
前言
今天要來講的,是如何使用Stable Diffusion來製作角色設定圖。
在一兩個月之前,要製作角色設定圖這種多面向且高度一致的人物圖,除了用Textual Inversion或者LoRA之外,還有用ControlNet的方法,經過了好幾次的嘗試之後,我找出了一個最穩定出圖,且步驟最少的方法。這個方法主要是運用了簡單的ControlNet openpose功能,以及Inpaint來製作。不需要用到Textual Inversion或者LoRA。
第一步,配合骨架圖出圖
首先,在txt2img裏面,使用這樣的正面提示詞:
(character sheet of the same exact Vallaria wearing black beret with golden rim and intricate [white|golden] robe and black cloak),
(((white background))), (((simple studio background))), reference sheet,
((fantasy)), ((kind smiling)), real face, real skin, realistic face, realistic skin, detailed eyes, detailed facial features, detailed clothes features, detailed face and breast, beautiful eyes, detailed eyes, perfect body, perfect breasts, perfect face,
(best quality, masterpiece), (realistic), photorealistic, RAW photo
<lora:VallariaV2:0.35>
第一段是交代人物的基本構造,在這例我使用自製的人物LoRA配合特定衣飾,然後用character sheet of the same exact當開頭,讓AI知道我們要繪製的是角色設定稿。
第二段交代AI使用簡單的白背景與工作室背景,免得AI畫出太多背景,干擾設定稿的質感。
第三四段添加許多修飾詞來提高整體氛圍與質感,例如我用高權重指定奇幻風,並且人物要微笑。
之後是最重要的一步,請打開ControlNet,使用Openpose,並使用繪畫人物設定稿專用的骨架圖。網路上有很多骨架圖,我使用的是這幾張:

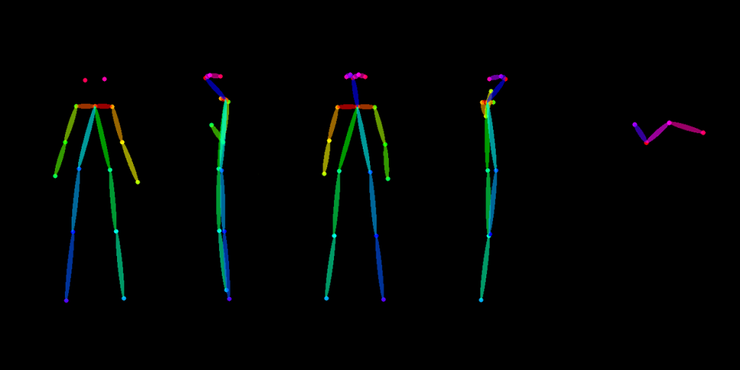

通常第一張的尺寸我會設定為1024X512 (二比一),這樣算圖才快,能夠一次產個十幾張不同的圖讓我挑選最滿意的圖進行下一步:

我以這張圖來進行下一步:

第二步,放大並修臉
這張圖,右邊半身像的表情與服裝正是我要的,但是左邊的角色旋轉圖問題很大,第一是臉整個都崩了,看了晚上都要做惡夢了。第二個是最左邊的角色圖,帽子長了角。
臉崩的問題主要是因為我們使用的模組,通常是專精於產生漂亮半身像與頭像,例如我使用的RealDosMix,對於全身圖、動作圖等圖不熟,AI很容易算到臉崩或肢體崩,此時我們就需要針對這些部位修圖。
首先,將第一步的圖用send to img2img這個按鈕送進img2img,然後將他擴展最少50%。以我的例子,就是擴展到1536X768,這樣AI才能在之後的步驟修臉。而Reszie mode選擇Just resize。
Just resize(latent upscale)這個選項放大出來的圖會糊掉,但是也會產生一種朦朧美,看個人需求。
另外,別忘了把txt2img的ControlNet設定也重複在這邊設定一次,否則擴圖之後人物姿勢可能會跑掉。

圖片成功放大之後,請按Send to inpaint,將圖送進部分重繪。
在這邊,要將人物崩掉的臉與出錯的服飾圈選起來:

接著將inpaint的參數設定好:
- Mask content選擇original,告訴AI其實我要的結果跟原圖差不多,這樣出來的臉才會跟整體畫風契合。
- Inpaint area選擇Only masked。如果選成Whole picture,最後臉還是會崩掉。
- Denoising strength選擇低於0.5,太高人物的頭可能會歪掉。

至於為什麼Inpaint area要選擇Only masked,這是因為這樣等於告訴AI,被選取的區域是要注重的地方,AI會將你選取的區域放大,針對放大區域重繪之後,再縮小並合併回原圖。這時你善於繪製頭像與半身像的模組就能發揮特長了。
當圖輸出之後,如果有跟原畫不協調的部分,可以將成果圖再輸入回img2img,然後用低Denoising strength再輸出一次,就能得到更一致的結果:

最後
現在已經有了很多方法可以大量隨機生成角色,配上上面第一步設定,就能大量做出人物設計圖,讓PM與美工在角色生成與溝通這環節省下大量時間,限制角色的因素,只剩下顯卡效能與電費還有設定提示詞的創意了。
下面就是一個生成大量隨機角色的方法(從13:20處開始):
享受AI算圖的快樂吧!
進階技巧目錄:
- Stable Diffusion進階 -- 製作角色設定圖
- Stable Diffusion進階 -- 轉換線稿/漫畫稿
- Stable Diffusion進階 -- 常用網站
- Stable Diffusion進階 -- CLIP Skip 2
- Stable Diffusion進階 -- 臉崩修復
- Stable Diffusion進階 -- X/Y/Z plot
- Stable Diffusion進階 -- 提示詞矩陣
- Stable Diffusion進階 -- 練習,歡迎來到我的家鄉
- Stable Diffusion進階 -- 穿衣換衣術
- Stable Diffusion進階 -- 醒來!表情變換
- Stable Diffusion進階 -- 雷光變幻!
- Stable Diffusion進階 -- 糊臉清晰化
- Stable Diffusion進階 -- 練習,這是利息
- Stable Diffusion進階 -- 人工與工人智慧去背
- Stable Diffusion進階 -- 手部修復
- Stable Diffusion進階 -- ControlNet新功能Reference



















