久久沒更新,把這幾天更新在wordpress的文章搬過來囉!
這是篇自己練習爬蟲,並把爬下來的文字內容透過jieba套件分析後產出文字雲的小練習專案先來看成品長怎樣吧!
2022年6月12日的熱門新聞
[新聞] 女兒遭性侵拍光碟亡!父撂人復仇凌虐致死 代價服刑12年賠76萬

會使用到的環境
- Python: 3.7.10
- requests: 抓取網頁
- BeautifulSoup: 分析網頁
- matplotlib: 繪圖並顯示
- wordcloud: 將文字生成文字雲
- jieba: 文字斷詞工具
先從網頁爬蟲開始
在網路上找到的PTT爬蟲大多是以ptt.cc作為爬蟲目標網站,由於我目標是希望能爬取熱門的討論新聞,雖然可以藉由標題分析來爬取,但出於懶人心態還是另外找尋了PTT熱門新聞網頁版的頁面如下
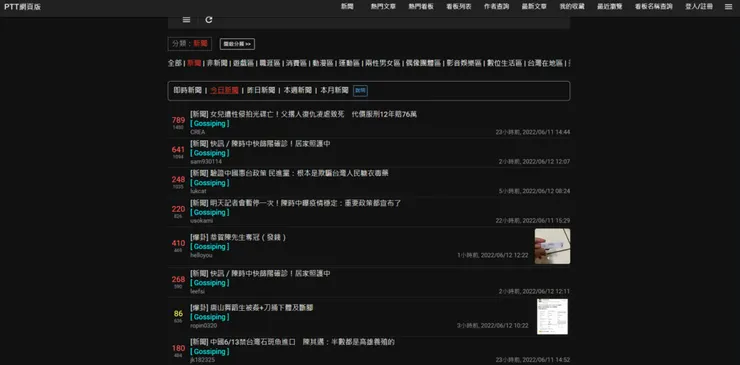
第一步觀察網頁
觀察網頁是最基礎但也是最難的第一步,觀察網頁的詳細教學可以搜尋Google上有很多大神的教學,這邊推薦一位整理了許多Python爬蟲上會運用到的CSS元素整理的教學網站
總之先來確定所要爬取的目標,在這個分頁裡面我想爬取的目標是標題以及文章網址的連結。透過chrome的「檢查」可以看到以下的畫面
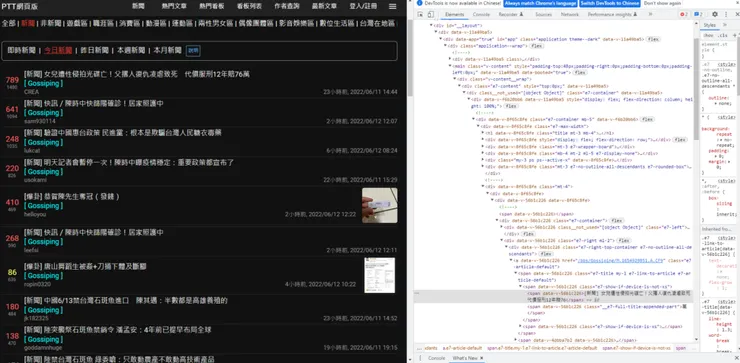
透過「檢查」畫面可以看到,所需要的文章標題及連結被包裹在同一個區塊裡面
<div data-v-56b1c226="" class="e7-right-top-container e7-no-outline-all-descendants">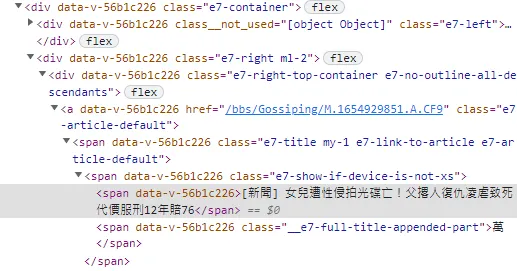
把需要的內容爬取下來
已經找到需要爬取的目標位置後,接下來開始進行爬蟲
首先先載入爬蟲需要的套件及設定
from bs4 import BeautifulSoup
import requests
# 掛上headers模擬使用者讀取網頁的行為 (主要用意是部分網站會有反機器人爬蟲機制)
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.92 Safari/537.36'}
# 目標網站
url = 'https://www.pttweb.cc/hot/news/today'
# 發出 get請求
resp = requests.get(url, headers=headers)
# 網頁編碼
resp.encoding = 'utf-8'
# 透過 美麗的湯 進行網頁解析
soup = BeautifulSoup(resp.text, 'html.parser')
# 找出所有 div區塊中 帶有目標class名的元素
divs = soup.find_all('div', 'e7-right-top-container e7-no-outline-all-descendants')
以上的過程是先將上一步中所觀察到的元素抓出來,在這一步的過程裡很容易出現抓到不想要的東西,可以透過python的print函數隨時確認找出來的東西是不是符合原始設定的目標再進行修正
例如,在爬取以上的元素時,發現當標題過長會爬取到 \u3000 的文字內容,這是Unicode編碼標準中屬於CJK字元的全形空格符號,因此在爬取的過程裡需要將其剃除
# 新增個list存取爬下來的內容
articles = []
# 換個網頁爬文章內容
root = 'https://www.ptt.cc'
