
本文長2080字,回答幾個問題:
(一) 什麼叫做湧現;(二)湧現是什麼現象;(三)為什麼我們造不出自己的超級 AI。看完後,你會理解現在 AI 的現象跟趨勢、一些技術與專有名詞,像是參數、大型機構與他們模型的名字。
---------正文開始---------
前陣子準備演講時,找到一份Google與史丹佛大學做的有趣研究,講到 AI 的湧現 (Emergent Ability)。
AI 領域的湧現現象,展現在機器突破某個臨界值之後,變得格外強大,運算系統產生很多難以理解的現象或反應,使得我們感覺機器彷彿有著人的智慧。
|湧現與模型的超凡表現
臨界值又是以甚麼為判準呢?這份研究中提到 AI 的湧現,出現在「大模型」之上。大模型可以從運算量、訓練資料量或參數量而言。而該論文著墨在參數量。參數量意味著模型的複雜度與性能。
而下圖展現不同的大型語言模型,在不同任務上的表現。
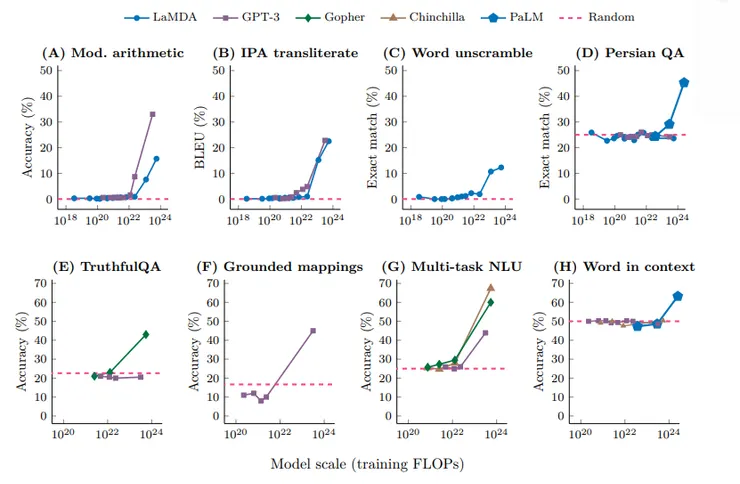
每張圖 X 軸都是運算量的衡量單位,量級越大,對應的模型參數量也就越多。Y軸則是衡量模型表現的指標。這些任務涵蓋算數、國際音標轉換、拼字、外語Q&A 以及概念的映射/對應等等。
這裡面的模型不乏有像 GPT3 (ChatGPT的前身) 、或是Google的LaMDA,這種當今眾人都多少耳聞的模型。
不約而同地,模型的參數量在達到一個門檻,看起來是10的22至23次方的FLOPs,也就是100億到700億範圍的參數量,模型的表現會顯著飛升,機器的表現也會越加強大成熟。
反之,若未能突破此門檻,模型的表現大多在隨機水準中徘徊。這樣的機器,你可能不會覺得他是聰明可用,或甚至是有智能的。
GPT3.5,也就是ChatGPT目前的通用版本,參數是1750億,參數量已經超標了。這也是為何他能夠表現的這麼不凡的其中一個原因。
|來看看聰明的人工智慧,是如何表現的
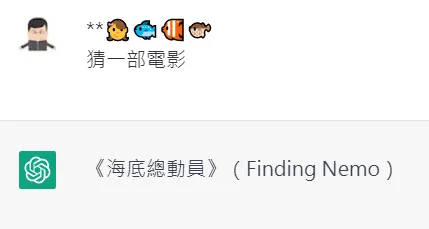
聰明的人工智慧挺多的,有研究者實驗,他們給 ChatGPT 一串表情符號
**👧🐟🐠🐡
讓他猜一部電影。
你們猜的到嗎?我是滿頭問號啦,但 AI 可以準確猜中答案:「海底總動員」。我去試了一下,真的可以。奇怪,他明明連文字都沒有。
李宏毅教授的課程也提到類似的現象 (以下連結影片42分52秒處開始)。該範例讓機器做文字轉語音,也就是讓機器發聲。輸入內容是「發財發財發財發財」,四次發財。
結果呢,唸四次發財,後面兩次的發財竟然出現了抑揚頓挫。照理來講不是應該用一樣的聲調,把發財唸完四次嗎?經測試,如果只發兩次發財,則不會有此現象。
至於為何會這樣呢?不知道。這種「我明明沒有教你啊,你怎麼會」的緊張感,就是湧現帶給我們的壓力。
|我們造的出湧現的 AI 模型嗎?
