
在我們的上一篇文章,我們把神經網路的架構用簡化再簡化的方式來說明(其實聽不懂得觀眾也不用洩氣,我認為神經網路確實是沒有辦法很直觀的理解,至少對理科以外的人來說....),我們至少知道了,以我們每次都拿來舉例的把圖片辨識成數字0~9的這個簡單神經網路來說,他的架構大概是長這樣有輸入層/輸出層/隱藏層,每一層都有很多的神經元,而相鄰的兩個層的神經元是fully-connected,也就是說每個神經元都有跟另外一層的每個神經元都有連接。我們舉第二層的某一個特定的神經元來說,他的數值是怎麼來的呢?就是由第一層每個神經元的數值乘上了權重(Weight),全部第一層神經元的數值x權重加起來以後呢,在加上誤差(Bias),在放入一個用來normalize的sigmoid function或Relu function之後了,就得到了這個第二層神經元的數值。
都看不懂沒關係,重點就是,這個神經網路中,我們的目的是要得到一個最接近完美的權重(Weight)跟誤差值(Bias)讓這個神經網路輸入的圖片可以得到正確的輸出,也就是完美的判斷到底是哪一個數字。
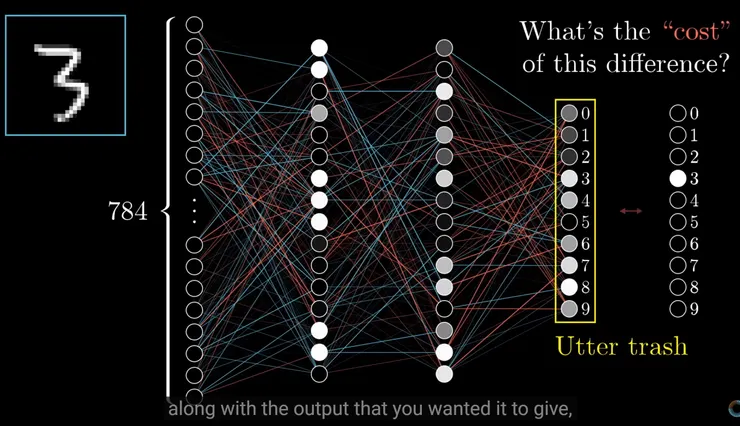
可是到底要怎麼得到這樣完美的權重跟偏差值呢? 這就要提到神經網路中利用Back Propagation來學習了。我們會設法用最簡單忽略大部分計算細節的方式來說明。以下圖來說,我們的輸入是這個手寫的3,那麼我們最希望的輸出應該就是如圖最右邊的,在代表3的這個神經元數值是1,其他的神經元數字是0,但是事實上沒有受過訓練的神經網路出來的結果是這樣呢? 可能就是如圖上所看到的一團糟,除了代表3的神經元以外,其他神經元也有非常多的數值。
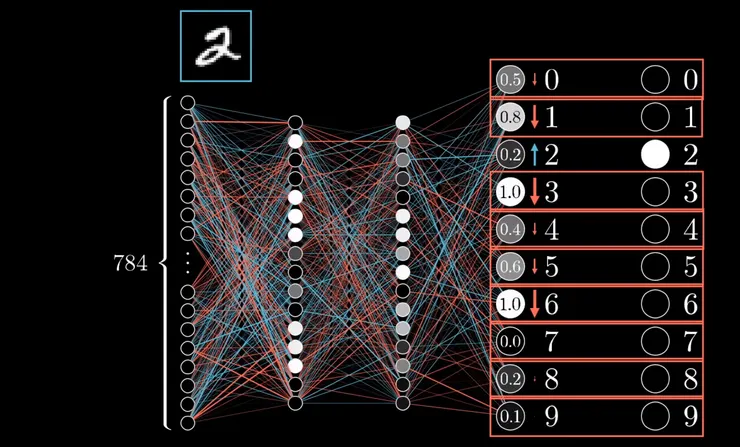
在仔細看一另一個訓練輸入手寫數字2的例子,一樣是沒有受過訓練的網路,我們假設輸出層的結果是這樣,那麼你應該會希望代表2的神經元的數值要上升,然後代表其他數字的神經元的數值要下降,如下圖。
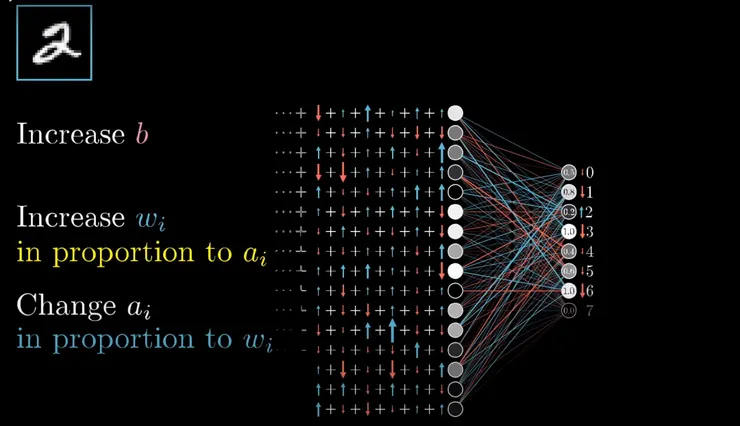