# 在美麗的湯整理好的 divs中的各個區塊把需要的元素取出
for div in divs:
# 文章連結
link = div.find('a')['href']
# 文章標題
title = div.find('span', 'e7-show-if-device-is-not-xs').text
articles.append({
# 文章標題中的全形空白編碼以空白取代
'title':title.replace('\u3000', ' '),
'link':root + link + '.html'
})
透過以上的步驟可以爬取出如下的結果
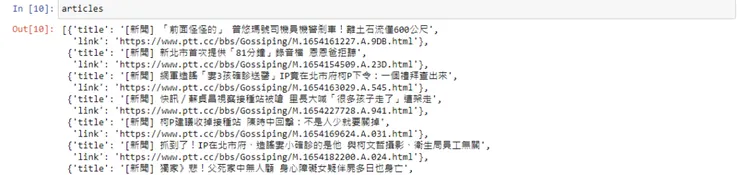
那這邊可能會有疑問的是,為什麼連結的部分要換成 ptt.cc 而不是在原網站中爬取呢?
主要原因是因為原網站中的留言有做其他的留言載入的處理,我看不太出來其爬取的位置在哪裡,或許可以透過selenium套件爬取,但太麻煩了就索性換到熟悉的 ptt.cc吧
文章留言爬蟲
在上個步驟中已經將所需要爬取的文章標題及連結都爬取下來了,接下來所要做的事情就是將各個文章中的留言內容取出並存下來
for article in articles:
# 從 articles的列表中取出連結 掛上headers (八卦版的cookie中需要加入 over18=1 才能看到內容喔)
res = requests.get(article['link'], headers = {'cookie': 'over18=1;'})
# 如果網頁掛掉了就跳過它
if res.status_code == 404:
articles.remove(article)
同樣的,在ptt.cc裡面也需要觀察網頁的元素來找出所想要爬取的目標位置在哪裡
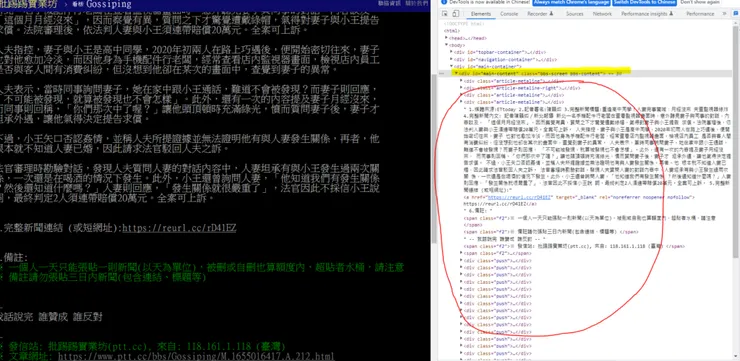
從圖中可以看到,在ptt.cc裡,主要的文章內容都在 id='main-content'的區塊中,而要構成文字雲的關係,並不需要文章內容,僅需要爬取推文就行了,因此爬取的目標在 class="push"的推文內容
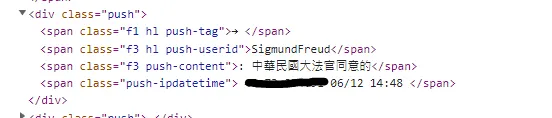
觀察class="push"的區塊中,可以看到所要爬取的推文內容存在 class="f3 push-content"之中,但文字內容也包含了「:」這個開頭的標點符號,因此在將其爬取下來的過程中一併剃除處理吧
for article in articles:
res = requests.get(article['link'], headers = {'cookie': 'over18=1;'})
if res.status_code == 404:
articles.remove(article)
else:
soup = BeautifulSoup(res.text, 'lxml')
main = soup.find('div', id='main-content')
main_tag = main.find_all('div', class_='push')
# 新增一個位置存取文章的推文內容
comment = []
for i in main_tag:
# 如果沒有推文就跳過
if not i.find('span', 'push-tag'):
continue
# 把: 標點符號替換掉
push_content = i.find('span', 'push-content').text.replace(': ',"")
