Google推出AI聊天機器人Gemini加入生成圖像的功能,基於Imagen 2模型的圖像生成,讓使用者可以輸入文字描述,讓Google Gemini 生成相對應圖片。
Google秉持 AI 原則,圖像生成功能也是以負責任的方式進行開發設計。例如,為了確保 Gemini 生成的圖像,可以和原創藝術家的作品有明顯區別,Gemini 會使用 SynthID 工具,在生成圖像的像素中,嵌入數位可識別的浮水印來協助區別。以下是我使用Google Gemini來生成及辨識圖像例子
生成圖片
只要輸入提示詞,就會生成相對應的圖片
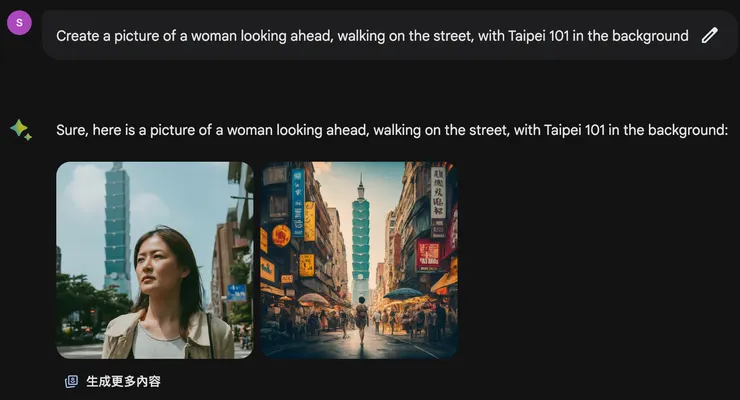
在Google Gemini輸入英文提示詞生成圖像
點擊「生成更多內容」會再生成兩張圖像,最多生成四張
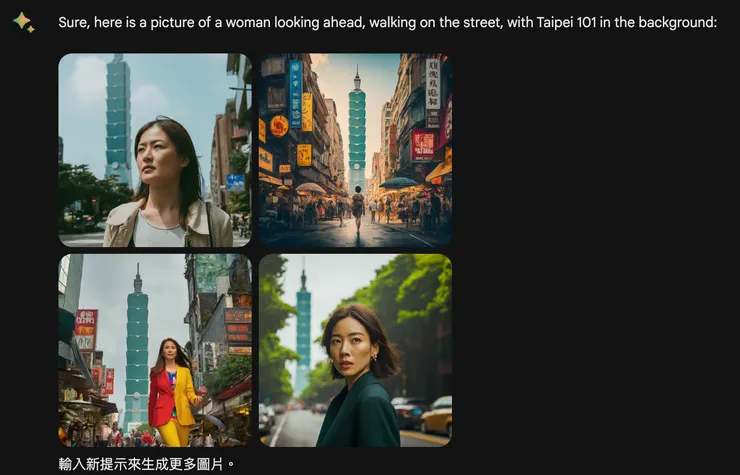
點擊「生成更多內容」生成更多圖像
點擊圖片放大,可以下載圖片,圖片尺寸為512 x 512

