因為不講理論嘛,直接上流程:
- 下載ComfyUI:https://www.comfy.org/
- 開啟後會預設請你下載一個模型,就載吧,也可以用用看。
- 下載模型:https://civitai.com/models
試想產圖的目標是什麼?想畫出動漫風格的角色?想畫出風景大山大海?還想要寫實的人物畫?到網站上瀏覽看看,也可以善用搜尋功能,先找到屬於checkpoint類型的模型,下載後放到ComfyUI/models/checkpoints資料夾內。沒想法的話就先使用剛剛系統要你下載的也可以。
- 開啟內建的工作流樣板(Workflow->Browse Templates),選擇Image Generation。

- 選擇你剛剛下載的模型,若是沒有顯示則嘗試按鍵盤R鍵,重新整理。

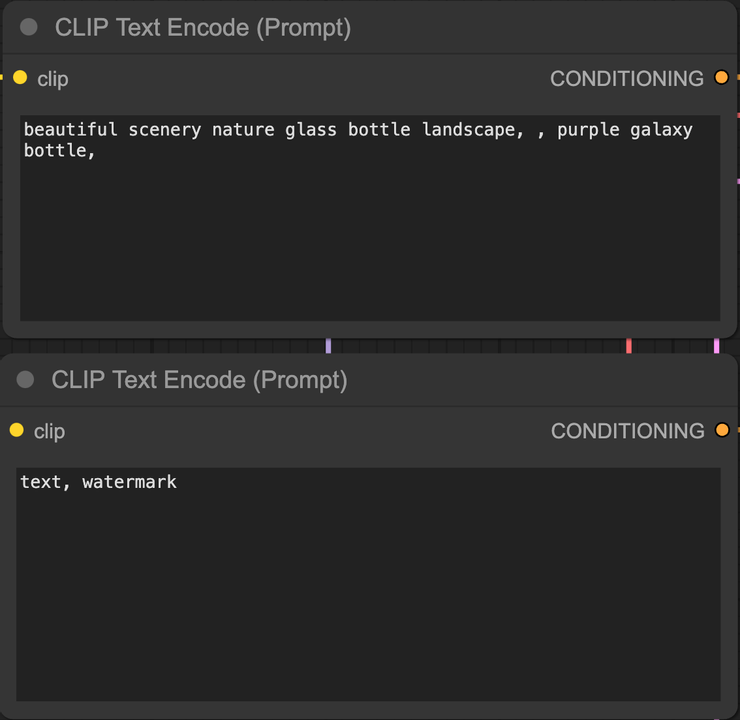
- 開啟ChatGPT,跟他說你在產圖,跟他說明想要畫的內容後,請他提供正面及負面提示詞,並在上下CLIP Text Encode(Prompt)內分別填入正面及負面提示詞。
- 回到剛剛下載模型的頁面,上面一般來說會推薦使用的參數,依序填到KSampler內,沒有特別說明的就填預設。

- 按Run執行,等結果。圖片會產生在ComfyUI/output底下。

講點後話
上面的流程就是什麼都不想管,我就是要圖!圖!圖!
那可能會有幾種狀況,我也列出來方便大家想想要往什麼方向查找資料:
- 圖片根本沒產出來!跑到一半一堆錯誤訊息 -> 滿大的可能是GPU未達到使用需求,可能是VRAM過小,導致流程被中斷了。若是如此建議可以找線上有限免費提供的硬體,開始第一步。
- 圖片怎麼畫的跟我預想的不同(風格或內容不符合需求) -> 可能是模型挑錯了,或是模型本身沒有被訓練你想要的情境、人物姿勢、物品描述。
我目前是使用Flux模型,有幾個特色,也讓大家參考一下:
- 有多種衍生的模型,可以因應不同的GPU VRAM大小使用對應的模型
- 自然語言理解能力極強,提示詞甚至建議使用整個句子進行描述,更貼近人類的語言(而不是一個詞、一個詞斷句)
- 社群上多種工作流可套用使用,不用重複造輪子
那我要繼續研究研究了,有什麼可以分享的再貼上來。


















