本教學從 網路爬蟲 至 機器學習基礎 到 TensorFlow深度學習框架。
網路爬蟲
Beautiful Soup
安裝beautifulsoup4,用來分析html資料
pip install beautifulsoup4安裝requests套件,將html資料抓回來顯示
pip install requestslxml ,用於解析和編輯 XML 和 HTML 文檔
pip install lxmlhtml5lib ,用於解析 HTML5
pip install html5lib基本使用範例
import requests
from bs4 import BeautifulSoup
url = "http://127.0.0.1/py"
response = requests.get(url)
html_doc = response.text
soup = BeautifulSoup(html_doc, 'html.parser')
print(soup.prettify())
當使用文件讀取時
import requests
from bs4 import BeautifulSoup
with open('index.htm') as f:
html_doc = f.read()
soup = BeautifulSoup(html_doc, 'html.parser')
print(soup.prettify())
html.parser這個是python的解析程序
prettify()函數用來將soup這個物件美化
soup變數則是html_doc的解析結果
取出字串
print(soup.head.title.string)找出所有標籤
print(soup.find_all('a'))取得連結位置或class名稱內容
for link in soup.find_all('a'):
print(link.get('href'))
使用ID找資料
print(soup.find(id="a1"))取得所有文字內容
print(soup.get_text())基本爬蟲範例可參照 Python 基礎
Google 新聞爬找方式 request | 網路爬蟲
詳細原碼: https://reurl.cc/oL0ObM
爬取動態網頁內容
pip install selenium範例
# coding: utf-8
from bs4 import BeautifulSoup
from selenium import webdriver
import datetime
#交通部氣象局 - 台中市
url = 'https://www.cwb.gov.tw/V8/C/W/OBS_County.html?ID=66'
#啟動模擬瀏覽器
driver = webdriver.Chrome()
#取得網頁
driver.get(url)
#指定 lxml 作為解析器
soup = BeautifulSoup(driver.page_source, features='lxml')
#<tbody id='stations'>
tbody = soup.find('tbody',{'id':'stations'})
#<tbody>内所有<tr>標籤
trs = tbody.find_all('tr')
#print(trs)
#使用datetime取得 年
year = str(datetime.datetime.now().year)
#對list中的每一項 <tr>
for tr in trs:
#<tr>內的<th>標籤
th = tr.th
#取得下個標籤內的文字
name = th.next_element.text
if not name == '儀器故障':
date = th.nextSibling.text
tds = tr.find_all('td')
#print(len(tds))
if len(tds)>2 :
temp = tds[1].text
else:
temp = '-'
print(name, temp, date)
else:
print(name, '儀器故障')
#關閉模擬瀏覽器
driver.quit()
爬找台灣期貨交易所
透過上個範例,使用爬取動態網頁的方式
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.by import By
url="https://mis.taifex.com.tw/futures/RegularSession/EquityIndices/FuturesDomestic"
#啟動模擬瀏覽器
driver = webdriver.Chrome()
#取得網頁代馬
driver.get(url)
#btn = driver.find_element(By.CLASS_NAME, 'btn')
btn = driver.find_element(By.TAG_NAME, 'button')
btn.click()
#指定 lxml 作為解析器
soup = BeautifulSoup(driver.page_source, features='lxml')
#print(soup)
print(soup.prettify())
table = soup.find('tbody')
print(table)
#關閉模擬瀏覽器
driver.quit()
ps.