關於這個問題,答案是不太容易。
為了讓大家感受一下百億參數,我來講個人技術操作好了。
兩年多前我在防疫旅館隔離,閒來沒事就玩了一下神經網路 (Neural Network) 模型。下面簡略敘述一下技術名詞 (細節設定請看我有點混亂的Github程式碼)。當時,我使用了1995 ~ 1997年三年的 SP500 資料,其實沒有很多,784筆而已哦。訓練了一個設計非常樸素的模型 (一個隱藏層的雙向長短期記憶模型)。
這個模型──配上給定的訓練資料和參數設定,總共只有 13萬3377 個參數。

如果對於「參數」的技術有興趣,歡迎到以下影片看解說 (47分30秒左右開始),這是我們的 AI 社團 (歡迎加入!!) 的講座,講者是藍星球資訊科技的宋浩總經理──從2023年三月中起我們每週都請業界賢達演講。
工商結束。
再補充個事件吧,前陣子Facebook (Meta) 公司的大語言模型 Llama 外流,也引起許多討論。我直覺疑問是,誰跑得動那個模型呢?不論你是要直接拿來用或是要做維護,跑得起模型是最基本的。
Llama 也同 ChatGPT,是一個巨無霸模型,其複雜規模外加訓練所用的資料量,誰能否跑得動都很成問題。
這也反映一個現實,就是我們基本上是沒有能力,創建一個自己的大型語言模型的。這是運算能力的問題、這是軟體硬體的問題,這也是錢的問題。
在大機構面前,我們多無能為力呢?具體一點,有一次和主管同事去吃飯,閒聊到語言模型的話題。
當時有人說,Google 在 2018 年做出來的 BERT 模型,這是一個沒有ChatGPT那麼大那麼通用的模型,全世界能跑得動那個模型並且重現 Google 結果的,也不到 10 家組織或機構。
差距就在那,東西都送給你,你也不一定玩得起來。
|造物者的奇妙設計:湧現
湧現不只在 AI 的參數量,湧現也不只是AI 給我們的困惑與恐懼。湧現在世界各地也很普遍。開場提到的論文,引述了諾貝爾物理學獎得主 Anderson 的話:
Emergence is when quantitative changes in a system result in qualitative changes in behavior
就是我中國的朋友們很愛說的一句話:「量變產生質變」。
也就是一個系統中的數量單位達到一定的量,他就會產生一種全新的行為和能力。這些單位也許個別相當簡單、功能不多,但是經由互相的影響,一種全新的狀態就產生了。
這種現象出現在很多地方。
像是以個體來說,每個人都有自己的情感跟想法;但在聚集之中就產生了社會的規範和文化。
在金融上,我6年前寫了金融海嘯的系列文 (首篇) 也談到一個負面的湧現:經年累月的個別系統問題,帶來整個金融的崩壞。
像是證券化──把所有貸款變成許多全新可交易的產品,再來是亂給信用評等導致大家混亂的信用評價機構;最後是狂印鈔票的聯準會。
這三個各自為政的元素,經年累月下來就湊成了一個完美風暴。沒有人希望事情變糟,每個人都按照古典經濟學中理性自利的方向前進,最終卻造成了沒有人可以預測的打擊。
沒錯,不可預測或是難以解釋,就是湧現的力量。
湧現不是元素疊加而成,而是交互 (correlate)。因此很難從單一個元素或層面,就了解湧現這種整個系統的變化。
這篇寫到這好像也有點長了,下次有機會來聊聊以 AI 為例怎麼分析/理解湧現。還有在湧現力量驅使下的AI世界,我們會/應當如何。這題應該很好玩,哈。

























