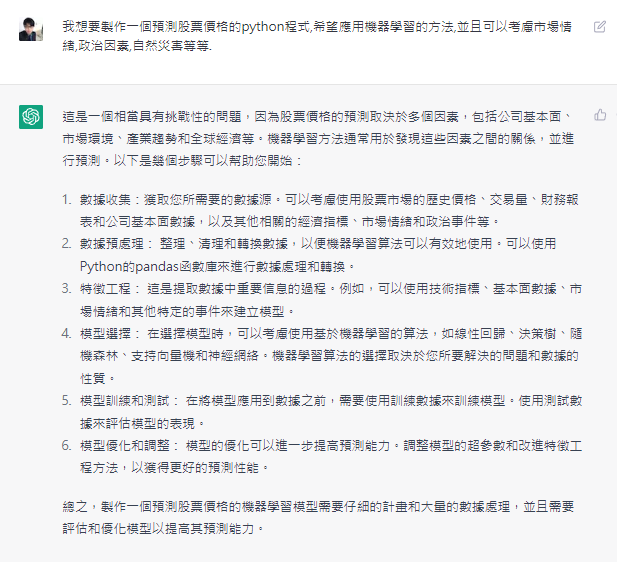
好的看他說得一口像資料科學家一樣我就照著她說的做
好的取得完數據之後我們照他說得考慮政治因素市場情緒

import yfinance as yfok他給了我VIX波動率指數和美國總統就職日期
import pandas as pd
import numpy as np
import datetime as dt
import requests
# 設定要取得的股票代碼和時間範圍
ticker = "AAPL"
start_date = dt.datetime(2016, 1, 1)
end_date = dt.datetime(2021, 12, 31)
# 使用 yfinance 取得股票價格資料
df = yf.download(ticker, start=start_date, end=end_date)
# 新增其他相關數據欄位
# 市場情緒:VIX波動率指數
vix_url = "https://fred.stlouisfed.org/graph/fredgraph.csv?id=VIXCLS"
vix_df = pd.read_csv(vix_url, index_col=0, parse_dates=True)
df = pd.merge(df, vix_df, how='left', left_index=True, right_index=True)
# 政治因素:美國總統就職日期
inauguration_dates = {
'Trump': '2017-01-20',
'Biden': '2021-01-20'
}
df['Inauguration'] = np.nan
for president, date in inauguration_dates.items():
inauguration = pd.to_datetime(date)
df['Inauguration'][df.index >= inauguration] = president
# 移除缺失值
df = df.dropna()
# 儲存處理後的資料
df.to_csv('stock_data.csv')
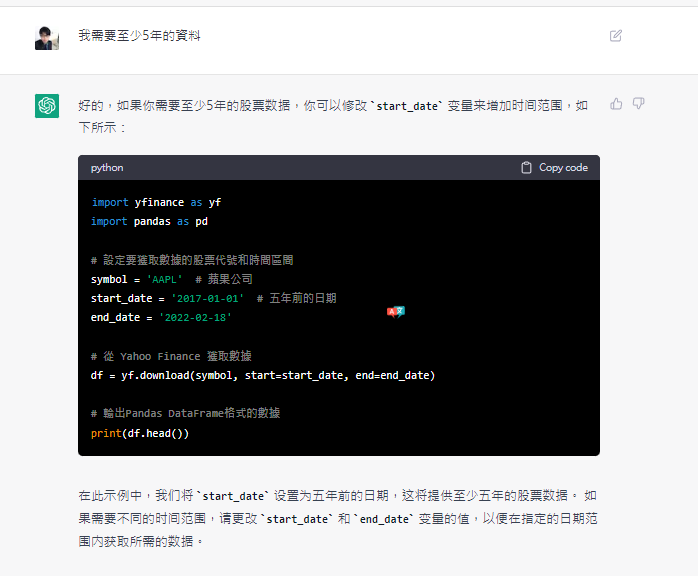
再來看看他能不能幫忙做特徵轉換和特徵工程

import pandas as pd
from sklearn.preprocessing import StandardScaler
# 讀取資料
df = pd.read_csv('stock_data.csv', index_col=0)
# 將 Inauguration 欄位做 label encoding
df['Inauguration'] = df['Inauguration'].map({'Trump': 0, 'Biden': 1})
# 計算收盤價的一階差分
df['Close_diff'] = df['Adj Close'].diff()
# 計算 VIX 的 5 日移動平均值
df['VIX_5MA'] = df['VIXCLS'].rolling(window=5).mean()
# 將數據標準化
scaler = StandardScaler()
df_scaled = pd.DataFrame(scaler.fit_transform(df), index=df.index, columns=df.columns)
# 計算收盤價的未來一天差分
df_scaled['Close_diff_shifted'] = df_scaled['Close_diff'].shift(-1)
# 刪除最後一列缺失值
df_scaled = df_scaled[:-1]
# 儲存處理後的資料
df_scaled.to_csv('processed_data.csv')
看起來不錯他對數據轉換,標準化,encoding都會
還算了一下收盤價的一階差分當作特徵工程項
不過過程中其實有些許錯誤我自己跳下去修改了一下之後
把整段代碼貼上補一句問他
import pandas as pd
import numpy as np
from sklearn.preprocessing import MinMaxScaler
from keras.models import Sequential
from keras.layers import Dense, LSTM, Dropout
# 讀取資料
df = pd.read_csv('processed_data.csv', index_col=0)
# 分割訓練集和測試集
train_size = int(len(df) * 0.7)
train_data = df.iloc[:train_size, :]
test_data = df.iloc[train_size:, :]
# 標準化數據
scaler = MinMaxScaler()
train_data_scaled = scaler.fit_transform(train_data)
test_data_scaled = scaler.transform(test_data)
# 設定時間窗口大小
window_size = 30
# 創建 X_train 和 y_train
X_train, y_train = [], []
for i in range(window_size, len(train_data_scaled)):
X_train.append(train_data_scaled[i-window_size:i, :])
y_train.append(train_data_scaled[i, -2])
X_train, y_train = np.array(X_train), np.array(y_train)
# 創建 LSTM 模型
model = Sequential()
model.add(LSTM(units=50, return_sequences=True, input_shape=(X_train.shape[1], X_train.shape[2])))
model.add(Dropout(0.2))
model.add(LSTM(units=50, return_sequences=True))
model.add(Dropout(0.2))
model.add(LSTM(units=50))
model.add(Dropout(0.2))
model.add(Dense(units=1))
# 編譯模型
model.compile(optimizer='adam', loss='mean_squared_error')
# 訓練模型
model.fit(X_train, y_train, epochs=50, batch_size=32)
# 預測未來的股價
inputs = df.iloc[len(df)-len(test_data)-window_size:, :].values
inputs = scaler.transform(inputs)
X_test = []
for i in range(window_size, len(inputs)):
X_test.append(inputs[i-window_size:i, :])
X_test = np.array(X_test)
predicted_price = model.predict(X_test)
predicted_price = scaler.inverse_transform(predicted_price)
# 視覺化結果
import matplotlib.pyplot as plt
plt.plot(test_data['Adj Close'].values, color='red', label='Actual Price')
plt.plot(predicted_price, color='blue', label='Predicted Price')
plt.title('Stock Price Prediction')
plt.xlabel('Time')
plt.ylabel('Stock Price')
plt.legend()
plt.show()
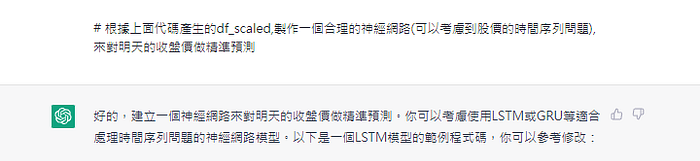
到這邊就出現問題了
y_train.append(train_data_scaled[i, -2])#不是我要預測的 y 收盤價欄位
for i in range(window_size, len(train_data_scaled)):
X_train.append(train_data_scaled[i-window_size:i, :])
#這一段也很怪應該改成
for i in range(0, len(inputs)-window_size):
X_train.append(train_data_scaled[i:i+window_size, :])
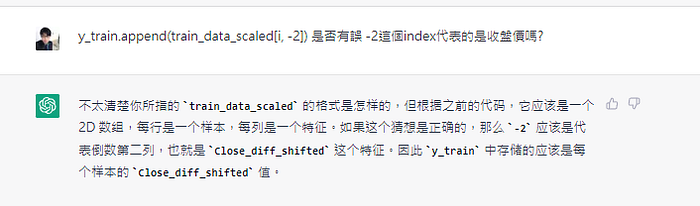
看來他搞混了我的預測目標是明天收盤價,而不是收盤價的差分
大概做到這邊就極限了他開始胡言亂語
後面出現神經網路內部架構的錯誤
好吧我只能親手動手來了,不過他倒是提供了一個很好的藍圖
最終結果算是我跟chatgpt協作的成果
import yfinance as yf
import pandas as pd
import numpy as np
import datetime as dt
import requests
from textblob import TextBlob
from sklearn.preprocessing import LabelEncoder
# 設定要取得的股票代碼和時間範圍
ticker = "AAPL"
start_date = dt.datetime(2013, 1, 18)
end_date = dt.datetime(2023, 2, 18)
# 使用 yfinance 取得股票價格資料
df = yf.download(ticker, start=start_date, end=end_date)
# 新增其他相關數據欄位
# 市場情緒:VIX波動率指數
vix_url = "https://fred.stlouisfed.org/graph/fredgraph.csv?id=VIXCLS"
vix_df = pd.read_csv(vix_url, index_col=0, parse_dates=True)
df = pd.merge(df, vix_df, how='left', left_index=True, right_index=True)
# 政治因素:美國總統就職日期
inauguration_dates = {
'Trump': '2017-01-20',
'Biden': '2021-01-20'
}
df['Inauguration'] = np.nan
for president, date in inauguration_dates.items():
inauguration = pd.to_datetime(date)
df['Inauguration'][df.index >= inauguration] = president
le = LabelEncoder()
df['Inauguration'] = le.fit_transform(df['Inauguration'].astype(str))
# 儲存處理後的資料
df.to_csv('stock_data.csv')
import pandas as pd
from sklearn.preprocessing import StandardScaler
# 讀取資料
df = pd.read_csv('stock_data.csv', index_col=0)
# 計算收盤價的一階差分
df['Close_diff'] = df['Adj Close'].diff()
# 計算 VIX 的 5 日移動平均值
df['VIX_5MA'] = df['VIXCLS'].rolling(window=5).mean()
# 計算收盤價的未來一天差分
df['Close_diff_shifted'] = df['Close_diff'].shift(-1)
# 計算未來一天收盤價
df['Close_Tomorrow'] = df['Close'].shift(-1)
df = df.dropna()
df_processed = df
# 儲存處理後的資料
df_processed.to_csv('processed_data.csv')
import pandas as pd
import numpy as np
from sklearn.preprocessing import MinMaxScaler
from keras.models import Sequential
from keras.layers import Dense, LSTM, Dropout
# 讀取資料
df = pd.read_csv('processed_data.csv', index_col=0)
# 分割訓練集和測試集
train_size = int(len(df) * 0.7)
train_data = df.iloc[:train_size, :]
test_data = df.iloc[train_size:, :]
# 標準化數據
scaler = MinMaxScaler()
train_data_scaled = scaler.fit_transform(train_data)
test_data_scaled = scaler.transform(test_data)
# y各自做特徵縮放
y_max = df['Close_Tomorrow'].max()
y_min = df['Close_Tomorrow'].min()
train_data_scaled[:,-1] = (train_data['Close_Tomorrow'].values-y_min)/(y_max-y_min)
test_data_scaled[:,-1] = (test_data['Close_Tomorrow'].values-y_min)/(y_max-y_min)
def inverse_transform_y(y):
y *= (y_max-y_min)
y += y_min
return y
# 設定時間窗口大小
window_size = 30
# 創建 X_train 和 y_train
X_train, y_train = [], []
for i in range(0,len(train_data_scaled)-window_size):
X_train.append(train_data_scaled[i:i+window_size, :])
y_train.append(train_data_scaled[i+window_size, -1])
X_train, y_train = np.array(X_train), np.array(y_train)
# 創建 LSTM 模型
model = Sequential()
model.add(LSTM(units=50, return_sequences=True, input_shape=(X_train.shape[1], X_train.shape[2])))
model.add(Dropout(0.2))
model.add(LSTM(units=50, return_sequences=True))
model.add(Dropout(0.2))
model.add(LSTM(units=50))
model.add(Dense(units=1))
# 編譯模型
model.compile(optimizer='adam', loss='mean_squared_error')
# 訓練模型
model.fit(X_train, y_train, epochs=10, batch_size=32)
# 預測未來的股價
inputs = df.iloc[len(df)-len(test_data)-window_size:, :].values
inputs = scaler.transform(inputs)
X_test = []
for i in range(window_size, len(inputs)):
X_test.append(inputs[i-window_size:i, :])
X_test = np.array(X_test)
train_predicted_price = inverse_transform_y(model.predict(X_train))
test_predicted_price = inverse_transform_y(model.predict(X_test))
# 視覺化結果
import matplotlib.pyplot as plt
plt.plot(train_data['Close_Tomorrow'].values, color='red', label='Actual Price(train)')
plt.plot(train_predicted_price, color='blue', label='Predicted Price(train)')
plt.title('Stock Price Prediction')
plt.xlabel('Time')
plt.ylabel('Stock Price')
plt.legend()
plt.show()
plt.plot(test_data['Close_Tomorrow'].values, color='red', label='Actual Price(test)')
plt.plot(test_predicted_price, color='blue', label='Predicted Price(test)')
plt.title('Stock Price Prediction')
plt.xlabel('Time')
plt.ylabel('Stock Price')
plt.legend()
plt.show()
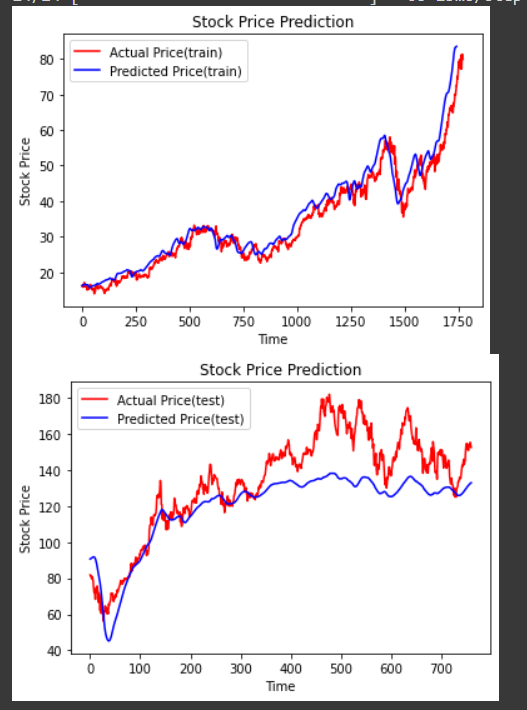
這就是照著chatgpt的思路(考量政治因素市場情緒)搞出的一個股價預測模型
大概在前幾年就看過許多人這樣搞這種LSTM然後抓股價開高收低量
這種文章在網路上滿天飛
CHATGPT可能在訓練資料集有看過相關的文章
唯一有幫助的是我要他製作一些市場情緒政治因素的特徵
說真的我還真的不會做,他還知道要去哪個URL撈市場情緒:VIX波動率指數
# 市場情緒:VIX波動率指數
vix_url = "https://fred.stlouisfed.org/graph/fredgraph.csv?id=VIXCLS"
vix_df = pd.read_csv(vix_url, index_col=0, parse_dates=True)
df = pd.merge(df, vix_df, how='left', left_index=True, right_index=True)
如果是chatgpt出來以前的時代大概要花一些時間google才找到的
什麼是市場情緒特徵,然後理解什麼是VIX指標,之後再研究怎麼用python下載
和現有程式做整合而CHATGPT出來後只要問他他馬上可以把
VIX指標的URL給出來並自動merge到df裡當作一項特徵,算是很大的幫助
最後來看一下表現:
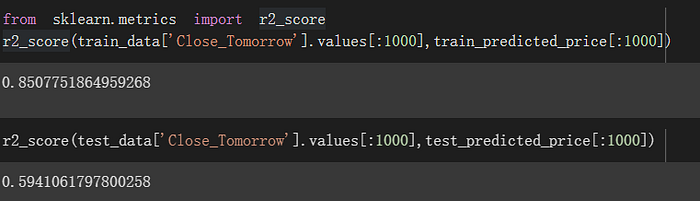
test r2_score 0.59 左右看來有點準但又不是太準,但是方向抓得出來
總結
我可以看到chatgpt是一個超級強大的助手,特別是對於像我這樣的內容創作者。過去身為一個工程師我常常為一篇文章編寫大量代碼,但在這篇文章中,我的工作量其實減少許多。大部份代碼都由chatgpt完成,確實是一個不錯的工具
感謝您的閱讀,希望您喜歡這篇文章!
如果您想要來支持我的內容創作那麼您可以用
PayPal
請我喝杯咖啡讓我更有創作的熱情跟動力🙂





