查找元素的方法 ,可在 selenium 網站找到資訊
但在 4.0版時,需修改語法
btn = driver.find_element_by_class_name("btn")改為
btn = driver.find_element(By.CLASS_NAME, 'btn')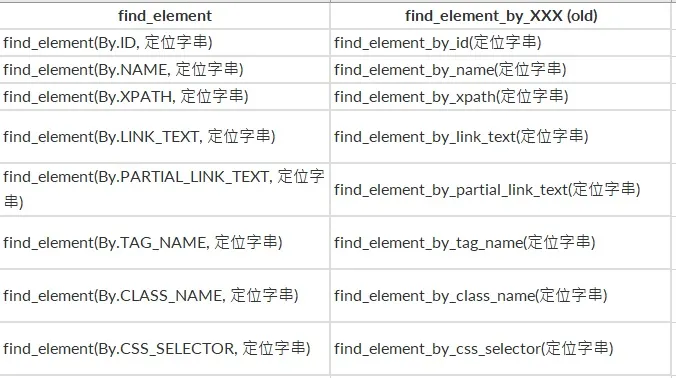
接著,會發現當我們爬取tbody標籤時,取得的資料為
<tbody></tbody>使用 print(soup.prettify()) 則發現
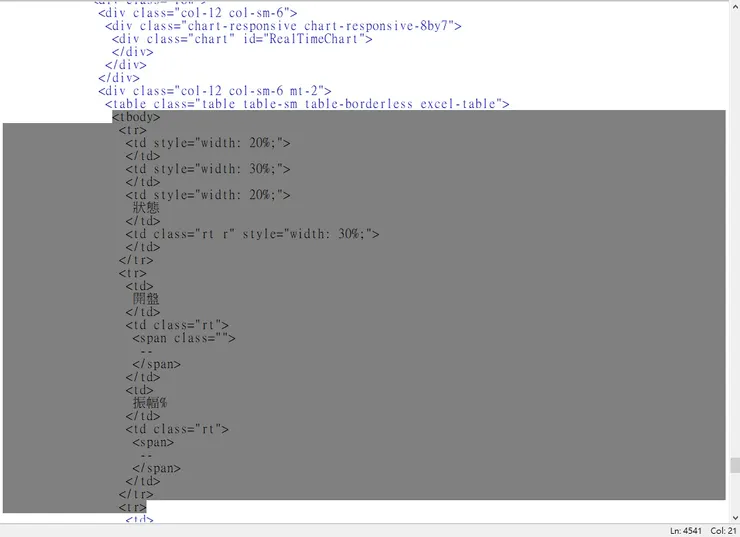
因此,需要另外使用爬蟲的方式進行
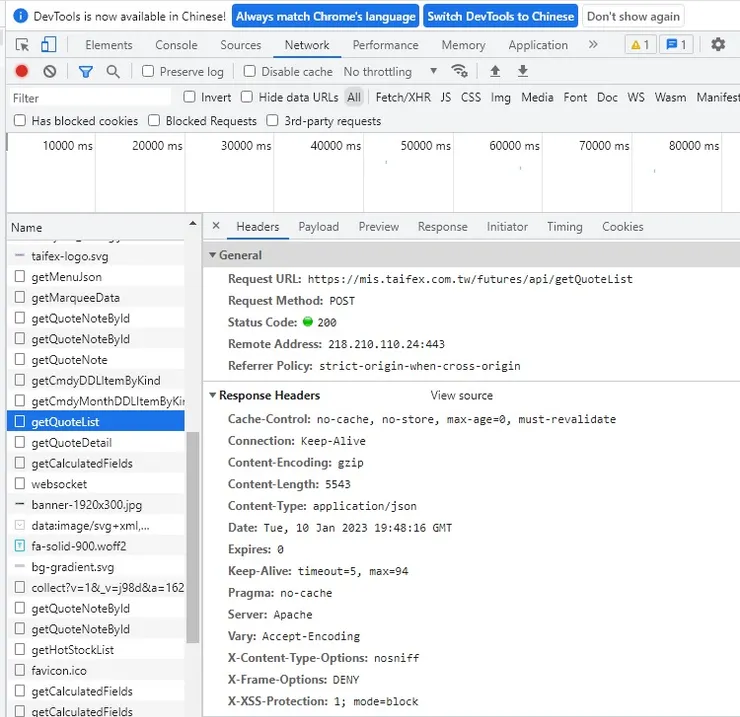
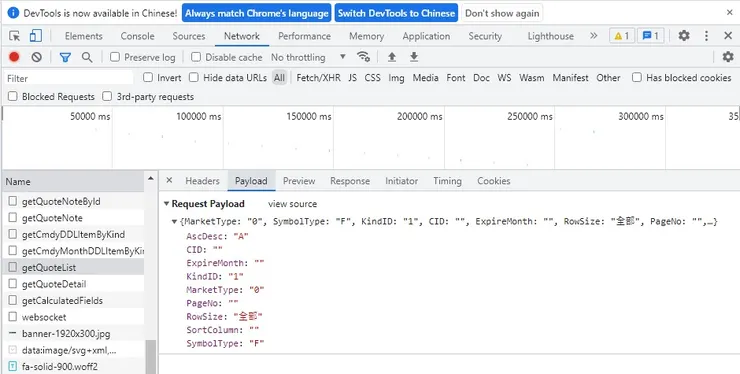
範例
# 下載資料套件
import requests as r
# 資料處理套件
import pandas as pd
from bs4 import BeautifulSoup
url = "https://mis.taifex.com.tw/futures/api/getQuoteList"
payload = {"MarketType":"0",
"SymbolType":"F",
"KindID":"1",
"CID":"TXF",
"ExpireMonth":"",
"RowSize":"全部",
"PageNo":"",
"SortColumn":"",
"AscDesc":"A"}
res = r.post(url, json = payload)
data = res.json()
df = pd.DataFrame(data['RtData']['QuoteList'])
df = df[["DispCName", "Status", "CBidPrice1", "CBidSize1", "CAskPrice1", "CAskSize1", "CLastPrice", "CDiff", "CAmpRate", "CTotalVolume", "COpenPrice", "CHighPrice", "CLowPrice", "CRefPrice", "CTime"]]
df.columns = ['商品', '狀態', '買進', '買量', '賣出', '賣量', '成交價', '漲跌', '振幅%', '成交量', '開盤', '最高', '最低', '參考價', '時間']
df.to_csv('futures_regular_trading.csv')
print(df)
這方式 也就是 【Python期貨爬蟲 第2集】台指期即時成交行情免費下載|成為盤中大贏家即時分析行情!
這影片的方法
爬蟲相關補充:
爬蟲技巧
動態網頁爬FB粉絲專頁
翻頁的做法
降低被偵測封鎖的方法
JS動態生成的爬蟲法
機器學習
機器學習類型主要分為三類:監督學習,非監督學習和強化學習。
- 監督學習: 監督學習是最常用的機器學習方法之一,它的目的是從給定的訓練數據中學習出一個模型,使其能夠對新的測試數據做出預測。監督學習的兩個子類別分別為分類和回歸。分類的目的是將數據分為不同的類別,而回歸的目的是預測連續性輸出。
- 非監督學習: 非監督學習不需要預先標記的訓練數據,其目的是從數據中發現有用的結構或規律。非監督學習的兩個子類別分別為聚類和降維。聚類的目的是將數據分為不同的群體,而降維的目的是將高維數據降維成低維數據,以便更容易理解。
- 強化學習: 強化學習是一種以獎勵為導向的學習方法,其目的是訓練一個智能代理,使其能夠在某個環境中做出最佳的決策。強化學習通常用於遊戲,機器人控制等領域。
