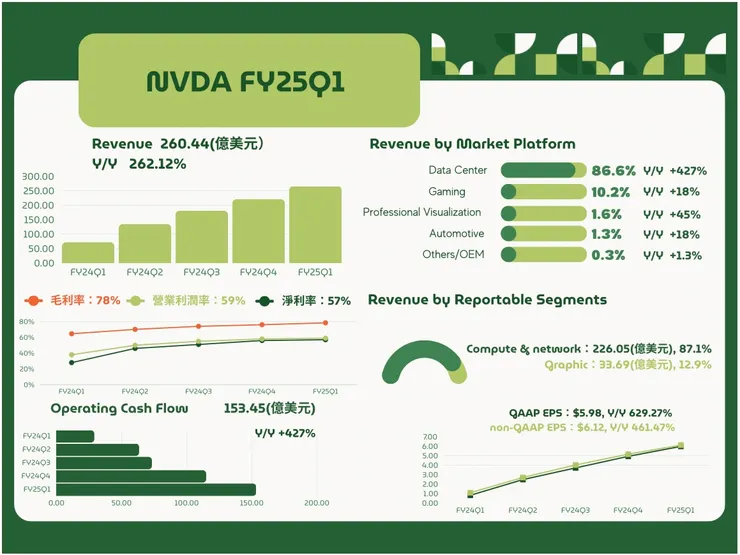
- 季度營收創歷史新高 260 億美元,較第四季成長 18%,較去年同期成長 262%
- 十換一遠期股票分割於 2024 年 6 月 7 日生效
- 分拆後季度現金股利提高 150% 至每股 0.01 美元
- GAAP EPS為 5.98 美元,季增 21%,年增 629%,non-GAAP EPS為6.12 美元,較上一季成長 19%,比去年同期成長 461%
- Operating income Margin 59%,net income Margin 57%
- 營業現金流來到了153.45億美元,Y/Y +427%

- 資料中心季度營收創紀錄,達 226 億美元,較第四季成長 23%,較去年同期成長 427%
- Gaming業務 第一季遊戲營收為 26 億美元,季減 8%,年增 18%
- Profession Visualization 第一季營收為 4.27 億美元,季減 8%,年增 45%
- Automotive 營收為 3.29 億美元,季增 17%,年增 11%。
展望
NVIDIA對2025財年第二季的展望如下:
- 收入預計為 280 億美元,上下浮動 2%。
- GAAP 和非 GAAP 毛利率預計分別為 74.8% 和 75.5%,上下浮動 50 個基點。全年毛利率預計在 70% 左右。
- GAAP 和非 GAAP 營運費用預計分別約為 40 億美元和 28 億美元。預計全年營運支出將成長 40% 左右。
- GAAP 和非 GAAP 其他收入和支出預計約為 3 億美元,不包括非附屬投資的損益。
- GAAP 和非 GAAP 稅率預計為 17%,上下浮動 1%(不包括任何離散項目)。
想法與紀錄
- 這次全村の希望輝達財報開出其實就只證明了一件事:「只有輝達可以超越輝達」
- CEO黃仁勳表示,下一次工業革命已經開始,許多公司和國家正在與 NVIDIA 合作,將價值數兆美元的傳統資料中心安裝基礎轉向加速運算,並建造新型資料中心、人工智慧工廠,以生產新商品—人工智慧;人工智慧將幾乎為每個產業帶來顯著的生產力提升,幫助企業提高成本和能源效率,同時擴大收入機會,這一點可以從各大CSP業者持續擴大資本支出的動作來證實(像是Microsoft、Google、AWS、Meta )
