
ControlNet裡,目前針對邊緣檢測進行線條約束的類型分別有Cannny、Lineart、SoftEdge、Scribble以及MLSD。
為了只專注在了解ControlNet不同約束類型的功能/差異,這裡案例的測試都是在文生圖介面下。先不去另考慮如果是在圖生圖介面下,會多了一個不同Denoising重繪幅度的交錯搭配所產生的其它多元效果/影響。單只利用prompt提示詞+ControlNet約束,如何去控制圖像生成的結果。
Canny
Canny 預處理器
Canny的預處理器有2個:
1. Canny : 將圖片內容的輪廓轉成黑底白線的線稿圖(預處理圖)。
使用Canny預處理器檢測邊緣將圖片輪廓轉成線稿時,可利用高、低閾值(Threshold)來調整線稿圖最終輪廓細節保留多寡。

高、低閾值在1~255間,數值設定的差異如下圖所示,基本上閾值數值愈高,就會過濾掉愈多的細節線條。

2. Invert(from white bg & black line) : 如果是自行上傳一般白底黑線的線稿圖,則需用Invert來反轉黑白顏色。
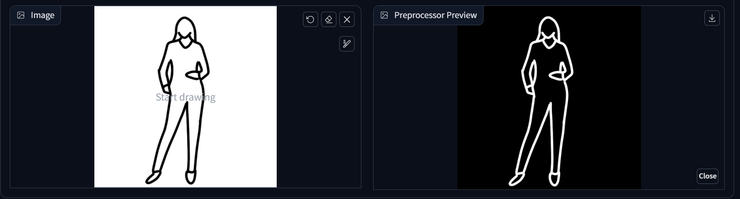
Canny 實作案例
下圖我想讓女孩保留整體在畫面中的構圖比例/人物外輪廓,並且臉型五官維持在同樣位置,但是改變一下髮色及帽子種類。只在Prompt裡寫上我要新更換元素: black hair和straw hat。(這裡沒指定背景,SD還自行腦補了草帽就要搭配海邊的背景~)

如果我想要整張臉都不要受原圖的影響,讓SD自由發揮五官長相以及帽子上不要再出現緞帶。
於是我把Canny的線稿下載下來進到Photoshop自行加工一下,把面部以及帽子上面有顯示緞帶的線條清除(塗黑)。之後再將圖載入視窗(這時預處理器選擇none就可以了)。
人物整體最外圍輪廓限制住不變,但五官長相完全換了個人。

PS. 很多時後,如果提供的線稿圖SD大致能猜出是什麼照片內容時,即使Prompt處全空白,它也能自行腦補畫出正常合理的圖出來。如上面這張圖,Prompt處我就沒填上任何文字描述。
Lineart
Lineart 預處理器 & 實例_寫實照片
Lineart目前預設有的預處理器共有6個(lineart_animeL、lineart_anime_denoise、lineart_coarse、lineart_realistic、lineart_standard以及和Canny一樣也有一個轉黑白稿的Invert)。
每個預處理器對輪廓線特徵提取的效果,以及在此約束下所生成圖片的效果如下所示 :
(PS. 原圖與ControlNet約束下生成圖片所使用的Checkpoint為同一個真人寫實模型,提示詞皆為空白,以及其它所有的參數設定也都一樣。)

雖然有些預處理器名稱裡有”anime”,但也不見得真實照片類的就不適合拿它來做特徵的提取。就看你想要的呈現效果不同去選擇,並沒有說用哪個就一定最好。
單以上面這張圖的例子在不同預處理器的測試下 :
- 與Canny相比,使用Lineart提取出來的線條相對更柔和(線條邊緣),最後的成像效果都將原圖往更”沙龍照(矇矓)”風格偏,特別是使用名字帶有”anime”字樣的預處理器後的成像更明顯。
- 對應原圖想要對所有物件有更相似的”立體度”約束,lineart_standard做得最好(ex.注意圖片右上角帽子的凹陷程度)
Lineart 預處理器 & 實例_卡通圖片
這邊再拿一張我之前圖庫裡的向量素材圖來測試看看,如果我想要把它轉換成寫實照片風格的話:
(prompt : pink peggy bank, golden coins)

最終產出的圖像還無法直接使用。也許自己在Illustrator裡把這張向量素材轉成線稿去蕪存菁保留比較清楚明確/重點的線條、或是換個checkpoint模型多刷幾次圖、也或許再把圖丟到圖生圖的inpaint裡針局部不合理處進行局部重繪…..。
然後背景留白處上下左右延伸調整排版一下方便使用者放上文字文案,就又獲得一張可以上傳圖庫,適合拿來做文宣banner使用的照片素材圖了(keywords概念就是財富、儲蓄、理財….)~
SoftEdge
功能與約束效果方式都和Canny與Lineart一樣,SoftEdge這裡就不重複一樣的生成圖片對比,只列出每個預處理器所提取的效果給大家參考:

Scribble
Scribble 預處理器

Scribble 實作案例
scribble_hed與scribble_pidinet預處理器提取出來的線條極其極簡抽像,但加上搭配Scribble的模型後,SD就是能夠天馬行空的自行腦補出合理的圖像來:

但如果我把這2張scribble預處理圖搭配其它也是線條約束的模型去讀取使用的話會發生什麼事?
(視窗載入scribble的預處理圖,Canny、Lineart、SoftEdge模式下的預處理器都選none)


線條這麼簡約的預處理圖也就只有Scribble自己的模型能handle,畫出正常的圖片來。
那麼反過來,把Canny、Lineart、SofeEdge所提取出相對scribble明確精細(至少人眼看得懂)的預處理圖讓Scribble的模型來讀取使用的話:

結果來看,Scribble模型對線條的腦補能力(包容性)最強大,如果今天我自己畫一張極度手殘簡約的線稿圖,搭配Scribble的模型下,SD一定也能自行腦補畫出像樣的成果來吧~
那就Photoshop + 滑鼠來畫張極簡線稿來試試這幾個ControlNet模型會如何讀取特徵讓SD生成圖像:
(PS. prmopt空白)

結果一目了然,Scribble最能腦補,而且腦補得準確。Canny的口罩不見了,Lineart和SoftEdge都是不自然的死平面。
MLSD
MLSD專門/只能用來提取畫面中”直線”的線條,特別適合用在室內設計與建物外觀線條輪廓的提取。預處理器參數中可透過Value Threshold以及Distance Threshold的數值來調整畫面中線條訊息的多寡。
- Value Threshold : 數值在0.01~2之間,值愈大,檢測到的線條愈少,丟失掉愈多的直線細節訊息。
- Distance Threshold : 數值在0.01~20之間,值愈大,物體越遠處被提取的線條越少,更專注於近處的線條訊息。



利用MLSD提取原圖室內牆面、天花板、桌椅傢俱等具備直線特徵的線條固定住室內透視、傢具配置位置/外觀輪廓大小,之後在prompt提示詞裡寫上想要改變的風格,morden style、industrial style、white wall….等。
