- 半監督學習:是一種介於監督學習和非監督學習之間的學習方法。它的特點是使用了一些標記數據和一些未標記數據來訓練模型。
半監督學習常用於處理大量未標記數據的問題,例如在網絡上爬取的數據。這些數據可能很難標記,但是通過半監督學習,可以利用少量有標記數據和大量未標記數據來訓練一個模型。
常見的半監督學習方法有三種:
- 基於轉換的半監督學習: 它通過在未標記數據上學習一個轉換函數,將未標記數據轉換為有標記數據來完成學習
- 基於生成模型的半監督學習:這種方法嘗試利用未標記數據的特徵來生成標記數據
- 基於協同過濾的半監督學習: 這種方法利用了數據之間的關係來對未標記的數據進行推論。
這些類型的學習可以互相結合,例如監督式學習可以與非監督式學習相結合,而強化學習也可以與監督學習或非監督學習相結合。
另外,近年來,也有越來越多的學者研究使用半監督式學習來處理大量未標記數據的問題,其中一個常見的例子是使用少量有標記數據和大量未標記數據來訓練一個模型。
選擇哪種學習類型取決於你的數據和問題。通常情況下,如果有大量標記數據,那麼監督學習是一個不錯的選擇,但如果數據沒有標記,那麼非監督學習或半監督學習可能更適合。
特徵(features) & 標籤(labels)
pip install -U scikit-learn
pip install seaborn
SKlearn官方網站範例
import sklearn
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
iris = sns.load_dataset('iris')
iris.head()
print(iris.head())
sns.set()
sns.pairplot(iris, hue='species', height=3);
plt.show()
特徵與標籤簡易範例
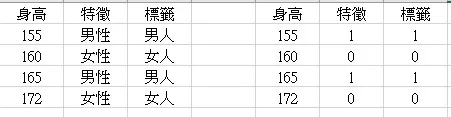
from sklearn import tree
features = [[155,1],[160,0],[165,1],[172,0]]
labels = [1,0,1,0]
clf = tree.DecisionTreeClassifier() #分類
clf = clf.fit(features,labels) #分類模型
wantPredict = clf.predict([[158,1]]) #預測
if wantPredict == [1]:
print('This is man')
elif wantPredict == [0]:
print('This is woman')
關於 Scikit-learn 可以參考 此系列文章 了解基本的機器學習
K-近鄰演算法(K Nearest Neighbor)
K-近鄰演算法(K Nearest Neighbor, KNN)是一種监督學習算法。它的工作方式是:給定一個訓練集和一個新的數據點,KNN算法會找出訓練集中與新數據點最相似的K個點,並根據這K個點的標籤對新數據點進行標籤預測。
KNN算法的缺點包括:計算量隨著數據集的增長而增大,搜索鄰近點時需要計算所有數據點之間的距離,需要計算多維空間距離。
KNN算法的應用包括: 自然語言處理, 語音識別, 圖像識別, 影像識別, 搜索引擎, 醫學診斷, 股票市場預測等.
範例
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
iris = datasets.load_iris() #載入資料
#定義特徵
iris_data = iris.data
iris_label = iris.target