Google Gemini 生成圖像尺寸512 x512
也可以生成不同風格的照片,這邊生成吉卜力風格的圖像及貼紙

Google Gemini 生成吉卜力風格圖像
Google Gemini 生成貼紙圖像
目前只支援使用英文描述生成圖片,如果你使用中文提示詞,系統會提示無法生成圖像。
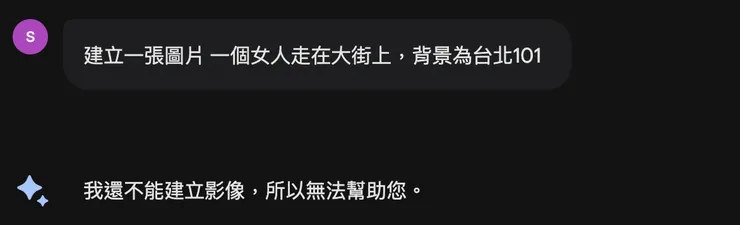
Google Gemini無法使用中文生成圖像
描述圖片
以下是在Google Gemini分別上傳不同圖片風格及內容的描述
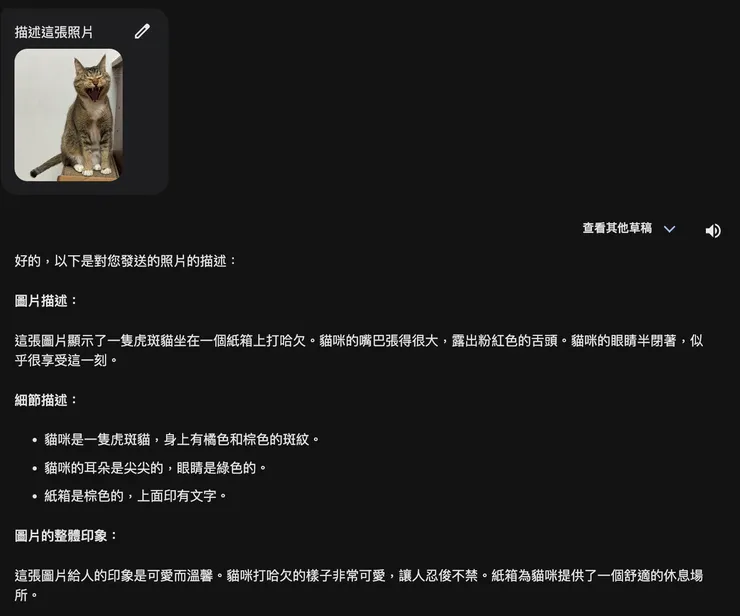
Google Gemini描述貓咪圖片
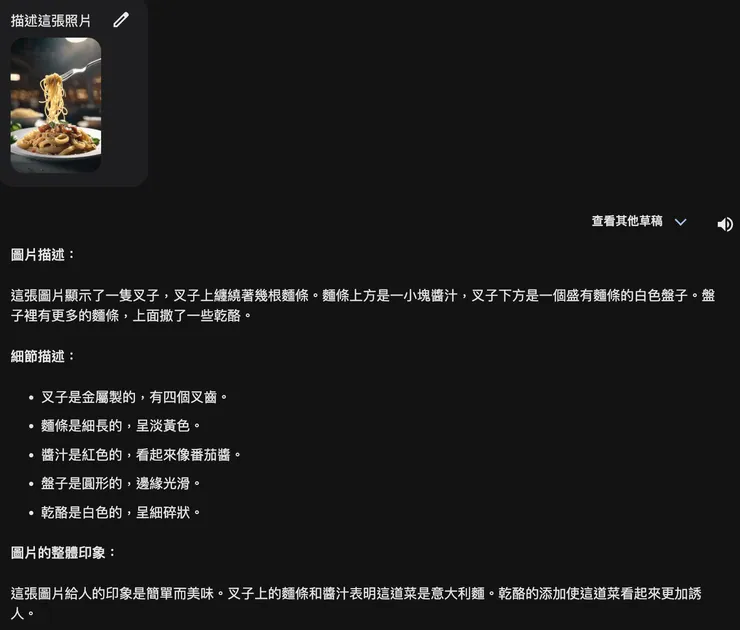
Google Gemini描述美食攝影圖片

Google Gemini描述向量圖片
在描述的部分,準確度我覺得一半一半,對於人像的部分無論是卡通或真實風格,只要有人臉,Google Bard都無法處理

Google Gemini 無法描述人像圖片
總結
我使用Google Gemini生成及描述圖像的功能進行了測試,效果還不錯,Gemini 能夠生成符合描述的圖像,且圖像的畫質清晰、色彩鮮豔,但在使用下來,有幾個小缺點:
- 目前 Gemini 生成圖像的功能僅支援英文提示詞
- 無法生成及辨識人像圖像
- 辨識圖片功能在辨識圖片方面存在一定的誤差
我認為Google Gemini生成圖像的功能具有一定的潛力,該功能能夠生成逼真且符合描述的圖像,相信未來會更完善。
Google 也有獨立的免費生成高品質的圖像生成工具「ImageFX」,有興趣的也可以前往文章看看唷!
Google 在 2/8 將 Bard 聊天機器人命名為 Gemini
部分資料來源:Gemini
























