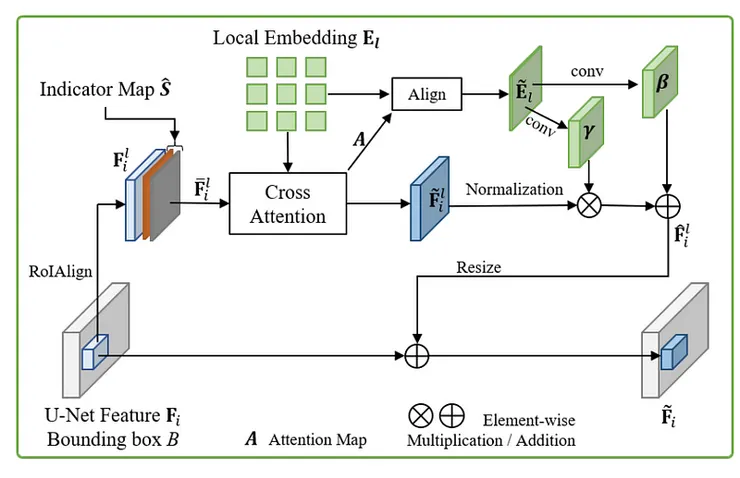
為了合成合成圖像中的前景物體,通過局部增強模組融合局部嵌入提供的外觀和紋理細節,促進高保真合成圖像的生成。通過融合局部嵌入 El,局部背景特徵 Fl̄i 能夠將 El 中的細微前景信息納入,生成與輸入更相似的前景物體。交叉注意力後,我們獲得注意力圖 A和合成的前景特徵圖 F̃li 。
接著為了進一步的去使用從局部嵌入 El 構建的對齊的前景嵌入圖來調節合成的前景特徵圖 F̃li。
注意力圖A成功捕捉了輸入前景與合成前景之間的空間對應。通過將A與前景特徵圖El相乘,並將這個結果轉換成2D空間結構,可以得到了一張對齊的前景嵌入圖Ẽl。在這張圖中,每個像素位置都包含了相應的上下文信息,這有助於進一步處理前景特徵F̃li。為了精確調節這些前景特徵,接著在Ẽl上進行卷積操作,產生空間感知的縮放和移位調節係數(由convγ和convβ卷積層產生)。這些調節係數用於標準化的前景特徵F̃li,產生調整後的輸出特徵F̂li,其形狀與輸入特徵F̃li相同。
最後,為了與全局背景特徵Fi融合,接著調整F̂li的尺寸,並將其添加到Fi中的特定區域,從而產生增強特徵F̃i。這些增強特徵包含了前景的外觀和紋理細節,進一步提高了合成圖像的真實感和質量。
🔨數據準備&自監督學習框架
由於缺乏可以同時訓練四項任務的數據集,這篇論文提出了一個自監督學習框架,並結合了合成數據準備流程來學習這四個任務。
主要是從大規模數據集中收集合成訓練數據(Open Images)。首先過濾數據集,保留具有適當邊界框大小的物體(例如,框區域約為整個圖像面積的 2% 至 80%)。接著使用 SAM (Segment Anything)為沒有遮罩的物體預測實例遮罩。之後,給定原始圖像 Is 和圖像中的邊界框 Bs,並裁剪包含物體的邊界框作為前景圖像,接著遮蔽邊界框區域來創建背景圖像。
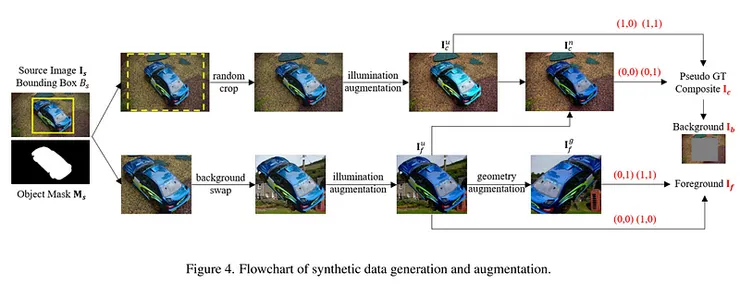
使用隨機裁剪和照明增強來生成合成圖像的變體,稱為 Iuc。

接著對於從同一來源圖像裁剪的前景圖像,首先進行背景替換,以將前景的非前景區域替換為其他背景,這可以防止模型學習到簡單的複製和粘貼。

然後我們依次對前景進行照明增強和幾何增強,分別生成 Iuf 和 Igf。這一過程干擾了前景的照明和姿態,模擬了前景與背景照明/姿態不一致的實際場景。最後,我們將 Iuc 中的前景物體替換為 Iuf 中的物體,得到 Inc。

🔨結果與結論

可以看到模型的表現相較於其他模型皆有更自然的表現。另外下方是一些比較數據。
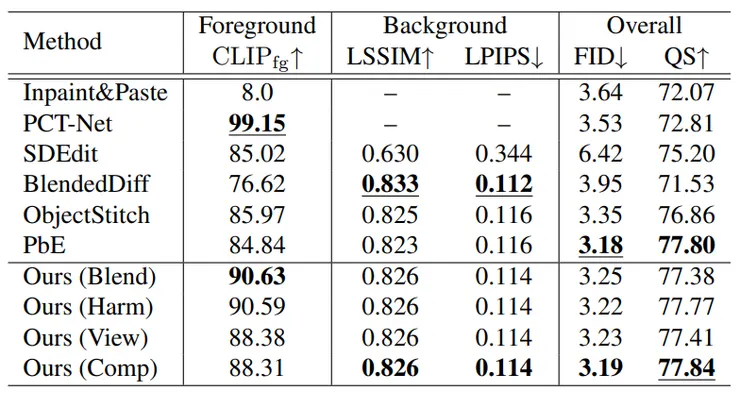
而我認為此模型最大的價值會在於它的可操控性,以往AI生圖最令人詬病的問題就是生成出來的結果與使用者心中的想法不同,而此模型提供的操控性我認為能夠很好的解決這類型的問題。
