但是這個神經元的數值是怎麼來的呢? 如我們開頭所說的,當然就是從上一層的神經元經過權重跟偏差值的計算得來的,如下圖。舉例來說我們希望代表2的這個神經元(我們叫他A2好了)數值越高越好,那麼在前一層的神經元裡面,數值是正的神經元,你會希望它連結到A2這個神經元的權重越高越好,或者是你也會希望這個誤差值能夠越高越好,這樣得到的A2的數值當然就會比較高囉。最後一點就是你會希望權重高的神經元數值越高越好,等等但是要怎麼影響神經元的數值呢? 我們不是只能調整權重跟誤差值嗎? 所以要影響神經元的數值,就要再回到上一層。

要影響倒數第一層的數值,我們就得回到倒數第二層,繼續類推,要影響倒數第二層的數值,我們就必須再回到倒數第三層。這也就是為什麼這個方法叫做反向傳播演算法Back Propagation 。
經過這樣一層又一層的推回去,我們就知道了,該針對每一層的權重(Weight)跟誤差值(Bias)該做怎樣調整(是要調低還是調高呢?該調整多少?)。但是別忘了這樣只是針對一個手寫的"2"做調整而已,我們還有千千萬萬個訓練數字跟其他的手寫數字要做訓練,所以我們應該把這些都列出來如下圖,就會發現針對每個手寫數字,每一層的權重跟每一層的誤差值我們都有希望他調整的方向,光以這個簡單的網路來看,就有13002個權重跟誤差值是我們需要去調整的。
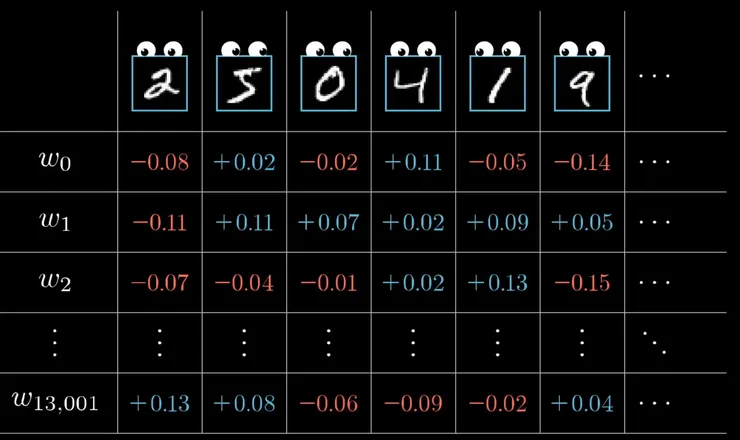
最後我們把這些所有訓練的結果加總起來,我們就得到了針對每個權重還有偏差值,我們希望調整的方向。
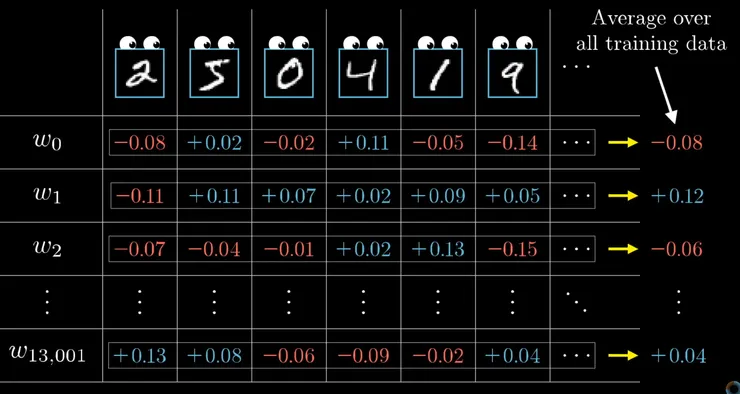
針對我們得到的結果,去調整這個神經網路裡面的權重跟還誤差值,我們就完成了....一次的訓練! 是的,因為這是一個平均值,所以對每一個數值來說都不夠完美,實際上為了讓權重還有誤差值能夠趨近完美,還需要經過非常多次的iteration (反覆訓練) 才能讓整個網路更正確的判斷數字。 我們今天舉的例子是簡化又簡化過,想要讓大家稍微理解一下到底神經網路的訓練是怎麼做的。實際上為了能夠讓神經網路的訓練更加地有效率,有非常多神經網路訓練的優化方法,這些當然就留給對深度學習有興趣的人可以去看原本的影片囉。
今天我們這篇就介紹到這篇,如果有說錯的或是者是希望替我補充的,都歡迎留言給我,我們下次見囉。