- 目前絕大多數的運算收入都是由 Hopper GPU 架構所驅動,本季對Hpper的需求持續增加,由於 CUDA 演算法創新,我們能夠將 H100 上的 LLM 推理速度提高高達 3 倍,這意味著為 Llama 3 模型提供服務的成本降低了 3 倍。
- H200 的推理性能幾乎是 H100 的兩倍,為生產部署帶來了巨大的價值,這意味著,在 NVIDIA HGX H200 伺服器上每花費 1 美元,為 Llama 3 提供服務的 API 提供者可以在 4 年內產生 7 美元的收入。
- Blackwell GPU 架構的訓練速度比 H100 快 4 倍,推理速度快 30 倍,並可在兆參數大型語言模型上即時產生 AI;Blackwell 與 Hopper 相比,TCO 和能耗降低了 25 倍
- NVDA確認,B系列晶片已開始生產一段時間,預計將於Q2小批量出貨、Q3放量、Q4 CSP業者使用
- Blackwell 上市客戶包括亞馬遜、Google、Meta、微軟、OpenAI、甲骨文、特斯拉和XAi
- 黃仁勳也宣布,NVDA在Blackwell的芯片架構之後,還有一款芯片,更新速度預計一年一更新
- 黃仁勳認為,就如同過去客戶從A100過渡到H100時的情形一樣,H100的需求依舊非常高
- 根據 MIT Future Tech Research ( https://arxiv.org/pdf/2403.05812.pdf ) LLM 的能力大約每 8 個月就會翻一倍,速度超過摩爾係數
因為有分析師提到對於,未來B200推出後是否會壓縮到H200市場的疑慮
由於我自己之前沒有在追A100這個部分,所以在我看了Nvidia官網上的深度學習說明和看了一些網路youtuber的影片之後,我自己對黃仁勳想表達的理解是:(只是我個人,不表示市場就是這樣認為)
- 過去的AI模型,其實就是去區別一個東西是什麼ex:給它一張貓狗照片,它可以通過照片當中的各種特性規律來分辨這是狗還是貓;而生成式AI模型不但可以區分這是狗還是貓,在確認它是貓之後,還能夠根據已分辨的特性規律,「自動」生成其他貓的圖片,也就是「擁有快速生成新內容」的能力
- 建立AI生成模型其中的關鍵之一就是要訓練這個模型,之前的AI模型在訓練時需要的是有標註的數據(ex:需要提供大量「已經標註」好的數據,來讓模型找規律,但問題在於,沒有那麼多已標注的數據來訓練模型,這就限制了AI的成長)
