本篇要解決的問題
以往一場會議、訪問、議程,如果需要逐字稿,都需要人類手打出來(August 接過這工作),自從 OpenAI 的 Whisper API 問世後,才知道語音辨識的工作也可以讓 AI 來執行。
原本 August 是有私下製作一頁,讓自己還有朋友使用,但因為接 API 是要 $$ 的,因此就沒在本站釋出。直到去年底 Whisper 推出了 Large V3 後,才知道,哎呀,原來是開源的耶!開源的意思就是,如果本機硬體夠強,可以把 model 載下來,直接在作本機作語音辨識,不用付費就能使用 Whisper API。
但因為 August 的電腦不夠強,而且也不想直接就在本機安裝 Python,在同事的分享下,才知道 Google 有一個 Colab 的功能,讓我們這種路人也可以在上面寫 Python,一定使用量下都是免費的,Google 的說明是:
Colab (全名為「Colaboratory」) 可讓你在瀏覽器中編寫及執行Python 程式碼,並具有以下優點:. 不必進行任何設定; 免付費使用GPU; 輕鬆共用.
既然有這麼好的工具,你各位還不刷起來~
本篇會示範怎麼使用 Google Colab + Whisper Large V3,來執行語音辨識。
更新:這幾天又發現了辨識速度更快,且更精準的 Faster Whisper,看完本篇後,請記得繼續閱讀〈免費開源的語音辨識功能:Google Colab + Faster Whisper〉。
Google Colab 設定為 GPU
其實這點也不用寫,但為了湊字數還是寫一下。
點擊 Colab 網址:https://colab.research.google.com/?hl=zh-tw,就會進入到 Colab 中,預設看到的畫面是這樣:
Google Colab 首頁
Colab 的檔案都會存到 Google 雲端硬碟上,點擊「新增記事本」,會看到以下畫面:
點擊執行階段
我們這一步是為了開啟 Colab 的 GPU,所以新增了記事本後,先點擊上方選單的「執行階段」->「變更執行階段類型」,在硬體加速器的選項上,就可以選擇 GPU:
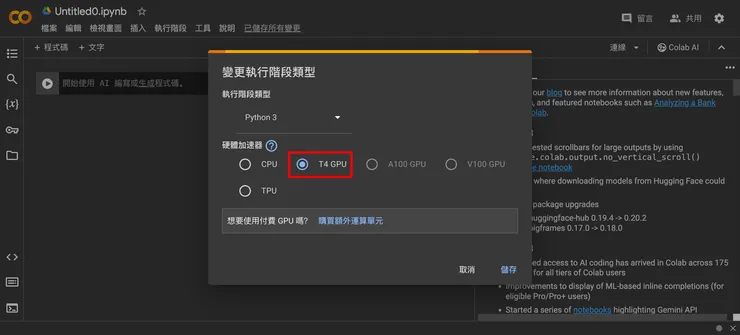
硬體加速器改為 GPU
使用 Whisper Large V3 功能
以下程式碼的程式語言是 Python,而且是簡單使用的版本。
首先,先安裝 Whisper:
!pip install git+https://github.com/openai/whisper.git
接著按下程式碼區塊,左邊有著播放 Icon 的按鈕,就會執行安裝:
按下執行儲存格
執行完後,會看到很多的輸出訊息,點擊程式碼區塊那個垂直的 … 按鈕,再選擇「清除輸出內容」,就可以清掉:
清除輸出內容
剛剛的那行是安裝 Whisper,接下來點擊上面的「+程式碼」,在新增程式碼編輯區塊,貼上執行語音辨識的程式碼,如下:
import whisper
import os
from google.colab import files
# 載入模型
model = whisper.load_model("medium") # tiny, base, small, medium, large, large-v2, large-v3
# 設定檔案路徑
audio_path = "letswrite.mp3" # 替換成你的檔案名稱
