Google Tesseract Config說明,程式範例實際修改示範
前言
Tesseract 的 config 檔案用於指定 OCR 引擎的設定和參數。這些參數可以影響文本識別的結果本文將彙整常用參數調整,並呈現不同參數出現不同的辨識結果
官網Tesseract OCR參數說明連結
以下是一些常見的 Tesseract config 參數的說明:
tessedit_char_blacklist:指定要在辨識過程中忽略的字符。例如,-c tessedit_char_blacklist=0123456789 可以排除數字。
tessedit_char_whitelist:指定僅考慮的字符,忽略其他字符。例如,-c tessedit_char_whitelist=0123456789 只考慮數字。
oem:指定 OCR 引擎模式(OCR Engine Mode)。
常的值有:
0:OEM_TESSERACT_ONLY — 使用 Tesseract 引擎。
1:OEM_LSTM_ONLY — 使用 LSTM 引擎。
2:OEM_TESSERACT_LSTM_COMBINED — 同時使用 Tesseract 和 LSTM。
psm:指定頁面分割模式(Page Segmentation Mode)。
常見的值有:
3:PSM_AUTO — 自動分割。
6:PSM_SINGLE_COLUMN — 單列文本。
11:PSM_SPARSE_TEXT — 稀疏文本。
lang:指定要辨識的語言。例如,lang = eng 表示辨識英文。tessedit_create_pdf:設定為 1 時,可以將辨識結果輸出為 PDF 文件。user_words:指定自定義詞典文件,用於提供辨識引擎額外的詞彙。user_patterns:指定自定義模式文件,用於提供辨識引擎額外的文本模式。preserve_interword_spaces:當設定為 1 時,保留單詞間的空格。chop_enable:啟用或禁用單字切割。
— oem <engine_mode> (OCR Engine Mode):
- 這個參數指定了 Tesseract 使用的 OCR 引擎模式,即 OCR 引擎的運行方式。
- 例如, — oem 3 表示使用 LSTM OCR 引擎,這是 Tesseract 的一種基於長短時記憶(LSTM)的 OCR 模型。LSTM 模型通常用於處理具有複雜結構和上下文相依性的文本,可以提供更高的識別精度。
- 其他 oem 模式值還包括 0(默認 OCR 引擎),1(LSTM OCR 引擎),2(Legacy OCR 引擎),等等。根據你的需求和應用場景,你可以選擇不同的 OCR 引擎模式。
OCR Engine modes:
0 Legacy engine only.
1 Neural nets LSTM engine only.
2 Legacy + LSTM engines.
3 Default, based on what is available.
— psm <mode> (Page Segmentation Mode):
0 只進行方向和腳本檢測(OSD)。
1 使用OSD進行自動頁面分割。
2 自動頁面分割,但不進行OSD或OCR(未實現)。
3 完全自動的頁面分割,但不進行OSD(默認值)。
4 假設是可變大小的單列文本。
5 假設是垂直對齊的單一統一文本區塊。
6 假設是單一統一的文本區塊。
7 將圖像視為單一文本行。
8 將圖像視為單一單詞。
9 將圖像視為圓形中的單一單詞。
10 將圖像視為單一字符。
11 稀疏文本。以無特定順序尋找盡可能多的文本。
12 具有OSD的稀疏文本。
13 原始行。將圖像視為單一文本行
修改的程式範例由我上一篇文章的延伸[OCR_應用]Tesseract-OCR_擷取字元面積
使用字元黑名單或白名單:
tessedit_char_whitelist:僅允許辨識指定字符。
tessedit_char_blacklist:排除指定字符。
#原參數
config = r'--oem 3 --psm 6'
未新增黑白名單前
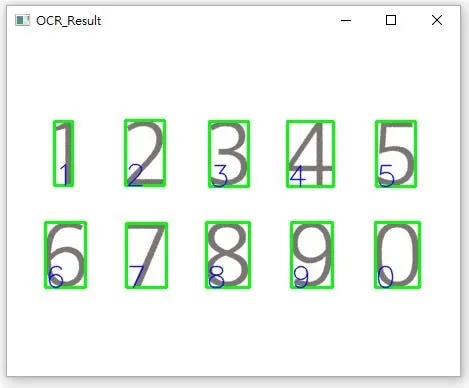
config = r' --oem 3 --psm 7'
設定排除指定字符: 123
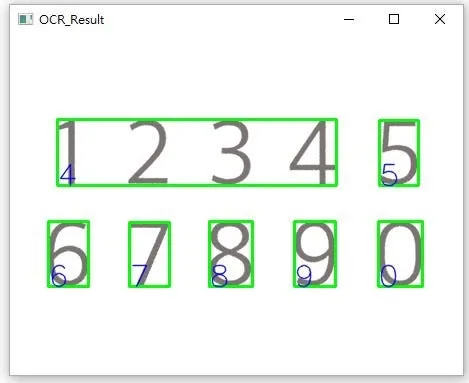
config = r'-c tessedit_char_blacklist= 12345 --oem 3 --psm 6'
設定僅允許辨識指定字符:123
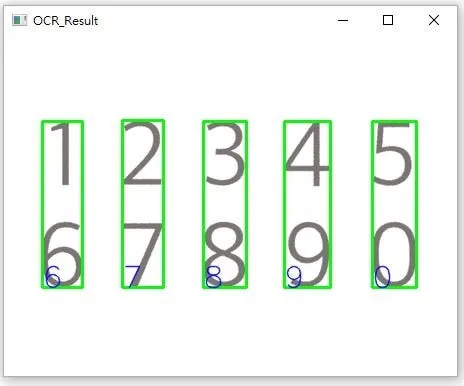
config = r'-c tessedit_char_whitelist=123 --oem 3 --psm 6'
— psm <mode>
原先示範的參數為 — psm 6 ,他的解釋是假設是單一統一的文本區塊,是可以由上往下去讀取文本的,那也有其他的操作只能讀單一文本行的,例如 — psm 7
config = r' --oem 3 --psm 7'
在不同的使用情境下,不同的psm mode都會去影響到辨識的良率,因為不同的psm分割OCR的方式有所不同
因為我們使用的樣本過於簡單,無法詮釋每一種模型,有機會在好好的每一種都來模擬一番



















