前言

這次來分享這個作品的製作過程。
像公主抱這種姿勢, 對於Stable Diffusion來說其實異常困難。最主要是因為這個姿勢牽涉兩個人,肢體是互相重疊在一起,而且很多地方都會露出手與手指。更別提通常這是男抱女,兩種不同性別的人物的貼身互動。於是SD會有非常大的機率變成女抱男或肢體混成一團,更別提同時出現好幾隻手或身體腰斬的恐怖情況。而如果是要將兩個人物LoRA同時用在這個圖上,更增加AI算圖的難度。
通常現行SD在處理同畫面多人不同LoRA時,用的技巧是Composable LoRA加上Latent Couple的手段:
但是,這種做法用在人物肢體交錯的圖時,就超出了它的處理能力:

可以很明顯看到,中間的男性切分了左右畫面,女性橫貫在中間將男性分成兩半,同時男性的左手又扶在女性的後腰上,變成一塊孤島。
我曾經試過用Latent Couple畫出這種複雜度的切分圖,結果產生出來的圖非常、非常、非常慘烈。
這次就要來挑戰使用LoRA,ControlNet,inpaint加上img2img來完成這個作品。
生成半成品
首先,因為這張圖牽涉到兩個人物LoRA,我們不能直接使用提示詞加上LoRA來算圖,這樣會得到陰陽人雙胞胎,所以要先從不使用LoRA的草圖來做。
感謝 Fly Angel 同好的提點,其實Stable Diffusion可以很好地理解人類的自然語言,甚至在故意不加上太多負面提示詞的情況,有些模型可以生出非常絢麗的效果。我在這邊就使用了GhostMix加上描述人物與動作的半自然語言,一次產生一百張圖片,從中挑選一張可用的草圖:
(extremely detailed CG unity 8k wallpaper), best quality, masterpiece , hdr, ultra highres,
one strong man with blonde hair and long hair and wearing white tunic carry a girl on his arms,
the girl has long black hair and wearing white kimono and grey cloak and short red skirt and black knee boots,
the background is a landscape of mountains and forest