- 生成式AI的突破則是「不再需要那些已經標注好的數據,而是直接給模型大量的數據,讓它自己學習規律」,數據可以是任何形式(ex:文字、語言、圖片網頁資料等等)
- 須留意的是,LLM本身並不懂得「語言」,它只是透過文字規律去來推斷出下一個文字應該是什麼,所以用來訓練的文字可以是任何一種語言,包括編程語言(Meta打造的Llama 3就是另一種LLM)
- 可以想像要訓練這些模型,需要非常強大的算力和速度,因為「越能用越短時間內學習到越多的數據,這個模型就會越加成熟聰明」
- 根據黃仁勳的看法,他認為「時間」對於這些企業是非常非常寶貴的,為什麼越快建立數據中心,獲得訓練時間會是這麼寶貴?因為下一個取得主要進展的公司,就可以宣稱自己有了「開創式AI」,而第二名只能聲稱自己改善了0.3%,所以問題是,你想再次成為提供突破性人工智慧的公司還是提供更好 0.3% 的人工智慧的公司?這就是為什麼這場競賽與所有技術競賽一樣如此重要
- 黃仁勳聲稱,Blackwell除了是世界上最強大的芯片,同時能更好地節約能耗,並且還兼容各類數據中心的散熱系統,這還僅僅是模型訓練部分的應用
- 生成式AI真正的應用是在生成新內容的「推論(inferencing)」,也就是隨著應用領域越來越廣,需要解決的問題也會越來越複雜,所需要的算力速度要求也會越來越高,更強的算力速度意味著能應對更複雜的模型,隨著更多的使用者和每個使用者的使用強度增加,能帶來更高的算力需求
- 綜合以上,為了能在越短時間得到越聰明成熟的AI模型,我認為目前各大企業、CSP業者甚至是國家只會越渴求更高算力的芯片,而針對生成式AI模型,除了「訓練」還有「推論」,或許過去各家廠商所購買的H100、H200芯片可以用於推論(因為雖然算力較低,但訓練的時間較長、較成熟,但應該不會再有二次需求)而具有更強大算力速度的Blackwell架構芯片則可以進行訓練,訓練出更聰明成熟的模型,未來就能獲得更好更完整的推論
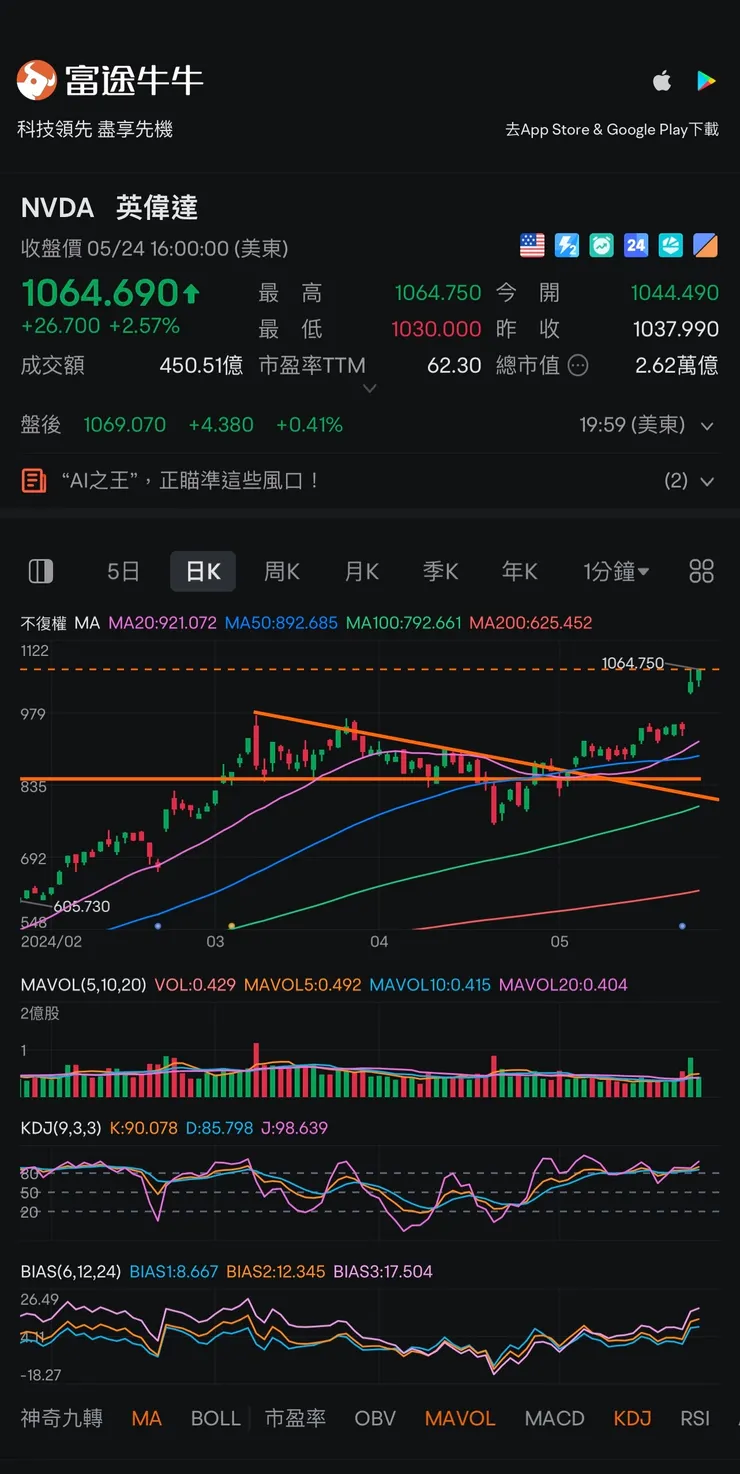
股價的部分反而簡單,畢竟要拆股了,我自己本身當然還是繼續持有,而就基本面和公司的本質來看,拆股不影響一間公司的本質,進出場的判斷除了基本面之外就是點位,但是拆股之後因為價格變便宜,在心理上會覺得更容易入手,所以我自己不論是拆股前或拆股後,都會依照自己的資金規劃和能力再繼續投入

