print(iris_data[0:3])
#將資料拆成 訓練資料與測試資料
train_data , test_data , train_label , test_label = train_test_split(iris_data,iris_label,test_size=0.2)
#使用KNeighbors分類
knn = KNeighborsClassifier()
#訓練資料
knn.fit(train_data,train_label)
#預測資料
print(knn.predict(test_data))
#驗證資料
print(test_label)
上述主要使用了三個 Python 機器學習庫: scikit-learn, numpy,它們分別是:
- Scikit-learn(sklearn): 是 Python 中一個常用的機器學習庫,提供了許多常用的機器學習演算法和數據分析工具。
- Numpy: 是 Python 中一個常用的科學運算庫,提供了高效的數組和矩陣運算。
該程式碼使用了 scikit-learn 中的 datasets 模組載入了 iris 資料集,iris 資料集是一個鳶尾花分類的資料集,包含了 150 個樣本,每個樣本都有 4 個特徵,並且每個樣本都有一個類別標籤,本程式碼則將這些資料拆成訓練資料與測試資料。
接著,程式碼使用 scikit-learn 中的 KNeighborsClassifier 模組實例化了一個 KNN 模型 knn,並使用 fit() 方法訓練模型,使用 predict() 方法預測測試資料,最後使用 print() 方法將預測結果和實際標籤顯示出來,可以用來評估模型的準確性。
線性迴歸
線性迴歸 (Linear Regression) 是一種監督學習算法,是用來預測具有連續值的目標變量。它假設目標變量和每個解釋變量之間是线性關係。
使用 sklearn 中的 LinearRegression 的簡單流程是:
- 導入 LinearRegression 模組。
- 建立 LinearRegression 的物件。
- 使用 fit() 方法訓練模型。
- 使用 predict() 方法預測目標變量。
from sklearn.linear_model import LinearRegression
import numpy as np
#建立資料
x = np.array([1,2,3,4,5])
y = np.array([5,7,9,11,13])
#建立模型
reg = LinearRegression()
#訓練模型
reg.fit(x.reshape(-1, 1), y)
#預測
print(reg.predict([[6.0]]))
上述程式碼是一個簡單的線性迴歸模型訓練與預測範例,這範例中訓練資料包含了5筆 x, y 的資料,這些資料就是 (1,5), (2,7), (3,9), (4,11), (5,13)。 訓練好的模型再使用predict函數預測 x=6 時的 y的值。
值得注意的是,這個程式碼裡預測的結果是一個浮點數,當實際情況下,因為模型存在著誤差,所以預測出來的結果可能不是完全符合實際情況的。
在這個程式碼中,我們使用了一個簡單的線性回歸模型,並且用了 (1,5), (2,7), (3,9), (4,11), (5,13) 這五個資料點來訓練模型。
由於線性回歸是基於最小平方法來訓練模型的,它會找到一條最適合資料的直線來預測新的資料。 通過訓練得出的模型擬合出來的函數是
y = 2x + 3所以當我們輸入預測值 x = 6 時, 通過模型得出 y = 2*6+3 = 15 所以程式碼中預測出來的值為[15] .
