我們在輝達 nVidia Jetson Orin Nano 的裝置上,可以透過 PyToch 以及 CUDA 來使得反饋類神經網路的運算,不透過 CPU 而交由 GPU 來作運算執行;它與原來在 CPU 上執行 PyTorch 的反饋類神經網路的撰寫程式差異不大,這也是我們使用 PyTorch 的好處;絕大部份在 GPU 的平行運算的工作,都由 PyTorch 來解決掉了,程式撰寫只需要專注在程式邏輯的開發。
在同時有 CPU 及 GPU 的運算上,因為所有的人機界面;包括文字輸出入、檔案輸出入以及繪圖,都是直接由 CPU 來負責,而 GPU 只能執行數值計算的部份。因此在使用 CUDA 作 GPU 的運算時,就必須要將資料以及變數在 CPU 及 GPU 之間搬移;這樣才能有效地使用 CUDA/GPU 加速運算的好處。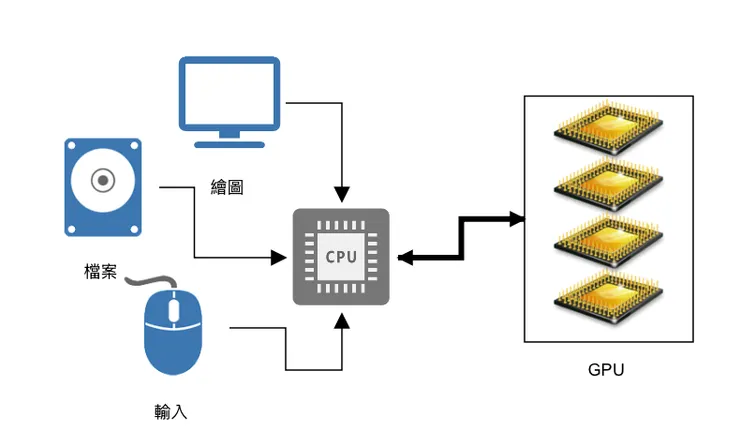
- 模型學習目標
首先,我們還是先以「墨西帽」的模型作為例子來作說明。
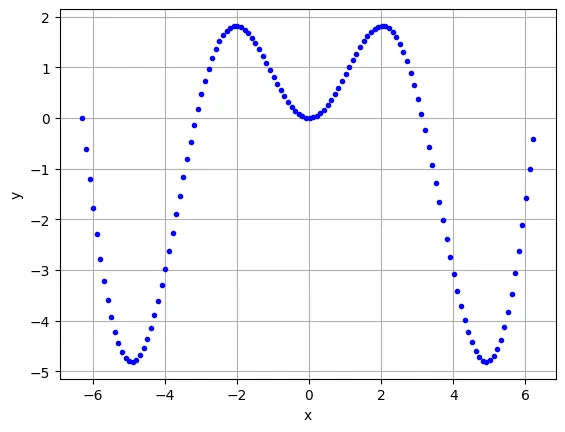
import numpy as np
import matplotlib.pyplot as plt
x=np.arange(-2*np.pi,2*np.pi,0.1)
y=np.sin(x)*x
plt.xlabel('x')
plt.ylabel('y')
plt.plot(x,y,'b.')