在這裡我故意不用各種精修臉部、身材眼睛等特徵的提示詞,要不然在這個步驟加入太多這類強調頭部與上半身的提示詞,會讓AI算不出我需要的人物動作,因為這些提示詞會搶走了AI的注意力。
可以看到,這邊男性與女性的頭髮顏色剛好與我要的相反,手部也有扭曲,臉部更是不及格。但這就是一個很好的起點了。
算圖的第一步,先把Inpaint設置好:
- Masked content: original
- Inpaint area: Only masked
- Denoising strength: 0.75
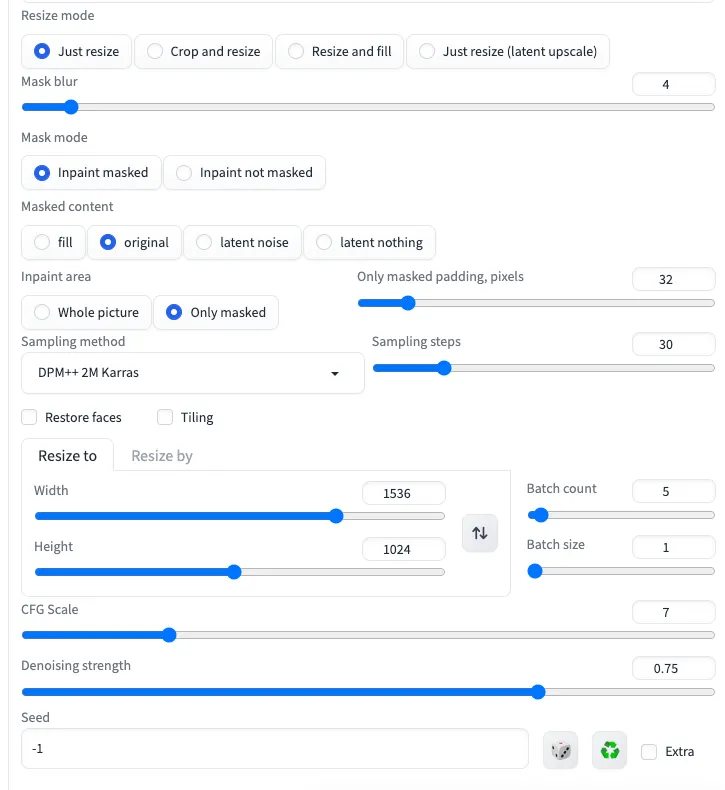
由於0.75的Denoising strength非常高,如果沒有另外的限制,重算出來的人物跟姿勢一定會與草圖相差非常多,這時候我們就要用ControlNet來限制:
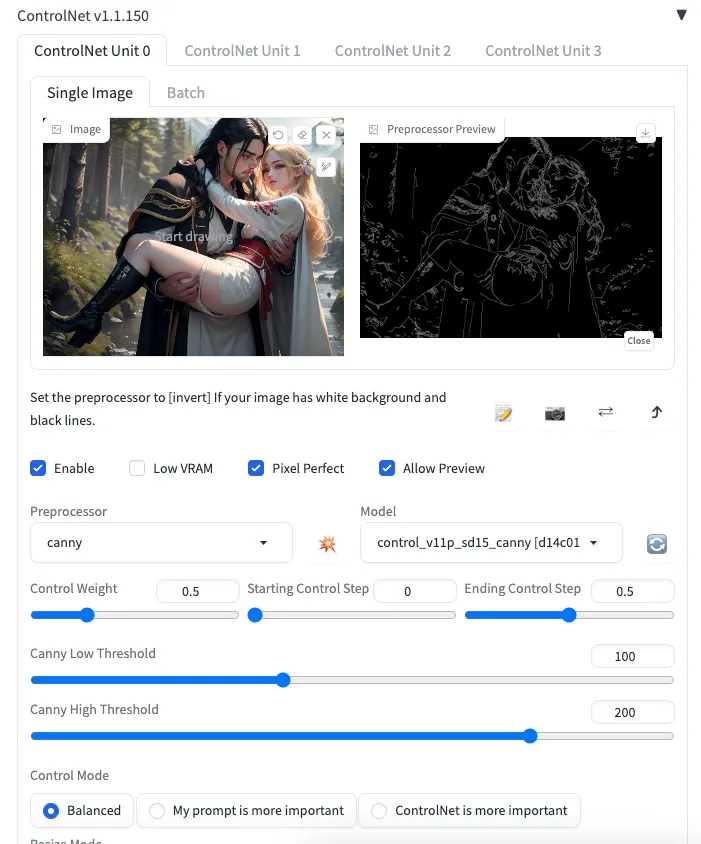
在第一個ControlNet設定中使用canny。但因為canny會強烈限制住線條,這樣人物出來的長相也不會趨向我LoRA想畫的人物,所以要選擇低權重0.5,並且設定Ending Control Step在0.5,這樣跑到一半時就能放手給LoRA繪製人臉與身體特徵。
在這邊不使用openpose的原因在於,這張圖的人體交纏太過複雜,openpose只會判斷出一團毛線球而已。
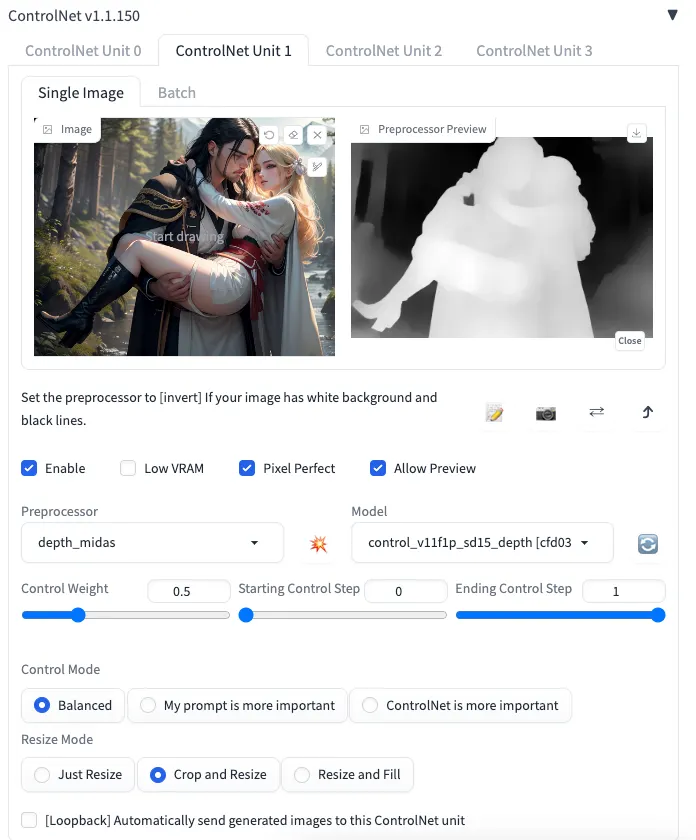
第二組ControlNet使用depth。depth的功用不只是限制人物的外觀輪廓,同時也提供了物體的立體資訊,可以讓AI算圖時知道哪個肢體是更靠近鏡頭,哪個在後方,這樣重繪出來的人物肢體才不會破碎。但同時又維持0.5的權重,讓AI有機會調整人物的細微部份,尤其是五官的立體形狀。
這些基本設定完成後,我要先從一個角色開始變形,這次就先從女角開始。
用inpaint選取女角之後,將正負面提示詞都換上該角色專用的完整提示詞:
(extremely detailed CG unity 8k wallpaper), best quality, masterpiece , hdr, ultra highres, real face, real skin, realistic face, realistic skin, detailed eyes, detailed facial features, detailed clothes features, detailed face, beautiful eyes, detailed eyes, perfect body, perfect face,