通常線性回歸問題都不能完全匹配訓練資料集,但是模型會找到一條能夠最好地擬合訓練資料集的直線。
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
from sklearn import datasets
import numpy as np
#建立資料
x,y = datasets.make_regression(n_samples=200,n_features=1,n_targets=1,noise=10)
plt.scatter(x,y,linewidths=0.1)
plt.show()
#建立模型
reg = LinearRegression()
#訓練模型
reg.fit(x,y)
predict = reg.predict(x[:200,:])
plt.plot(x,predict,c="red")
plt.scatter(x,y)
plt.show()
#預測
print(reg.predict(np.array([6]).reshape(1,-1)))
print(reg.predict([[6]]))
支持向量機(Support Vector Machines,SVM)
支持向量機 (Support Vector Machine, SVM) 是一種監督學習算法,用於分類和回歸分析。SVM 算法中最常用的是分類算法,這種分類算法稱為支持向量分類機 (Support Vector Classification, SVC)。
SVC算法的主要思路是找出一個將資料集分成兩個類別的最佳超平面(hyperplane)。超平面是一個n-1維的平面,其中 n 是資料集的特徵數量。在二維平面中,超平面就是一條直線,在三維平面中就是一個平面。
使用 sklearn 中的 SVC 的簡單流程是:
- 導入 SVC 模組。
- 建立 SVC 的物件。
- 使用 fit() 方法訓練模型。
- 使用 predict() 方法預測目標變量。
from sklearn.svm import SVC
#建立資料
x = [[1,2], [3,4], [5,6], [7,8]]
y = [0,1,1,0]
#建立模型
clf = SVC()
#訓練模型
clf.fit(x, y)
#預測
print(clf.predict([[6,7]]))
上面的程式碼是一個簡單的SVC分類模型訓練與預測的範例。在程式碼中,我們使用了訓練資料 x 和 y 進行訓練,x 是特徵資料,y 是類別標籤。最後,使用 predict() 方法預測輸入資料[6,7]對應的類別。
SVC 模型在分類時使用了核函數(Kernel),預設是 Radial basis function (RBF),但是也可以自訂核函數。
在這個程式中,使用了 [1,2], [3,4], [5,6], [7,8] 以及 [0,1,1,0] 的訓練數據來訓練 SVC 模型。在這個簡單的例子中,這個模型已經被訓練出來,並且應用到預測 [6,7] 這個新數據時。 根據我們給定的訓練數據,模型已經知道了每個類別的分布,所以當我們將新數據餵入預測時,模型就可以預測出這個數據對應的類別,在這個例子中,[6,7]對應的類別是0。
SVC特徵標準化 範例
from sklearn import preprocessing #特徵標準化
import numpy as np
from sklearn.model_selection import train_test_split #cross_validation 舊版 新版用model_selection
from sklearn.datasets import make_classification
from sklearn.svm import SVC
import matplotlib.pyplot as plt
#產生 300筆資料,2個特徵,random_state用來保證每次生成的數據集相同。
x,y = make_classification(n_samples=300,n_features=2,n_redundant=0,n_informative=2,
random_state=3,scale=100,n_clusters_per_class=1)
plt.scatter(x[:,0],x[:,1],c=y)
plt.show()
#SVC分類進行訓練
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2)
clf = SVC()
clf.fit(x_train,y_train)
print(clf.score(x_test,y_test))
#標準化
x = preprocessing.scale(x)
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2)
clf = SVC()
clf.fit(x_train,y_train)
print(clf.score(x_test,y_test))
這程式中主要的作用是使用 sklearn 中的 SVC 分類模型訓練與測試。在程式的前半部分,我們使用 make_classification 產生 300 筆資料,2 個特徵,並且使用 scatter plot 畫出資料點。之後我們將資料分為訓練資料和測試資料,使用 SVC 進行訓練並且使用 clf.score() 計算測試準確率。
