
這篇文章是繼上一篇文章之後,我們繼續講解神經網路的基本架構。我們先複習一下,上篇文章我們解說到了神經網路的基本架構包含了輸入層,輸出層,還有中間的隱藏層,也說明了這是一個把輸入資料拆解出特徵然後依照特徵做判斷的過程。
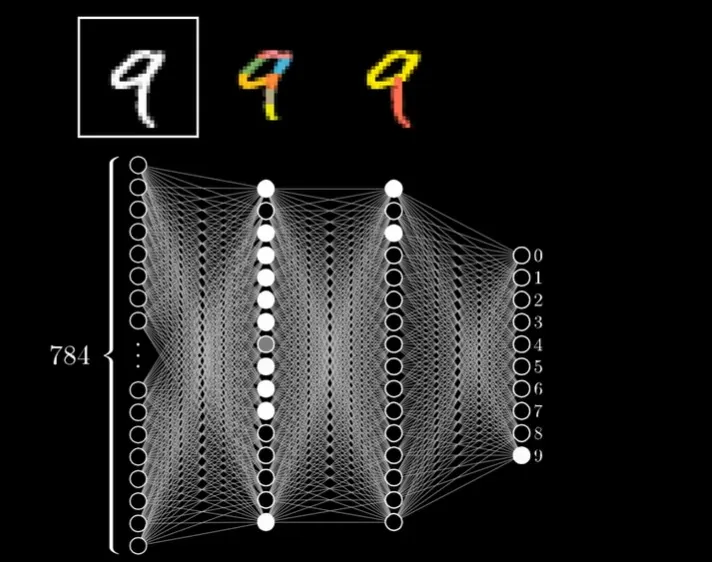
我們來假設我們挑選了第二層的某一個神經元,我們叫做神經元A好了,而這個神經元A是可以決定是否圖案中有這樣的一個短線(如下圖),那麼因為第一層的784個神經元都有連接到這個第二層的這個神經元A,所以我們可以說這784個神經元都有各自的權重Weight可以影響這個神經元A,所以這些神經元的數值再乘上各自的權重,就會是這個神經元A的值了。
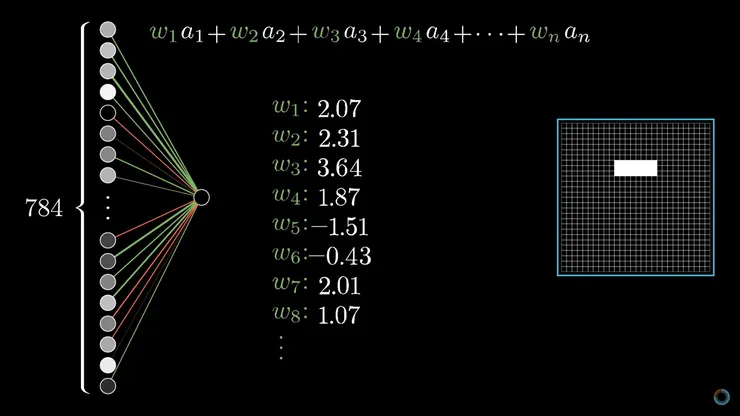
實際上這樣的公式叫做Activation function,還要加上sigmoid function跟誤差(Bias),這是為了要讓計算出來的數值可以維持在0~1之間的數值,因為我們的目的是要儘量簡單的介紹,所以這邊就不在繼續深究。重點是,這些誤差(Bias)跟權重(Weight),是會隨著我們訓練這個神經網路而變動的數值。
如果我們來想想這樣一個簡單的神經網路,輸入層有784個神經元,而中間兩層隱藏層僅有16 個神經元,輸出層只有10個神經元好了,那我們光是第一層到第二層的連結,就有784 (個神經元) x16個 權重,而每一條連結線都有自己不同的誤差值(Bias)
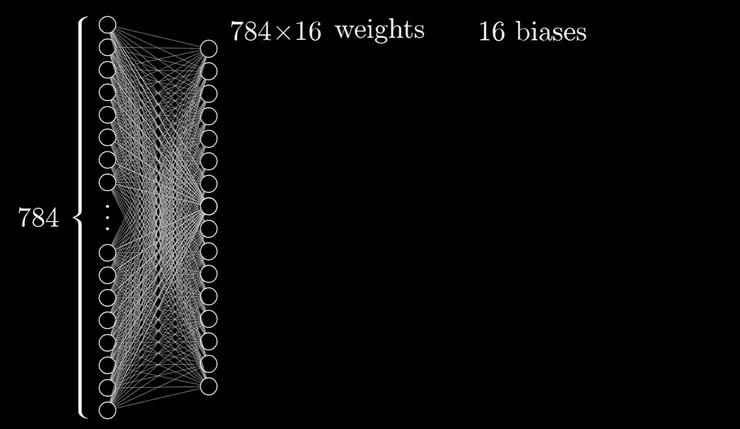
然後再往下計算整個神經網路的話,就會有總共有784*16加上16x16加上16x10的權重數,誤差值則是有16+16+10個。光是這樣的一個簡單的網路,就可以想像成有13002個數值會隨時變動,導致輸入的資料到輸出的結果會有不同的結果。

這13002個會變動的權重Weight跟誤差值Bias就是我們希望神經網路透過學習而能夠得到最佳值的,我們相信,經過學習的神經網路,可以替這13002的數值找到最佳的解答,然後我們輸入的數字圖片都可以被正確的辨識。
這麼簡單基礎的神經網路,都會需要13002個數值,不是很可怕嗎? 而且實際上的神經網路,每一層可能都有遠超768的神經元,而且神經網路的層數也可能會有數百層以上,可以想像這些權重Weight跟誤差值Bias是一個非常非常驚人的數量。但是我們回頭想想,如果神經網路沒有很複雜其實才可怕,畢竟神經網路是被認為可以邏輯推理的人工智慧的雛形,所以是應該會具備一定的複雜程度的。
關於神經網路的架構我們就很基礎的介紹到這邊,如果有興趣了解裡面的數學式的,請務必去看原本的英文影片,下一篇我們會介紹神經網路是如何透過餵進大量的資料去學習的,我們下次見囉。
