Hana with black long hair and blunt bangs and white kimono and red short skirt and white cloak and black knee boots
<lora:Hana:0.4>
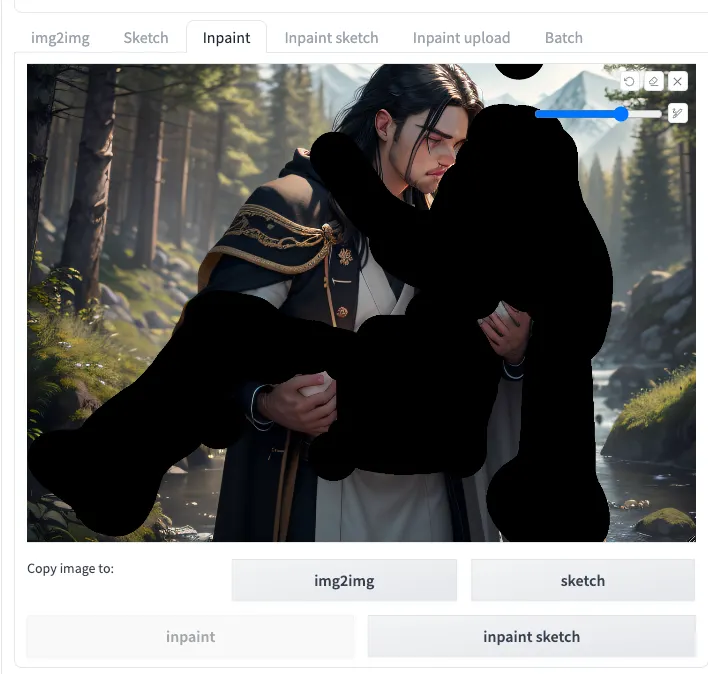
提示詞內包含了各種精細繪製臉龐,體型,眼睛的正面提示詞,這樣AI才會知道該努力畫臉了。
女角畫完之後檢查,如果不像,可以試著調高LoRA權重,或者成品圖直接輸入inpaint再強化一次。
確定女角夠像之後,接著改選男角,並將提示詞換成男角專用提示詞:
(extremely detailed CG unity 8k wallpaper), best quality, masterpiece , hdr, ultra highres, real face, real skin, realistic face, realistic skin, detailed eyes, detailed facial features, detailed clothes features, detailed face,
XingBar the strong man with blonde long hair and stubble and wearing grey tunic and grey cloak carrying a girl on his arm
<lora:XingBar:0.4>
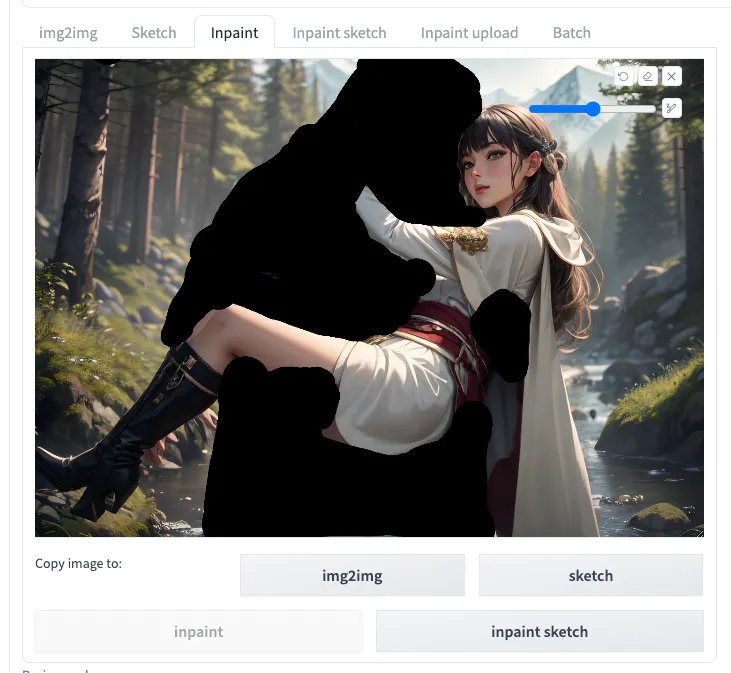
依照一樣的步驟,等確認男角也夠像之後,再來考慮精細修改。
精修半成品

這時半成品還有很多地方要修正,第一個是明顯扭曲的左手,第二個是高跟的靴子(沒有正常人在荒野冒險還穿這種超高跟靴子!),第三個是人物的臉不夠美觀,表情也不對。
這時需要將問題個別解決,首先要把ControlNet停用,因為整張圖的構圖差不多固定了,不需要再控制免得阻礙。
- 手的部分,用Inpaint圈選之後用自然語言敘述正面提示詞:left hand of a strong man holding the back of a girl,Denoising strength權重開到0.75。並且跑個十二張圖拼運氣,找出可以接受的成果。