接著我們對資料進行標準化(Standardization),並且重新訓練模型,測試結果顯示出在標準化後的資料上,分類器的表現有了改善。 標準化是將資料轉換成01的範圍,或是-11的範圍,使得每個特徵的統計量都變成0,方差為1。
因為 SVM 這種演算法會受到特徵值範圍的影響,所以對於原本範圍差異較大的資料進行標準化,可以改善模型的表現。
這段程式碼主要是展示了標準化的重要性,當我們對資料進行標準化後,模型的表現更加穩定,準確率也有提升,所以在實際應用上,我們應該注意到這一點,對資料進行適當的標準化。
更多 關於 SVM 可參照 Support Vector Machines
K-Fold Cross Validation 交叉驗證
K-Fold Cross Validation and GridSearchCV in Scikit-Learn
K-Fold Cross Validation 是一種用來驗證模型準確率的方法,它透過把資料分成 k 份,每次選取其中一份作為驗證資料,其餘 k-1 份則作為訓練資料,重複 k 次,取平均值以獲得最終的模型準確率。這樣做有幾個好處:
- 每個資料都被當作驗證資料使用過一次,可以確保資料都有被使用到。
- 透過取平均值來解決資料分布不均的問題,避免overfitting
- 可以更精確的估計模型的準確率。
在使用scikit-learn 中可以使用KFold 來進行K-fold Cross Validation ,並可以設置 k 值。
範例
from sklearn import datasets
from sklearn.model_selection import KFold
from sklearn.svm import SVC
iris = datasets.load_iris()
X = iris.data
y = iris.target
kf = KFold(n_splits=5)
for train_index, test_index in kf.split(X):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
clf = SVC()
clf.fit(X_train, y_train)
print(clf.score(X_test, y_test))
這程式主要是使用 K-Fold Cross Validation 對 SVM 模型進行訓練和驗證。
1.首先將 iris 資料讀入並將特徵資料存入 X 變數、標籤資料存入 y 變數。
2.使用 KFold(n_splits=5) 建立 K-Fold 物件,並將數據分成 5 組。
3.使用 for 迴圈對於每組數據執行訓練與驗證。
4.將訓練資料與測試資料分別存入 X_train, y_train, X_test, y_test 變數中。
5.使用 SVC() 建立 SVM 模型並進行訓練,訓練完後,使用 score() 方法驗證模型的準確率。
6.最後,將每次驗證的準確率印出。
這段程式中使用了 K-Fold Cross Validation 來對 SVM 模型進行訓練和驗證,將資料分成 5 組,每次將一組資料當作驗證資料,其餘的 4 組資料當作訓練資料,並印出每次的準確率。
範例
from sklearn.model_selection import cross_val_score
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
import matplotlib.pyplot as plt
iris = datasets.load_iris()
X = iris.data
y = iris.target
knn = KNeighborsClassifier(n_neighbors=10)
scores = cross_val_score(knn,X,y,cv=5,scoring='accuracy')
print(scores)
print(scores.mean())
k_range = range(1,31)
k_scores = []
for k_number in k_range:
knn = KNeighborsClassifier(n_neighbors=k_number)
scores = cross_val_score(knn,X,y,cv=10,scoring='accuracy')
k_scores.append(scores.mean())
plt.plot(k_range,k_scores)
plt.xlabel('Value of K for KNN')
plt.ylabel('Cross-Validated Accuracy')
plt.show()
這程式主要是在使用 K-近鄰演算法 (K-NN) 對 iris 資料進行分類,並利用 K-fold Cross Validation 來驗證模型的準確率。
1.首先將 iris 資料讀入並將特徵資料存入 X 變數、標籤資料存入 y 變數。