# 推文內容存入
comment.append(push_content)
article['content'] = comment
以上就完成了各文章的推文內容爬蟲啦~~~
開始製作文字雲吧
什麼是文字雲?
文字雲其實就顧名思義,是以純文字所構成的雲朵圖。在這次的應用上來說,各個文章的推文內容,會依照每個字詞出現的頻率來構成文字雲。我們可以透過觀看文字雲中出現的詞語來快速了解到,鄉民們對於各個新聞的反應如何。
製作文字雲
不過單純地將文字輸出做成文字雲,很容易出現無意義的字詞,例如「你我他」之類的沒有實質意義的內容,因此需要將文字進行解析並取出有意義的詞語,再依照出現的頻率製作文字雲
而解析有意義的詞語的步驟稱作「斷詞」。相比於英文,中文的斷詞非常複雜,這邊就不多做解釋了,直接套用中文斷詞套件最有名的jieba套件 (台灣的中研院也有個繁體中文斷詞套件 ckiptagger 但使用起來非常緩慢 不是非常推薦使用)
製作文字雲的步驟為,透過jieba解析出文字詞頻後,輸出給 wordcloud套件做成文字雲,再藉由matplotlib輸出成圖
開始coding吧
首先載入需要使用的套件
import jieba
import matplotlib.pyplot as plt
from wordcloud import WordCloud
設定jieba分析詞頻所要使用的字典,這個字典可以自己設定或是到jieba的github上下載
jieba.set_dictionary('dict.txt.big')由於爬取下來的推文留言是用逗號來區別開來並存在同一個列表之中,為了讓jieba能夠進行分析,需要將逗號改成空格,把推文內容連接起來成一個文本
之後抓中取前100個重要的字詞來象徵各個文章的推文代表詞
# 抓前十篇熱門新聞製作文字雲
for article in articles[:10]:
content_text = article['content']
content_list = " ".join(content_text)
tfidf_fre = jieba.analyse.extract_tags(content_list, topK=100, withWeight=True, allowPOS=(),withFlag=True)
# 把分析完的詞頻輸出成字典
count_dic = {}
for i in range(len(tfidf_fre)):
count_dic[tfidf_fre[i][0]] = tfidf_fre[i][1]
# 把字典交給wordcloud做成文字雲
myWordClode = WordCloud(
width=1200, # 圖的寬度
height=600, # 圖的長度
background_color="black", # 背景顏色 預設是白色
colormap="Dark2",
font_path='SourceHanSansTW-Regular.otf' # 輸出字體 必須將字體的檔案放在同個資料夾下
).fit_words(count_dic)
# 用PIL顯示文字雲
plt.figure(figsize=(8, 6), dpi=100)
plt.imshow(myWordClode)
plt.axis("off")
print(article['title'])
print(article['link'])
plt.show()
以上就完成了熱門新聞的推文留言文字雲囉!