# 處理音頻檔案,指定繁體中文
result = model.transcribe(audio_path, prompt="請轉錄以下繁體中文的內容:")
# 印出結果
print(result["text"])
# 獲取不帶副檔名的檔案名稱
file_name = os.path.splitext(os.path.basename(audio_path))[0]
# 將結果保存為txt檔案
with open(f"{file_name}.txt", "w") as file:
file.write(result["text"])
files.download(f"{file_name}.txt")
這段程式碼,包含了使用 Whisper 作語音辨識,以及辨識成文字後會自動下載為 .txt 的檔案。
看到這篇的各位,複製貼上程式碼後,要改的地方有 2 個。
載入模型
第 6 行的:
model = whisper.load_model("medium")
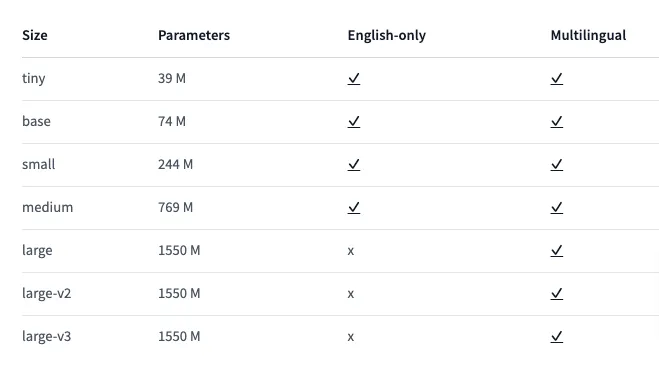
參數量愈小,檔案就小,辨識速度也快,但是辨識的精準度就不高;反過來說,參數量愈大,檔案就愈大,辨識速度慢,但結果會更精準。
「English-only」如果有打勾,代表辨識英文的會比較精準,其它語系就沒這麼精準。
August 實際使用的結果,medium 的結果就很足夠了,而且比較會是繁體中文的版本。
large 辨識的結果會是最好的沒錯,但耗費的時間長很多,而且中文的部份很常會出現簡體中文。
要用哪個 model 來執行辨識,就看大家各自的需求。
檔案路徑
第 9 行,就是要選擇要辨識的檔案。
Google Colab 是 Google 的產品,所以可以直接使用 Google 雲端硬碟的檔案。
如果要使用雲端碟碟檔案,先點擊最左側那個資料夾的 Icon,再點擊有 Google 雲端硬碟 Icon 的按鈕,就會自動載入檔案進來:
使用雲端硬碟檔案
這邊示範直接從電腦本機上傳檔案就好,就不用再另行提供授權,我們改點擊上傳檔案的 Icon:
點擊上傳本機檔案的按鈕
選好本機檔案後,就會上傳上來。
選好檔案後,會看到一個提示訊息:
提示檔案是暫時性存在的
Google Colab 是一個免費工具,所以不會 24 小時無時無刻是 ON 的狀態,不然大家就會把它當免費主機來使用了。
所以當執行階段結束,所有傳上來的檔案都會被刪除。下次重新開啟檔案時,所有的程式碼也要重新執行。
上傳好檔案後,對著檔案點右鍵:
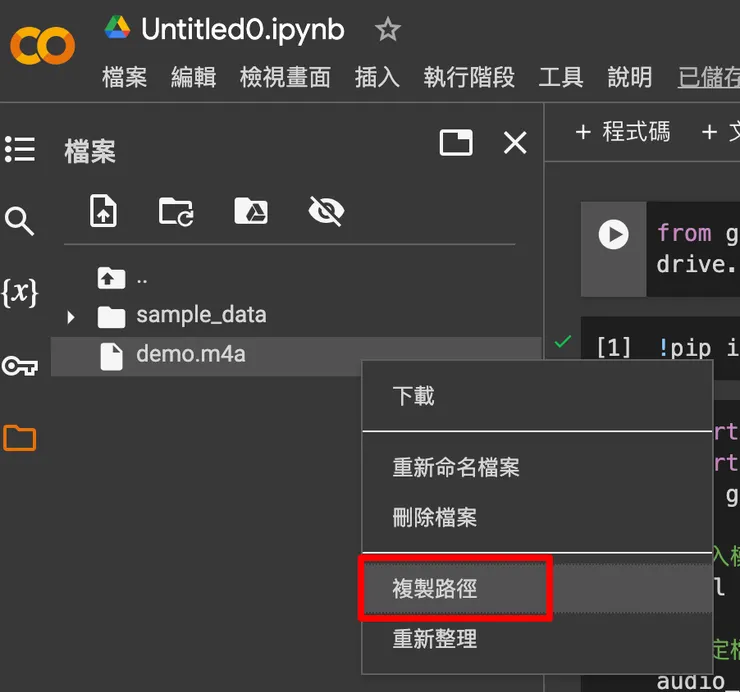
複製路徑
點擊「複製路徑」,再貼到第 9 行的 audio_path,Colab 就會知道要辨識的檔案是哪一個。
執行辨識
選好了 model,更新了檔案路徑,一樣點擊左側播放樣式的 Icon,Colab 就會執行程式碼,讓 Whisper 幫我們辨識我們的檔案。
辨識結果如下圖:
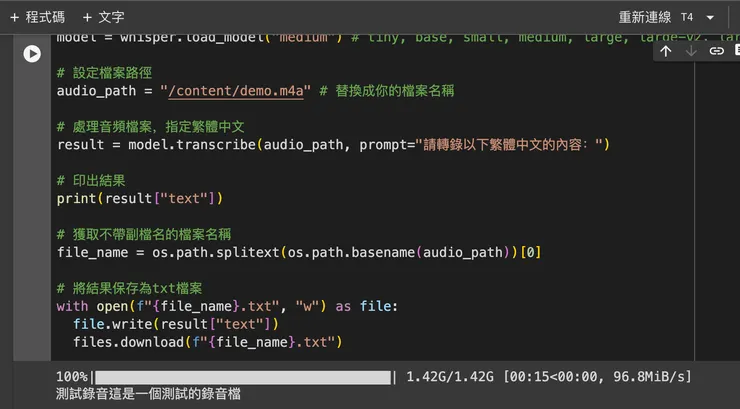
辨識結果
第一步會先載入指定的 model,接著執行辨識。
辨識完後,也會自動下載一份結果的 .txt 檔案。
語音辨識是不會加上標點符號、分段的,需要的話,就是複製結果文字後,丟給 ChatGPT 去加標點、改錯字、分段囉。
以上,就是本篇開源、免費的語音辨識功能。






