2.以 KNeighborsClassifier(n_neighbors=10) 建立分類模型,並用 cross_val_score() 函數進行 K-fold Cross Validation,cv 參數設定為 5,並指定 scoring 為 accuracy,代表我們是以準確率來驗證模型。
3.印出 scores 和 scores.mean(),scores 為每次驗證模型的準確率結果, scores.mean() 為所有次驗證的準確率平均值。
4.建立一個 k_range 變數,並將 1~30 的值存入,然後用迴圈對每個 k_number 依序執行訓練與驗證。
在迴圈中,使用 KNeighborsClassifier(n_neighbors=k_number) 建立新的模型,再次使用 cross_val_score() 進行 K-fold Cross Validation,cv 參數設定為 10,將每次驗證的準確率平均值存入 k_scores 陣列。
5.最後將 k_range 和 k_scores 用 Matplotlib 繪製成圖形,並標記 x 軸、y 軸的標籤。
在整個程式中,第一次使用 k = 10 做模型,第二次則是將 k 的值從1到30,每一個 k 跑一次實驗,看哪個 k 值會得到最高的準確率。透過繪製圖形可以看到隨著k值增加,準確率是在提高的,但也有提高的幅度有所限制,隨著k值持續增加,準確率並不會有太大的提升
這段程式中使用了 K-fold Cross Validation 來驗證模型的準確率,並在不同的 k 值下,找出最佳的 k 值。
儲存模型
pip install joblib
範例
from sklearn import datasets
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
import joblib
iris = datasets.load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# 訓練模型
clf = LogisticRegression()
clf.fit(X_train, y_train)
# 儲存模型
joblib.dump(clf, 'model.joblib')
# 載入模型
loaded_model = joblib.load('model.joblib')
print(loaded_model.score(X_test, y_test))
了解 基本的演算法後
可參閱 NLP自然語言處理 介紹
另外 此篇 也可以 快速看一下了解基本的概念
參閱此三篇文章後,讓我們繼續往下學習~
卷積神經網路 (CNN)
import tensorflow as tf
from tensorflow import keras
# 建立模型
model = keras.Sequential()
model.add(keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)))
model.add(keras.layers.MaxPooling2D((2, 2)))
model.add(keras.layers.Conv2D(64, (3, 3), activation='relu'))
model.add(keras.layers.MaxPooling2D((2, 2)))
model.add(keras.layers.Conv2D(64, (3, 3), activation='relu'))
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(64, activation='relu'))
model.add(keras.layers.Dense(10, activation='softmax'))
# 編譯模型
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 載入 CIFAR-10 資料集
(x_train, y_train), (x_test, y_test) = keras.datasets.cifar10.load_data()
x_train = x_train / 255.0
x_test = x_test / 255.0
# 訓練模型
model.fit(x_train, y_train, epochs=10, validation_split=0.1)
# 評估模型
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=2)
print(test_acc)
這個範例使用的是 CIFAR-10 資料集,其中包含 32x32 彩色圖像,並且每張圖像有 10 個類別。建立一個由三個卷積層和兩個全連接層組成的模型,然後使用 CIFAR-10 資料集訓練並評估模型。本範例僅提供示範性質,在實際應用時還需要調整各種參數,例如層數、激活函數、損失函數、訓練輪數等,以獲得最佳的模型性能。您還可以將這個模型修改為更複雜的架構,例如加入更多的卷積層和全連接層,或者使用預訓練模型,以提高準確率。
實際運用可參照 從零開始學AI圖型辨識(基礎篇)
使用keras那節透過模型判斷手寫數字辨識

