完整的程式碼在這
from bs4 import BeautifulSoup
import requests
import jieba
import matplotlib.pyplot as plt
from wordcloud import WordCloud
import jieba.analyse as analyse
# 掛上headers模擬使用者讀取網頁的行為 (主要用意是部分網站會有反機器人爬蟲機制)
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.92 Safari/537.36'}
# 目標網站
url = 'https://www.pttweb.cc/hot/news/today'
# 發出 get請求
resp = requests.get(url, headers=headers)
# 網頁編碼
resp.encoding = 'utf-8'
# 透過 美麗的湯 進行網頁解析
soup = BeautifulSoup(resp.text, 'html.parser')
# 找出所有 div區塊中 帶有目標class名的元素
divs = soup.find_all('div', 'e7-right-top-container e7-no-outline-all-descendants')
# 新增個list存取爬下來的內容
articles = []
# 換個網頁爬文章內容
root = 'https://www.ptt.cc'
for div in divs:
link = div.find('a')['href']
title = div.find('span', 'e7-show-if-device-is-not-xs').text
articles.append({
'title':title.replace('\u3000', ' '),
'link':root + link + '.html'
})
for article in articles:
res = requests.get(article['link'], headers = {'cookie': 'over18=1;'})
if res.status_code == 404:
articles.remove(article)
else:
soup = BeautifulSoup(res.text, 'lxml')
main = soup.find('div', id='main-content')
main_tag = main.find_all('div', class_='push')
# 新增一個位置存取文章的推文內容
comment = []
for i in main_tag:
# 如果沒有推文就跳過
if not i.find('span', 'push-tag'):
continue
# 把: 標點符號替換掉
push_content = i.find('span', 'push-content').text.replace(': ',"")
# 推文內容存入
comment.append(push_content)
article['content'] = comment
jieba.set_dictionary('dict.txt.big')
# 抓前十篇熱門新聞製作文字雲
for article in articles[:10]:
content_text = article['content']
content_list = " ".join(content_text)
tfidf_fre = jieba.analyse.extract_tags(content_list, topK=100, withWeight=True, allowPOS=(),withFlag=True)
# 把分析完的詞頻輸出成字典
count_dic = {}
for i in range(len(tfidf_fre)):
count_dic[tfidf_fre[i][0]] = tfidf_fre[i][1]
# 把字典交給wordcloud做成文字雲
myWordClode = WordCloud(
width=1200, # 圖的寬度
height=600, # 圖的長度
background_color="black", # 背景顏色 預設是白色
colormap="Dark2",
font_path='SourceHanSansTW-Regular.otf' # 輸出字體 必須將字體的檔案放在同個資料夾下
).fit_words(count_dic)
# 用PIL顯示文字雲
plt.figure(figsize=(8, 6), dpi=100)
plt.imshow(myWordClode)
plt.axis("off")
print(article['title'])
print(article['link'])
plt.show()
題外話
這次的文字雲製作算是拖延了好久好久才做成的小專案,先自我反省個幾秒。主要的問題大多發生在爬蟲的過程中,對於網站的組成架構不熟悉導致卡關。
另外,在中文斷詞分析的部分,只用了很簡單的分析方式取出斷詞,要做到更精細的調整,例如捕捉情緒等等的需要NLP自然語言分析的能力,但這一塊對我而言過於艱深難懂,而且沒什麼必要所以就此打住囉
透過文字雲的製作,可以大致上看出鄉民們對於新聞的想法,但文字雲並不代表全部,如果要對輿論進行分析還需要更多的研究觀察。
總之,就先這樣咧,歡迎留言討論其他細節囉!