- 鞋子的部分,我使用了圖片編輯軟體GIMP將鞋跟修掉,用Inpaint選取之後再用正面提示詞:black flat knee high boots,Denoising strength權重開到0.75跑了十張圖,挑選自己喜歡的。
- 人臉的部分,我將模型切換成我習慣使用於擬真型人物的RealDosMix,將人臉選取起來後用Denoising strength權重0.2到0.3重複算圖,利用漸進算圖法的精神,遇到偏離目標的臉就捨棄,算到更接近目標的就再拿來當作新的輸入。重複到滿意為止。
當整張圖的細節都完成之後,再用img2img配上ControlNet Tile Resample,利用 Stable Diffusion進階 -- 糊臉清晰化 提到的方法打磨整張圖的光影與色彩偏差。然後再用 Stable Diffusion進階 -- 臉崩修復 提到的4x-UltraSharp放大兩倍,提高畫質。
就這樣,一張表情與長相符合我想像,姿勢標準的公主抱圖片就完成了!
祝大家AI算圖愉快!
進階技巧目錄:
- Stable Diffusion進階 -- 製作角色設定圖
- Stable Diffusion進階 -- 轉換線稿/漫畫稿
- Stable Diffusion進階 -- 常用網站
- Stable Diffusion進階 -- CLIP Skip 2
- Stable Diffusion進階 -- 臉崩修復
- Stable Diffusion進階 -- X/Y/Z plot
- Stable Diffusion進階 -- 提示詞矩陣
- Stable Diffusion進階 -- 練習,歡迎來到我的家鄉
- Stable Diffusion進階 -- 穿衣換衣術
- Stable Diffusion進階 -- 醒來!表情變換
- Stable Diffusion進階 -- 雷光變幻!
- Stable Diffusion進階 -- 糊臉清晰化
- Stable Diffusion進階 -- 練習,這是利息
- Stable Diffusion進階 -- 人工與工人智慧去背
- Stable Diffusion進階 -- 手部修復
- Stable Diffusion進階 -- ControlNet新功能Reference


























