我不是程式設計師,是以藝術創作的角度撰寫心得。
先說結論:
演算Img2Img時,Sampling methods(取樣方法)中Karras類型比較忠於原圖,非Karras類型比較放飛自我。

*也有使用其他的演算模組嘗試,但這兩部分的實現程度也都差不多。
以下演算成果的所有設定都相同,更動的只有Sampling method:
cyriousmix_14.safetensors
Sampling steps 30
Denoising strength 0.3
CFG Scale 12
Width 500 x Height 700
Batch count 1
Batch size 1
Seed 2910326828
+Prompts
masterpiece, best quality, 2girls, twins, blue shirt, white dress, bare shoulders, white pants, khaki pants, purple eyes, blue eyes, red hair, gold hair, multicolored eyes, multicolored hairs, red hair with gold highlights, gold hair with red highlights, purple eyes with blue tint, blue eyes with gold tint, smile
-Prompts
(painting by bad-artist-anime:0.9), (painting by bad-artist:0.9), watermark, text, error, blurry, jpeg artifacts, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, artist name, (worst quality, low quality:1.4), (bad anatomy), nsfw, (extra fingers), (bad fingers), extra sleeves, red letter, extra letters,
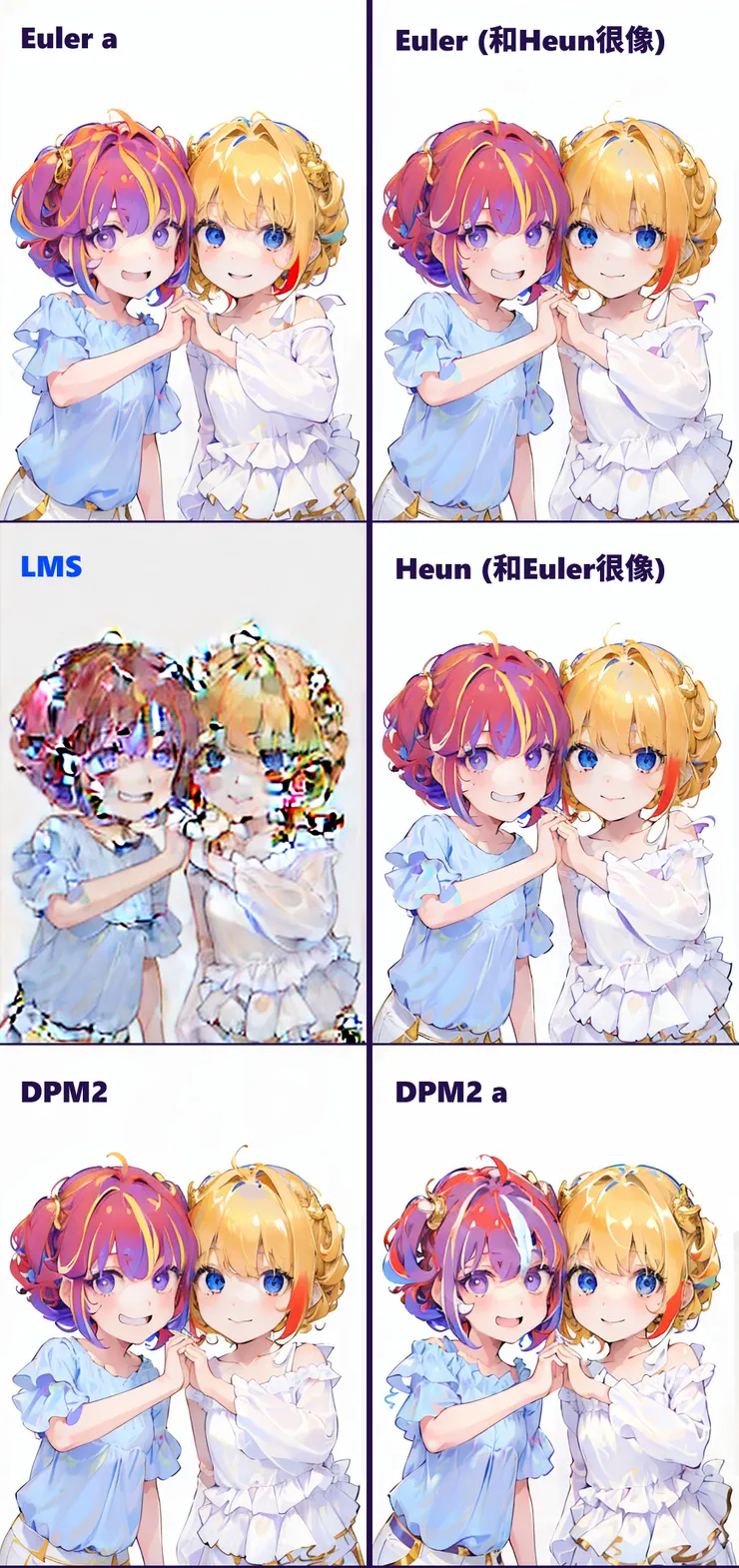
Euler和Heun的演算結果我「完全看不出」差異。LMS則是一如既往地不適合動漫風格的演算模組,抑或是需要很大量的sampling steps?

DPM fast大概是用來快速判斷結果的演算法。

撇開比較特殊的LMS和DPM fast不談,可以很明顯地看出名字中有「Karras」的取樣方法在同樣的設定下(特別是相同的Sampling steps、Denoising strength、CFG Scale、Seed),其演算結果是比較「忠於」原圖的。
盡管如此,以下問題是所有演算法都有的:
- 所有取樣方法均「無法正確算出雙色瞳」的效果,儘管原圖和+prompts中都有提供。
- 「紅髮挑金」所有的取樣方法都有算出來,然而「金髮挑紅」非Karras的取樣方法都只有鬢角變紅,而Karras系列與其說是有算出來,不如說是因為比較忠於原圖而保留下來的,但DPM2 Karras和DPM2 a Karras仍然沒有保留下來。
- 手指的問題很大--雖然幾乎所有的演算模組都有手指的問題,但CyriousMix是手指問題非常明顯的一種,偏偏我又很喜歡它的風格,未來可能需要靠Control Net來解決了。
為何頭髮的顏色會影響演算的結果,個人認為是用於訓練的作品中,挑染其他顏色的紅髮比較常見,但挑染其他顏色的金髮卻很少見的緣故。
換言之,可說是AI因為人類「偏好」而產生「歧視」的例子?
下圖是我實際選用的版本。這個版本的+Prompts我忘了保存下來,但我記得也是換了很多次Seed才有金髮挑紅的成果出現,而且+Prompts應該有額外添加「two-tone hair」的關鍵詞。

我原本的生圖目的是更新線上連載小說的封面,下圖是手動調整過後的最終成果:























