目標
✅ 建立 FastAPI API,讓應用可以透過 REST API 進行 LLM 查詢
✅ 結合 RAG 技術,提高 LLM 回應的準確度✅ 存入及查詢 FAISS 向量資料庫,讓 LLM 檢索外部知識庫
何謂RAG
RAG(Retrieval-Augmented Generation)是一種結合檢索(Retrieval)與生成(Generation)的技術,主要應用於提升大型語言模型(LLM)的回答準確性。它的核心原理是先從外部知識庫檢索相關資訊,再將檢索結果與預先訓練的模型結合,生成更具參考價值的回答。
RAG 的應用場景
- 問答系統:透過檢索技術獲取準確的背景資料,使回答更具可靠性。
- 企業內部知識庫:整合企業內部文件,使員工能直接向 AI 查詢相關資訊。
- 法律、醫療等專業領域:確保生成的內容基於專業文獻,提高可信度。
📁 專案結構
llm_rag_api/
├── app/
│ ├── main.py
│ ├── rag.py
│ ├── vectorstore.py
│ └── schemas.py
├── data/
│ └── docs.txt
├── requirements.txt
└── README.md
🔧 1. 安裝套件與環境需求 requirements.txt
fastapi
uvicorn
openai
faiss-cpu
tqdm
python-dotenv
pydantic
🧠 2. 向量庫建構 vectorstore.py
import faiss
import numpy as np
from typing import List
from openai import OpenAI
from dotenv import load_dotenv
import os
load_dotenv()
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
class VectorStore:
def __init__(self, dim=1536):
self.index = faiss.IndexFlatL2(dim)
self.documents = []
def embed_text(self, texts: List[str]) -> np.ndarray:
response = client.embeddings.create(
input=texts,
model="text-embedding-3-small"
)
return np.array([r.embedding for r in response.data])
def add_documents(self, texts: List[str]):
embeddings = self.embed_text(texts)
self.index.add(embeddings)
self.documents.extend(texts)
def query(self, text: str, top_k=3) -> List[str]:
embedding = self.embed_text([text])
D, I = self.index.search(embedding, top_k)
return [self.documents[i] for i in I[0]]
🔍 3. RAG 主流程 rag.py
from .vectorstore import VectorStore
from openai import OpenAI
import os
from dotenv import load_dotenv
load_dotenv()
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
store = VectorStore()
# 初始化資料
def load_documents():
with open("data/docs.txt", "r", encoding="utf-8") as f:
texts = [line.strip() for line in f if line.strip()]
store.add_documents(texts)
#生成答案
def generate_answer(question: str) -> str:
relevant_docs = store.query(question)
prompt = "根據以下資料回答問題:\n\n"
prompt += "\n".join(relevant_docs)
prompt += f"\n\n問題:{question}\n回答:"
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": prompt}]
)
return response.choices[0].message.content
🌐 4. FastAPI API 實作 main.py
from fastapi import FastAPI
from contextlib import asynccontextmanager
from .rag import load_documents, generate_answer
from .schemas import QuestionRequest, AnswerResponse
@asynccontextmanager
async def lifespan(app: FastAPI):
# 啟動階段:載入向量資料庫
load_documents()
yield
# 關閉階段(如有需要可釋放資源)
app = FastAPI(lifespan=lifespan)
@app.post("/ask", response_model=AnswerResponse)
def ask_question(payload: QuestionRequest):
answer = generate_answer(payload.question)
return {"answer": answer}
📦 5. 輸入/輸出格式定義 schemas.py
from pydantic import BaseModel
class QuestionRequest(BaseModel):
question: str
class AnswerResponse(BaseModel):
answer: str
📄 6. 測試資料 data/docs.txt
OpenAI 是一家專注於人工智慧研究的公司。
FAISS 是 Facebook AI 提出的向量相似度搜尋工具。
FastAPI 是一個高效能的 Python Web 框架,適合建構 AI 應用程式。
📘 7. README.md 範例
# LLM RAG API with FastAPI
本專案展示如何使用 FastAPI 建立結合 RAG(檢索增強生成)的 LLM API,並整合 FAISS 向量資料庫。
## Features
- 支援 `/ask` 問答 API
- FAISS 快速檢索最相關段落
- OpenAI GPT-3.5 回答查詢問題
- FastAPI Swagger UI 介面
## 快速開始
1. 建立虛擬環境
```powershell
python -m venv venv
2. 啟動虛擬環境:
```powershell
.\venv\Scripts\Activate.ps1
3. 安裝依賴
```powershell
pip install -r requirements.txt
4.設定 OpenAI 金鑰
建立 .env 檔案:
```powershell
OPENAI_API_KEY=your_key_here
5.執行 API
```powershell
uvicorn app.main:app --reload
🚀 執行指令
uvicorn app.main:app --reload
打開瀏覽器進入 http://127.0.0.1:8000/docs Swagger UI測試 API。
FastAPI自帶Swagger UI,Swagger是一個API的可視化介面,可能直接在網頁上查看和測試API,是一個很方便的工具,而FastAPI本身就內建了,只需要在網址的後面加上"/docs"就能進入Swagger UI介面了。
📄 8. 測試
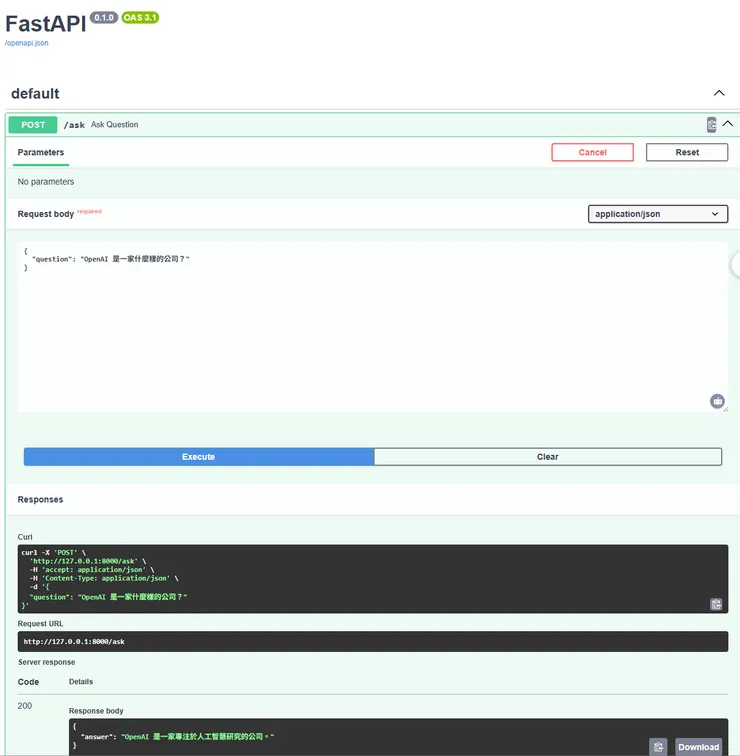
使用FastAPI自帶Swagger UI來測試,輸入"OpenAI 是一家什麼樣的公司?",回傳200 "answer:"OpenAI 是一家專注於人工智慧研究的公司。"
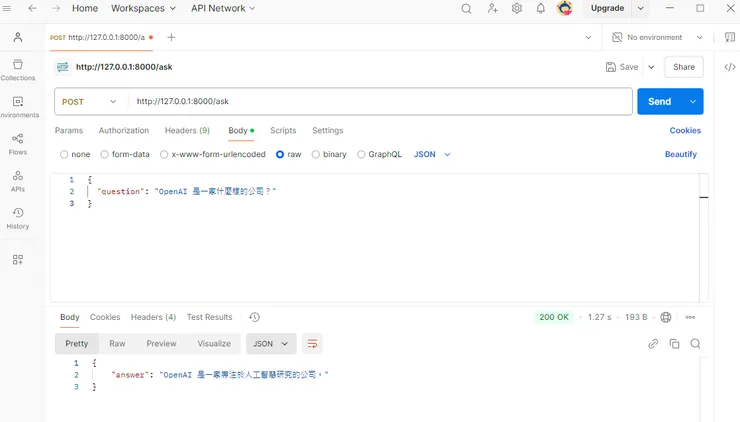
使用Postman,URL輸入"http://127.0.0.1:8000/ask",選擇POST,Body輸入"question": "OpenAI 是一家什麼樣的公司?",一樣回傳了"answer": "OpenAI 是一家專注於人工智慧研究的公司。"。
此篇學習了使用RAG技術來建立一個簡單的API,RAG可以是向量資料庫,也可以是從外部引用的word、PDF、文字檔,可以讓AI回答更為精準,目前是使用了外部文字檔,API使用了python常用的FastAPI,我覺得FastAPI很好,因為本身結合了swagger是個蠻好用的,這個RAG和FastAPI確實都可以再更深入的學習,等之後的篇幅再繼續研究。



















