本篇是自學筆記,若有錯誤拜託要跟我說!
索引其實是一種資料結構(Data structure),但我們摸不到。索引類似於書的目錄,是用來加速資料庫查詢的結構。索引會建立指標(Pointer)指向資料所在的物理位置,避免逐行掃描整個資料表(Full Table Scan ),提高查詢效率。索引的基本原理:
- 索引條目包含了 Key 和 指標(Pointer)。
- 指標指向資料所在的 Block。
- 索引和資料(Data File)通常分別存放,資料庫系統會根據索引快速找到對應的資料。
索引類型
Primary Index(主索引)
- 定義:用 Primary Key 建立的索引,Primary Key 保證唯一性,索引條目和資料行一對一對應。
- 特點:Primary Index 和資料是物理排序一致的。每個資料表只能有一個 Primary Index。
- 比喻:書的主要目錄,對應每一頁的具體位置。如下圖每個 Pointer 會指向區塊,當我想到 1002 就進入 1001 跟 1005 中間搜尋即可。
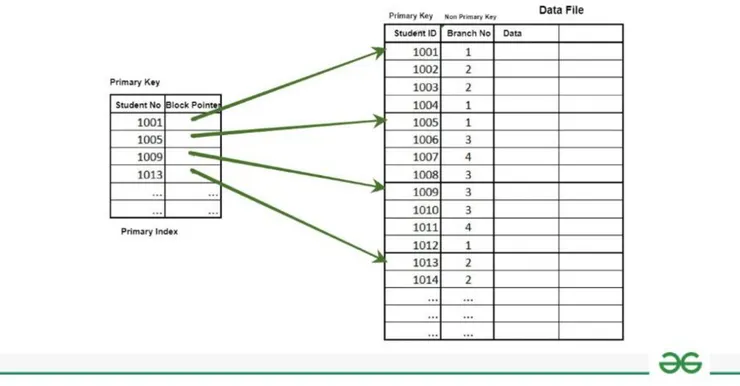
資料來源:Primary Indexing in Databases
Primary Index 的兩個類型
- Dense Index(密集索引)
- 定義:為資料表中每一筆資料都建立索引條目。
- 特點:索引條目完整覆蓋整個資料表。適合小型資料表,但隨資料量增長索引也會膨脹。
- 比喻:書中每一章、每一節都列入目錄。
- Sparse Index(稀疏索引)
- 定義:只為部分資料建立索引條目,通常是分區點(例如每隔幾頁建立一條)。
- 特點:減少索引條目數量,適合排序好的大資料表。
- 比喻:書中只為重要章節(如第 1、5、10 章)建立目錄。
Secondary Index
用來補充 Primary Index 的不足。
- 定義:為非 Primary Key 的欄位(如 Foreign Key、 頻繁查詢的欄位)建立的索引。
- 特點:Secondary Index 不改變資料的物理排序。刪除不影響
- 比喻:類似一本書的副目錄,可以按照不同分類快速定位內容。像是單字書可以用 A-Z 建索引,也有副目錄以大考出現頻率或是主題建索引。
索引結構:B-Tree 有索引就可以用二元搜尋的方式查找
索引通常以 B-Tree 或 B+Tree 資料結構運作:
Clustered Index v.s. Non-clustered Index
- Clustered Index(叢索引)
- 定義:資料表的資料會根據索引的 Key 順序排列,索引條目和資料是一體的。
- 特點:每個資料表只能有一個 Clustered Index。適合範圍查詢,但插入/刪除效率較低。
- 比喻:書的目錄和內容緊密排列在一起。索引照1~10排,實體的資料也是1~10。
- Non-clustered Index(非叢索引)
- 定義:索引條目和資料分離,索引只包含指向資料的指標。
- 特點:一個表可以有多個 Non-clustered Index。適合隨機查詢,但範圍查詢效率較低。
- 比喻:書的目錄和內容分開,目錄指向書櫃中的具體書籍位置。例如:「主題:人工智慧,對應到第 50 頁」。你需要找到索引知道頁碼,然後去翻到書的第 50 頁找到內容。
- 適合精確的搜尋,例如找到特定的名字
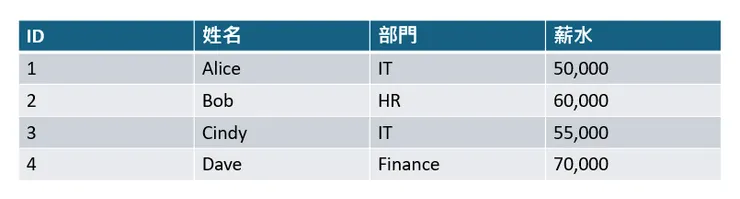
如果 ID 是 Clustered Index:
- 資料在硬碟上的存放順序會按照 ID 排列,例如:
- 第一筆資料存放 Alice(ID=1)。
- 第二筆資料存放 Bob(ID=2)。
- 物理存放順序就是 1 → 2 → 3 → 4。
如果建立一個按「部門」的 Non-clustered Index:
- 索引會是這樣的結構:
- IT → 指向 Alice 和 Cindy 的位置。
- HR → 指向 Bob 的位置。
- Finance → 指向 Dave 的位置。
- 但資料實際的存放順序並不改變,依然是按 ID 排列 1 → 2 → 3 → 4。
總結
- 索引提高查詢效率,但可能帶來維護成本(如插入、更新資料時需要同步更新索引)。
- 索引設計要點:
- Primary Index 用於關鍵性查詢。
- Secondary Index 提供額外的靈活性。
- 根據需求選擇 Dense 或 Sparse Index。
- Clustered 索引適合範圍查詢,Non-clustered 索引適合多條件查詢。