plt.grid()
plt.show()
- 建立類神經網路類別
再來按照原來在 CPU 環境上,同樣建立類神經網路類別;這一部份也沒有改變。
import torch
from torch import nn
class classNeural(nn.Module):
def __init__(self,n_input,n_hidden,n_output):
super().__init__()
self.n_input=n_input
self.n_hidden=n_hidden
self.n_output=n_output
#--------
self.layer1=nn.Linear(n_input,n_hidden)
self.layer2=nn.Linear(n_hidden,n_output)
self.active=nn.Sigmoid()
#--------
def forward(self,x):
x=self.active(self.layer1(x))
return self.layer2(x)
- 確認 CUDA/GPU 裝置準備完備
接下來必需要詢問 PyTorch,目前的裝置是否支援 CUDA 的 GPU 運算。
device=torch.device('cpu')
if torch.cuda.is_available():
device=torch.device('cuda')
- 資料搬移到 GPU
然後,我們要把訓練資料透過「to(‘cuda’)」這個函數,將資料從 CPU 搬到 GPU 上。
X_train=torch.tensor(x.astype('float32')).unsqueeze(dim=1).to(device)
Y_train=torch.tensor(y.astype('float32')).unsqueeze(dim=1).to(device)
- 類神經網路搬移到 GPU
再來,創建類神經網路變數,並且透過「to(‘cuda’)」,將類神經網路也搬到 GPU 上。
torch.manual_seed(13)
neural=classNeural(1,10,1).to(device)
- 在 GPU 進行類神經網路訓練
一般來說,最花費運算時間及資源的,就是訓練類神經網路,也是最需要使用 GPU 的部份;這一段程式的寫法其實與在 CPU 上的寫法是一樣的,但是因為訓練資料以及類神經網路變數都在 GPU 上,所以整個運算也就會在 GPU 上面執行。
neural.train()
n_epoche=5000
mae_x=[]
mae_y=[]
for epoche in range(n_epoche):
Y_pred=neural(X_train)
loss=loss_fn(Y_pred,Y_train)
optimizer.zero_grad()
loss.backward()
optimizer.step()
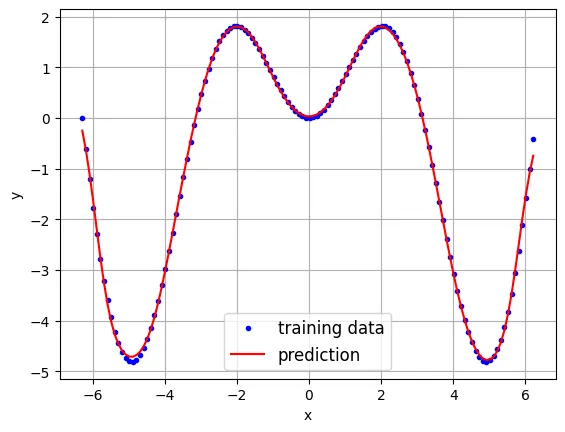
- 輸出在 GPU 訓練好的模型的預測數值
最後,在輸出訓練好的類神經網路模型的預測值的時候,要注意所有的輸出到人機界面的數值,包括文字顯示或繪圖或檔案的資料,都必須要透過函數「to(‘cpu’)」由 GPU 搬到 CPU 上,才能進行。
neural.eval()
with torch.inference_mode():
Y_pred=neural(X_train)
y_pred=Y_pred.to("cpu").numpy()
#—————————————————
plt.plot(x,y,'b.',label='training data')
plt.plot(x,y_pred,'r-',label='prediction')
plt.grid()
plt.legend(fontsize=12)
plt.xlabel('x')
plt.ylabel('y')
plt.show()
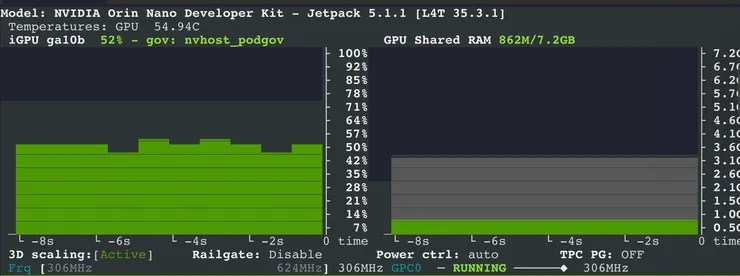
- 觀察並確認類神經網路在 GPU 上運算
在執行類神經網路訓練時,我們可以同時透過 Jetson Orin Nano 的「jtop」指令,觀察在 Jetson Orin Nano 裝置上 GPU 的執行狀態,可以確認主要的計算都在 GPU 上面執行。